
什么是数据仓库和数据挖掘
已发表: 2018-02-22企业数据存储在与其他数据存储库物理分离的信息孤岛中,每个孤岛都服务于专门的功能——但那是在大数据席卷世界之前(如果我们可以说是一场风暴)。 现在,在如此大的数据集上实践相同的方法几乎是不可能的。 试想一下,它需要从这么多物理上分离的信息孤岛中提取数据的数量——只需要运行一个简单的查询。 这一切都要归功于组织和大数据工程方法中的大量数据。
让我们密切关注数据仓库和数据挖掘如何进入现场。 开发了数据仓库来解决数据存储的这个问题。 从本质上讲,数据仓库可以被认为是一个统一的数据存储库,这些数据来自各种来源并采用各种格式。 另一方面,数据挖掘是从所述数据仓库中提取知识的过程。
在本文中,我们将详细介绍数据仓库和数据挖掘。 为了更好地理解,我们将文章结构如下:
- 什么是数据仓库?
- 数据仓库流程
- 什么是数据挖掘?
- KDD 过程
- 数据挖掘的真实用例
目录
什么是数据仓库?
如果我们要定义数据仓库,它可以解释为面向主题的、时变的、非易失的、集成的数据集合。 数据仓库的介绍还包括来自外部来源的编译数据。 设计仓库的目的是通过报告不同聚合级别的数据来分析和诱导业务决策。 在进一步讨论之前,让我们先看看这些术语在数据仓库环境中的含义:
面向主题
组织可以使用数据仓库来分析特定的主题领域。 假设您想查看您的销售团队在过去 5 年中的表现如何——您可以查询您的仓库,它会告诉您所有您需要知道的信息。 在这种情况下,“销售”可以被视为一个主题。
时变
数据仓库负责为组织存储历史数据。 例如,交易系统可以保存客户的最新地址,但数据仓库也将保存所有以前的地址。 除了保留历史数据外,它还不断添加来自各种来源的数据——这就是它成为时变模型的原因。 存储的数据总是会随着时间而变化。
非挥发性
一旦数据存储在数据仓库中,就无法更改或修改。 我们只能添加我们要修改的数据的修改副本。
融合的:
正如我们之前所说,数据仓库保存来自多个来源的数据。 假设我们有两个数据源——A 和 B。这两个源中可能存储了完全不同类型的数据,但是当它们被带到仓库时,它们会进行预处理。 这就是数据仓库如何整合来自多个来源的数据。
数据仓库流程
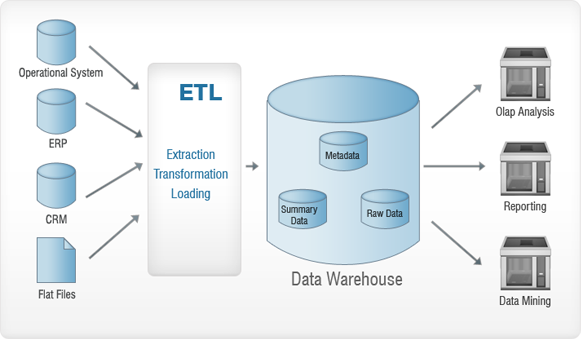
看看上面的图片。 从各种来源(操作系统、ERP、CRM、平面文件等)收集的数据在插入数据仓库之前要经过 ETL 过程。 这样做本质上是为了从数据中删除异常(如果有),从而不会对数据仓库造成损害。 ETL 代表 – 提取、转换和加载。 让我们详细看看这些过程中的每一个。 为了更好地理解,我们将使用一个类比——想想淘金热并继续阅读!
萃取
提取本质上是为了使用尽可能少的资源从源系统收集所有需要的数据。
把这一步想象成在河流中寻找尽可能大的金块。
转型
主要目的是以通用格式将提取的数据插入数据库。 这是因为不同的数据源会有不同的数据存储格式——例如,一个数据源可能有“dd/mm/yyyy”格式的数据,而另一个数据源可能有“dd-mm-yy”格式的数据。 在这一步中,我们将把它转换成一种通用格式——一种用于所有来源的数据。
现在你有一个金块。 你做什么工作? 将其熔化并去除杂质。
正在加载
在此步骤中,将转换后的数据加载到目标数据库中。
现在你有了纯金——把它塑造成戒指然后卖掉!
从各种来源获取数据并将其存储在数据仓库中(当然是在 ETL 过程之后)的过程就是所谓的数据仓库。
现在,您的数据已准备就绪 - 已全部清理完毕并准备就绪。 下一步应该是什么? 提取知识——是的!
数据挖掘助你一臂之力!
如何过渡到数据分析?什么是数据挖掘?
数据挖掘很简单,就是从数据集中提取以前未知但可能有用的信息的过程。 “以前不为人知”是指只有在深入挖掘数据仓库之后才能获得的知识——也就是说,它在表面上没有意义。 数据挖掘本质上是搜索数据元素之间存在的关系全局模式。

例如,假设您经营一家超市。 现在,客户的购买历史可能不会从表面上看出来很多,但是,如果仔细分析——识别可能的模式,那么仅仅这些信息就足以给出很多信息。 如果您还没有猜到,我们谈论的是 Target——一家超市,通过仔细研究她的购买历史并寻找趋势和模式,就能发现一名少女(顾客)怀孕了。 因此,经过仔细挖掘,表面上看起来如此微不足道的信息却具有如此巨大的价值——这正是我们所说的“以前未知的知识”。
我们认为,如果我们给您提供数据仓库和数据挖掘的风格,而完全忽略大局 - 数据库中的知识发现 (KDD),这对您是不公平的。 数据挖掘是 KDD 过程的步骤之一。让我们多谈谈 KDD。
获得世界顶尖大学的数据科学认证。 加入我们的行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。
数据库中的知识发现 (KDD)
数据挖掘是 KDD 过程中较为关键的步骤之一。 KDD 基本上涵盖了从数据选择到最终评估挖掘数据的所有内容。 完整的 KDD 循环如下图所示:
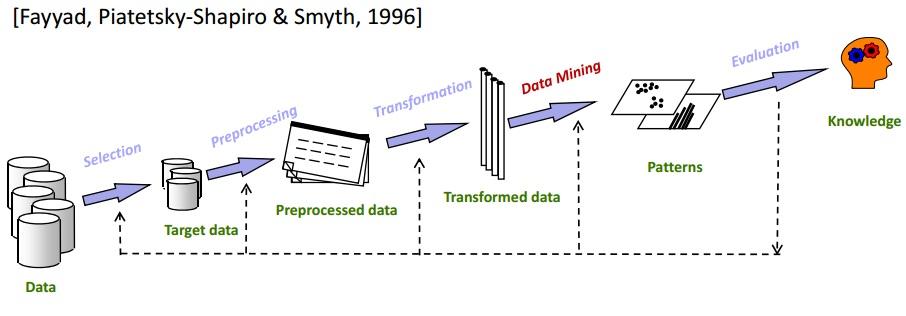
选择
了解准确的目标数据至关重要。 将数据挖掘分析为数据仓库子集是一个非常重要的步骤,因为删除不相关的数据元素会减少数据挖掘阶段的搜索空间。
预处理
在此步骤中,所选数据没有任何异常和异常值。 基本上,在这个阶段数据被完全清理。 就像,如果有一些缺失的数据字段,它们会填充适当的值。 例如,在存储组织员工详细信息的表中,假设有一个“中间名”列。 很可能,对于许多员工来说,这将是空的。 在这种情况下,将选择适当的值(N/A,例如)。
转型
此阶段尝试减少数据元素的种类,同时保持信息的质量。
数据挖掘
这是 KDD 过程的主要阶段。 转换后的数据经过数据挖掘方法,如分组、聚类、回归等。这是迭代完成的,以带来最佳结果。 可以根据需要使用不同的技术。
评估
这是最后一步。 在此,获得的知识被记录并呈现以供进一步分析。 在此步骤中使用了各种数据可视化工具,以美观且易于理解的方式描述所获得的知识。
辛普森悖论如何影响数据?
数据挖掘的真实用例
从亚马逊、Flipkart、Netflix,到 Facebook、Twitter、Instagram,甚至是沃尔玛,每个组织都在充分利用数据挖掘。 在本节中,我们将讨论数据挖掘的四种广泛用例,它们是您日常生活中不可或缺的一部分。
服务供应商
电信服务提供商使用数据挖掘来预测“客户流失”——他们使用的一个术语,用于表示客户放弃他们而转而使用另一个提供商。 除此之外,他们还会整理计费信息、网站访问、客户服务交互和其他此类信息,为每个客户提供概率分数。 然后,为那些“流失”风险较高的客户提供优惠和奖励。
电子商务
在数据挖掘方面,电子商务很容易成为最知名的用例。 其中最著名的当然是亚马逊。 他们使用极其复杂的采矿技术。 例如,查看“查看过该产品的人也喜欢这个”功能!
超级市场
超市也是数据挖掘的一个有趣用例。 挖掘客户的购买历史可以让他们了解他们的购买模式。 然后,超市使用此信息为客户提供个性化的优惠。 哦,我们有没有告诉你Target使用数据挖掘做了什么? (是的我们做了!)
零售
零售商将他们的客户分为新近度、频率和货币 (RFM) 组。 使用数据挖掘,他们针对这些群体进行营销。 消费很少但频繁且最近一次购买的客户与花费很多但只消费一次的客户的处理方式将有所不同。
包起来…
数据仓库和数据挖掘构成了当今世界上最重要的两个过程。 今天几乎每一件大事都是复杂数据挖掘的结果。 因为未挖掘的数据与没有数据一样有用(或无用)。
同样,要了解数据挖掘和数据仓库之间的区别,您必须沉迷于从数据挖掘到数据仓库的介绍——这是一种将来自不同来源的数据集中在一个数据库中的方法。 我们可以将数据仓库定义为编译的历史数据或实时数据馈送,主要返回有机和综合信息。
我们希望本文能让您清楚了解什么是数据仓库和数据挖掘等等。 总而言之,在单个数据库中收集、存储和组织信息的过程被认为是数据仓库与数据挖掘,主要是从不同的角度从数据中提取有意义的信息。 收集到的所有有用信息都可以在以后用于解决可能成为公司发展障碍的未来问题,甚至还可以降低成本。 如果您正在寻找一个光明而迷人的未来,并且如果您对探索充满热情,那么从学习 Whats' What of Data Warehousing 和 Data Mining 开始将是您的绝佳选择。
我们希望这篇文章能让您清楚地了解这两个术语的含义以及更多内容! 如果您想了解数据科学,请查看 IIIT-B 和 upGrad 的数据科学 PG 文凭,该文凭专为在职专业人士而设,提供 10 多个案例研究和项目、实用的实践研讨会、行业专家指导、1-与行业导师面对面交流,400 多个小时的学习和顶级公司的工作协助。
企业如何使用数据仓库和数据挖掘?
数据挖掘和数据仓库都是将信息(或数据)转化为可用知识的商业智能技术。
数据挖掘是一种统计分析方法。 分析师使用技术工具来查询和整理数千兆字节的数据以寻找趋势。 然后,企业根据对消费者和供应商行为的理解,利用这些数据做出更好的业务决策。
数据仓库是设计数据存储方式以促进报告和分析的过程。 根据数据仓库专家的说法,众多的数据存储在概念上和物理上都是集成的,并且彼此相关。 公司的数据通常保存在多个数据库中。
数据仓库和数据挖掘之间的核心区别是什么? 在商业世界中哪个更实用?
数据仓库是一种数据存储系统。 它通常需要为各种目标从多个来源获取各种数据类型。 有规律地存储这些数据以便以后检索的过程称为数据仓库。
提取数据的过程称为数据挖掘。 它需要为特定目标定位最相关的信息。 它可能来自您的数据仓库,或者完全来自其他地方。 您期望提炼和清理您挖掘的数据,就像处理真正的矿石一样。
你的仓储系统越好,开采就越容易。
数据挖掘和 KDD 过程相似吗?
尽管 KDD 和数据挖掘是经常互换的术语,但它们指的是两个不同但相关的概念。
数据挖掘是 KDD 过程中的一个组件,处理识别数据中的模式,而 KDD 是从数据中提取知识的整个过程。 换句话说,数据挖掘只是应用特定的算法来达到KDD过程的最终目的。