
Das Was ist was von Data Warehousing und Data Mining
Veröffentlicht: 2018-02-22Unternehmensdaten wurden in Informationssilos gespeichert, die physisch von anderen Datenspeichern getrennt waren, und jedes Silo erfüllte spezialisierte Funktionen – aber das war, bevor Big Data die Welt eroberte (mit einem Sturm, wenn wir so sagen dürfen). Jetzt ist es praktisch unmöglich, die gleichen Methoden auf so große Datensätze anzuwenden. Stellen Sie sich vor, wie viele Datenextrakte aus so vielen dieser physisch getrennten Informationssilos erforderlich wären – nur um eine einfache Abfrage auszuführen. Alles dank der extrem massiven Datenberge, die bei Organisationen und Big-Data-Engineering-Methoden liegen.
Lassen Sie uns genau beobachten, wie Data Warehousing und Data Mining die Szene betreten. Data Warehouses wurden entwickelt, um dieses Problem der Datenspeicherung zu bekämpfen. Data Warehouses können im Wesentlichen als ein einheitliches Repository von Daten betrachtet werden, die aus verschiedenen Quellen stammen und in verschiedenen Formaten vorliegen. Data Mining hingegen ist der Prozess des Extrahierens von Wissen aus dem genannten Data Warehouse.
In diesem Artikel werfen wir einen detaillierten Blick auf Data Warehouse und Data Mining. Zum besseren Verständnis haben wir den Artikel wie folgt strukturiert:
- Was ist Data Warehousing?
- Data Warehouse-Prozesse
- Was ist Data-Mining?
- KDD-Prozess
- Reale Anwendungsfälle von Data Mining
Inhaltsverzeichnis
Was ist Data Warehousing?
Wenn wir Data Warehouse definieren würden, könnte es als subjektorientierte, zeitvariante, nichtflüchtige, integrierte Sammlung von Daten erklärt werden. Die Einführung in das Data Warehousing umfasst auch zusammengestellte Daten aus externen Quellen. Der Zweck des Entwerfens eines Warehouses besteht darin, Geschäftsentscheidungen zu analysieren und herbeizuführen, indem Daten auf einer anderen aggregierten Ebene gemeldet werden. Bevor wir von hier aus fortfahren, schauen wir uns zunächst an, was diese Begriffe im Zusammenhang mit einem Data Warehouse bedeuten:
Themenorientiert
Organisationen können das Data Warehouse verwenden, um einen bestimmten Themenbereich zu analysieren. Angenommen, Sie möchten sehen, wie gut Ihr Verkaufsteam in den letzten 5 Jahren gearbeitet hat – Sie können Ihr Lager abfragen und es wird Ihnen alles sagen, was Sie wissen müssen. In diesem Fall kann „Verkauf“ als Thema behandelt werden.
Zeitunterschied
Data Warehouses sind für die Speicherung historischer Daten für Organisationen verantwortlich. Beispielsweise kann ein Transaktionssystem die neueste Adresse eines Kunden enthalten, aber ein Data Warehouse enthält auch alle früheren Adressen. Es fügt kontinuierlich Daten aus verschiedenen Quellen hinzu, abgesehen von der Beibehaltung der historischen Daten – das macht es zu einem zeitvarianten Modell. Die gespeicherten Daten werden immer mit der Zeit variieren.
Nicht flüchtig
Sobald Daten in einem Data Warehouse gespeichert sind, können sie nicht geändert oder modifiziert werden. Wir können nur eine modifizierte Kopie der Daten hinzufügen, die wir ändern möchten.
Integriert:
Wie bereits erwähnt, enthält ein Data Warehouse Daten aus mehreren Quellen. Angenommen, wir haben zwei Datenquellen – A und B. In beiden Quellen können völlig unterschiedliche Arten von Daten gespeichert sein, aber wenn sie in ein Warehouse gebracht werden, werden sie einer Vorverarbeitung unterzogen. So integriert ein Data Warehouse Daten aus mehreren Quellen.
Data Warehouse-Prozesse
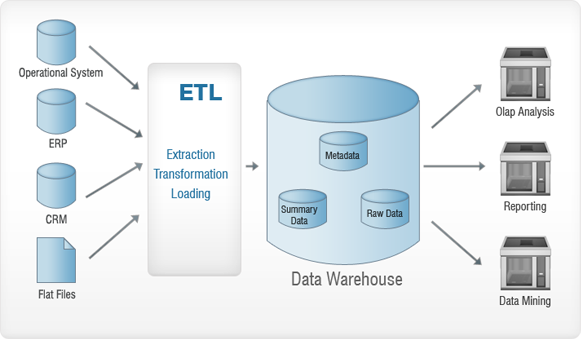
Schauen Sie sich das obige Bild an. Die Daten, die aus verschiedenen Quellen (operatives System, ERP, CRM, Flat Files usw.) gesammelt werden, werden einem ETL-Prozess unterzogen, bevor sie in das Data Warehouse eingefügt werden. Dies geschieht im Wesentlichen, um etwaige Anomalien aus den Daten zu entfernen – damit dem Data Warehouse kein Schaden zugefügt wird. ETL steht für – Extraktion, Transformation und Laden. Sehen wir uns jeden dieser Prozesse im Detail an. Um das besser zu verstehen, verwenden wir eine Analogie – denken Sie an einen Goldrausch und lesen Sie weiter!
Extraktion
Die Extraktion dient im Wesentlichen dazu, alle erforderlichen Daten aus den Quellsystemen mit möglichst wenig Ressourcen zu sammeln.
Stellen Sie sich diesen Schritt so vor, als würden Sie den Fluss auf der Suche nach möglichst großen Goldnuggets schwenken .
Transformation
Das Hauptziel besteht darin, die extrahierten Daten in einem allgemeinen Format in die Datenbank einzufügen. Dies liegt daran, dass unterschiedliche Quellen unterschiedliche Formate zum Speichern der Daten haben – zum Beispiel könnte eine Datenquelle Daten im „tt/mm/jjjj“-Format haben und die andere könnte sie im „tt-mm-jj“-Format haben. In diesem Schritt konvertieren wir dies in ein allgemeines Format – eines, das für Daten aus allen Quellen verwendet wird.
Jetzt haben Sie ein Goldnugget. Wie geht's? Schmelzen Sie es ein und entfernen Sie die Verunreinigungen.
Wird geladen
In diesem Schritt werden die transformierten Daten in die Zieldatenbank geladen.
Jetzt haben Sie reines Gold – formen Sie es zu einem Ring und verkaufen Sie es!
Der Prozess, Daten aus verschiedenen Quellen zusammenzubringen und im Data Warehouse zu speichern (natürlich nach dem ETL-Prozess), wird als Data Warehousing bezeichnet.
Jetzt haben Sie Ihre Daten an Ort und Stelle – alle bereinigt und einsatzbereit. Was sollte der nächste Schritt sein? Wissen extrahieren – ja!
Data Mining zur Rettung!
Wie können Sie auf Datenanalyse umsteigen?Was ist Data-Mining?
Data Mining ist ganz einfach der Prozess, bisher unbekannte, aber potenziell nützliche Informationen aus den Datensätzen zu extrahieren. Mit „vorher unbekannt“ meinen wir Wissen, das nur nach gründlicher Durchforstung des Data Warehouse erworben werden kann – dh es ergibt an der Oberfläche keinen Sinn. Data Mining sucht im Wesentlichen nach den globalen Beziehungsmustern, die zwischen den Datenelementen bestehen.
Stellen Sie sich zum Beispiel vor, Sie betreiben einen Supermarkt. Nun mag die Kaufhistorie eines Kunden oberflächlich betrachtet nicht viel verraten, aber wenn sie sorgfältig analysiert wird – und die möglichen Muster erkennt – dann reicht allein diese Information aus, um viel zu verraten. Falls Sie es noch nicht erraten haben, wir sprechen von Target – einem Supermarkt, der herausfand, dass ein junges Mädchen (Kundin) schwanger war, indem er einfach ihre Kaufhistorie sorgfältig studierte und nach Trends und Mustern suchte. Die Informationen, die an der Oberfläche so trivial aussahen, stellten sich also als so wertvoll heraus, wenn sie sorgfältig geschürft wurden – und genau das meinen wir mit „bisher unbekanntem Wissen“.
Wir halten es für unfair Ihnen gegenüber, wenn wir Ihnen den Geschmack von Data Warehousing und Data Mining vermitteln und das große Ganze – Knowledge Discovery in Databases (KDD) – völlig ignorieren. Data Mining bildet einen der Schritte eines KDD-Prozesses. Lassen Sie uns ein wenig mehr über KDD sprechen.

Erwerben Sie eine Data-Science-Zertifizierung von den besten Universitäten der Welt. Nehmen Sie an unseren Executive PG-Programmen, Advanced Certificate Programs oder Masters-Programmen teil, um Ihre Karriere zu beschleunigen.
Knowledge Discovery in Datenbanken (KDD)
Data Mining ist einer der wichtigsten Schritte im KDD-Prozess. KDD deckt im Grunde alles von der Auswahl der Daten bis zur abschließenden Auswertung der geschürften Daten ab. Der vollständige KDD-Zyklus ist im Bild unten dargestellt:
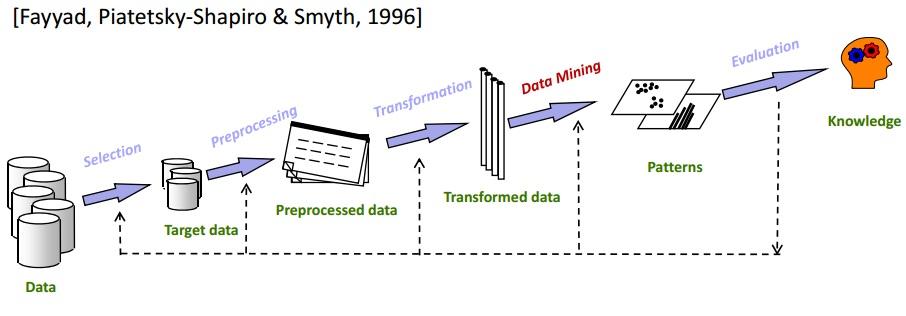
Auswahl
Es ist von größter Bedeutung, die genauen Zieldaten zu kennen. Das Analysieren von Data-Mining-zu-Data-Warehousing-Teilmengen ist ein sehr wichtiger Schritt, da das Entfernen nicht verwandter Datenelemente den Suchraum während der Data-Mining-Phase verringert .
Vorverarbeitung
In diesem Schritt werden die ausgewählten Daten von Anomalien und Ausreißern befreit. Grundsätzlich werden die Daten in dieser Phase komplett bereinigt. Wenn zum Beispiel einige Datenfelder fehlen, werden sie mit entsprechenden Werten gefüllt. Angenommen, in der Tabelle, in der die Details der Mitarbeiter Ihres Unternehmens gespeichert sind, gibt es beispielsweise eine Spalte für „Zweiter Vorname“. Die Chancen stehen gut, dass es für viele Mitarbeiter leer sein wird. In einem solchen Szenario wird ein geeigneter Wert gewählt (z. B. N/A).
Transformation
In dieser Phase wird versucht, die Vielfalt der Datenelemente zu reduzieren und gleichzeitig die Qualität der Informationen zu erhalten.
Data-Mining
Dies ist die Hauptphase eines KDD-Prozesses. Die transformierten Daten werden Data-Mining-Methoden wie Gruppierung, Clustering, Regression usw. unterzogen. Dies erfolgt iterativ, um die besten Ergebnisse zu erzielen. Je nach Anforderung können unterschiedliche Techniken zum Einsatz kommen.
Auswertung
Dies ist der letzte Schritt. In diesem werden die gewonnenen Erkenntnisse dokumentiert und zur weiteren Analyse vorgelegt. In diesem Schritt werden verschiedene Datenvisualisierungstools verwendet, um das erworbene Wissen schön und verständlich darzustellen.
Wie wirkt sich das Simpson-Paradoxon auf Daten aus?
Reale Anwendungsfälle von Data Mining
Jede Organisation von Amazon, Flipkart, Netflix über Facebook, Twitter, Instagram bis hin zu Walmart setzt Data Mining sinnvoll ein. In diesem Abschnitt sprechen wir über vier allgemeine Anwendungsfälle von Data Mining, die ein wesentlicher Bestandteil Ihres täglichen Lebens sind.
Dienstleister
Telekommunikationsanbieter verwenden Data Mining, um die „Abwanderung“ vorherzusagen – ein Begriff, den sie verwenden, wenn ein Kunde sie für einen anderen Anbieter verlässt. Abgesehen davon sammeln sie Rechnungsinformationen, Website-Besuche, Interaktionen mit der Kundenbetreuung und andere solche Dinge, um jedem Kunden eine Wahrscheinlichkeitsbewertung zu geben. Dann werden denjenigen Kunden, die ein höheres Abwanderungsrisiko tragen, Angebote und Anreize geboten.
E-Commerce
E-Commerce ist mit Abstand der bekannteste Anwendungsfall, wenn es um Data Mining geht. Einer der bekanntesten von ihnen ist natürlich Amazon. Sie verwenden äußerst ausgefeilte Bergbautechniken. Schauen Sie sich zum Beispiel die Funktion „Personen, die dieses Produkt angesehen haben, mochte auch dieses“ an!
Supermärkte
Auch Supermärkte sind ein interessanter Anwendungsfall für Data Mining. Das Durchsuchen der Kaufhistorie von Kunden ermöglicht es ihnen, ihre Kaufmuster zu verstehen. Diese Informationen werden dann von den Supermärkten verwendet, um den Kunden personalisierte Angebote zu unterbreiten. Oh, und haben wir Ihnen erzählt, was Target mit Data Mining gemacht hat? (Ja, das haben wir!)
Einzelhandel
Einzelhändler teilen ihre Kunden in Recency-, Frequency- und Monetary-Gruppen (RFM) ein. Mithilfe von Data Mining zielen sie auf diese Gruppen ab. Ein Kunde, der wenig, aber häufig ausgibt und seinen letzten Einkauf erst vor kurzem getätigt hat, wird anders behandelt als ein Kunde, der viel, aber nur einmal ausgegeben hat.
Abschluss…
Data Warehousing und Data Mining sind zwei der wichtigsten Prozesse, die heute buchstäblich die Welt am Laufen halten. Fast jede große Sache ist heute das Ergebnis von ausgeklügeltem Data Mining. Denn nicht geschürfte Daten sind genauso nützlich (oder nutzlos) wie gar keine Daten.
Um den Unterschied zwischen Data Mining und Data Warehousing zu verstehen, müssen Sie sich von der Einführung in Data Mining bis Data Warehousing hingeben – eine Methode, bei der alle Daten aus unterschiedlichen Quellen in einer Datenbank zentralisiert werden. Wir können Data Warehousing als zusammengestellte historische Daten oder Echtzeit-Daten-Feeds definieren, die größtenteils organische und integrierte Informationen zurückgeben.
Wir hoffen, dass dieser Artikel Ihnen Klarheit darüber verschafft hat, was Data Warehousing und Data Mining sind und vieles mehr. Zusammenfassend lässt sich sagen, dass der Prozess des Sammelns, Speicherns und Organisierens von Informationen in einer einzigen Datenbank als Data Warehousing vs. Data Mining betrachtet wird, bei dem es hauptsächlich darum geht, aussagekräftige Informationen aus den Daten aus einer anderen Perspektive zu extrahieren. Alle gesammelten nützlichen Informationen können später verwendet werden, um zukünftige Probleme zu lösen, die das Wachstum des Unternehmens behindern könnten, und können sogar Kosten senken. Wenn Sie auf der Suche nach einer glänzenden und faszinierenden Zukunft sind und Exploration Ihre Leidenschaft ist, dann wäre es eine ausgezeichnete Option für Sie, mit dem Erlernen des Whats' What von Data Warehousing und Data Mining zu beginnen.
Wir hoffen, dass dieser Artikel Ihnen Klarheit darüber verschafft hat, was diese beiden Begriffe bedeuten und vieles mehr! Wenn Sie neugierig sind, mehr über Data Science zu erfahren, schauen Sie sich das PG Diploma in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische Workshops, Mentoring mit Branchenexperten, 1- on-1 mit Mentoren aus der Branche, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Wie nutzen Unternehmen Data Warehousing und Data Mining?
Sowohl Data Mining als auch Data Warehousing sind Business-Intelligence-Techniken zur Umwandlung von Informationen (oder Daten) in nutzbares Wissen.
Data Mining ist eine statistische Analysemethode. Technische Tools werden von Analysten verwendet, um Gigabytes an Daten auf der Suche nach Trends abzufragen und zu sortieren. Unternehmen nutzen diese Daten dann, um bessere Geschäftsentscheidungen zu treffen, die auf ihrem Verständnis des Verhaltens ihrer Verbraucher und Lieferanten basieren.
Data Warehousing ist der Prozess des Entwerfens, wie Daten gespeichert werden, um Berichte und Analysen zu erleichtern. Laut Data-Warehouse-Spezialisten sind die zahlreichen Datenspeicher sowohl konzeptionell als auch physisch integriert und aufeinander bezogen. Die Daten eines Unternehmens sind typischerweise in mehreren Datenbanken gespeichert.
Was ist der Hauptunterschied zwischen Data Warehousing und Data Mining? Was ist praktischer in der Geschäftswelt?
Ein Data Warehouse ist ein Datenspeichersystem. Es beinhaltet normalerweise eine Vielzahl von Datenarten, die aus mehreren Quellen für eine Vielzahl von Zielen erworben wurden. Der Prozess, diese Daten diszipliniert zu speichern, damit sie später abgerufen werden können, wird als Data Warehousing bezeichnet.
Der Prozess des Extrahierens von Daten wird als Data Mining bezeichnet. Es geht darum, die relevantesten Informationen für ein bestimmtes Ziel zu finden. Es kann aus Ihrem Data Warehouse oder von ganz woanders stammen. Sie erwarten, dass Sie die Daten, die Sie abbauen, verfeinern und bereinigen, genau wie Sie es mit echtem Erz tun würden.
Je besser Ihre Lagersysteme sind, desto einfacher wird das Mining.
Sind Data-Mining- und KDD-Prozesse ähnlich?
Obwohl KDD und Data Mining die Begriffe sind, die häufig ausgetauscht werden, beziehen sie sich auf zwei unterschiedliche, aber verwandte Konzepte.
Data Mining ist eine Komponente innerhalb des KDD-Prozesses, die sich mit der Erkennung von Mustern in Daten befasst, während KDD der gesamte Prozess der Extraktion von Wissen aus Daten ist. Anders ausgedrückt ist Data Mining nur die Anwendung eines bestimmten Algorithmus, um den endgültigen Zweck des KDD-Prozesses zu erreichen.