
使用 Python 进行数据分析 [你需要知道的一切]
已发表: 2020-09-02对于任何想要开始数据分析的人来说,首先想到的语言是 R 或 Python。 而开发人员现在更倾向于 Python 的原因在于它在通用软件开发领域的广泛适应性。 因此,对于开始进入数据科学领域的人来说,使用 python 进行数据分析是最常听到的术语之一。
目录
为什么要进行数据分析?
现在首先,为什么要进行数据分析? 好吧,这是了解您正在使用的数据类型的第一步。 这是您在数据中找到有价值的模式的步骤,否则您可能看不到这些模式。 总体而言,它提供了对手头数据集的直观理解。
在这里,我们确实需要在数据分析和数据预处理之间划清界限。 数据预处理涉及对数据集进行建模,以确保它已准备好进行训练。 数据分析是了解数据集,是数据预处理的前置步骤。 在数据分析中,我们尝试对数据进行建模以更好地查看它,从而了解有关手头数据集的见解。
为什么是 Python?
第二个问题是,为什么是 Python? 好吧,我们已经说过 Python 是一种广泛适用的语言。 是的,它不是数据分析的唯一选择,但它是一个非常好的选择。 另一个原因是它使用得更多! Python 很简单,并且拥有庞大的开发人员社区来帮助您使用 python 进行数据分析。 此外,使用 Python进行数据分析非常有趣,因为它提供了大量用于数据分析和可视化的创意库。
在 Python 中,数据分析的基础库是 Pandas。 它是一个高级库,建立在 NumPy 库之上,用于科学计算和数值分析。 Pandas 通过提供称为 DataFrame 的数据结构使处理数据变得更容易。 DataFrame 有助于读取和存储数据集。 它提供了读取和写入数据集的基本功能,以及查看元数据和查询功能以从数据集中提取每一个见解。
值得注意的是,数据可视化是整体数据分析的重要组成部分。 因为它不仅有助于您自己更好地理解数据,还有助于您提供见解的人。 我们将讨论两个最常用的可视化库:Matplotlib 和 Seaborn。 Matplotlib 是 Python 中任何可视化的基础库。 Seaborn 也是在 Matplotlib 之上制作的,它提供了一些最具创意的数据可视化功能。
设置环境
第一步是设置您的环境。 在使用 python 执行数据分析时,重要的是要有一个适当的环境来保存您的所有工作。 使用 python进行数据分析不仅仅是一个脚本,而是你自己与数据集的交互,为此,你确实需要一个合适的工作场所。
在 python 中,该服务由 Anaconda Distribution 提供。 Anaconda 的主要工作场所是 Jupyter notebook。 那么,现在为什么选择 Jupyter? 好吧,它可以让您直接在笔记本中进行可视化。 它还具有一些神奇的功能,可让您直接查看输出,而无需明确说明您想要它的位置。
库、Pandas 和 Matplotlib 是预先安装的,因此使用它们不需要额外的设置。
以下是如何使用 Python 进行数据分析的概要:
- 加载数据集
- 使用 Pandas 查看数据集的元数据
- 使用 Matplotlib 进行数据可视化
- 收集有关数据的见解
导入必要的库
在我们开始查看步骤代码之前,只需使用伪标签导入必要的库,就像我们为整个程序调用它们的名称一样。
将numpy导入为np
将熊猫导入为pd
# 用于数据可视化
将matplotlib.pyplot导入为plt
将seaborn导入为sns
现在我们将查看每个步骤并讨论哪些功能可用以及如何使用这些功能。
首先,读取数据集。 Pandas 提供了一些将数据集加载到其核心数据结构中的基本功能:DataFrame。 我们可以如下使用它。
data_df = pd.read_csv('heart.csv')
任何读取函数的输出都将是一个 DataFrame。 除了 CSV 阅读器,pandas 还为几乎所有类型的数据提供阅读器。 从 HTML 到 JSON 和 Excel。
除此之外,如果您没有任何此类数据并想创建数据集,您可以轻松使用 Pandas 的 Series 和 DataFrame 对象函数。
因此,一旦您掌握了数据,让我们继续查看数据的内容。 要获得数据的第一个视图,您可以使用 df.info 或 df.describe 等函数来了解数据集的结构。
data_df.info()
data_df.describe()
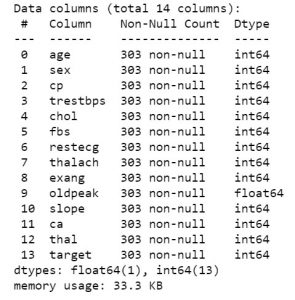
一旦您知道您的数据集包含哪些特征,您可能想要查看这些特征的值。 您可以使用 df.head() 函数获取前 5 个样本。
data_df.head()
#要么
data_df.head(3)
您还可以指定样本数以覆盖默认值 5。您还可以使用 df.tail() 函数获取数据集的最后 5 个值。
data_df.tail()
这只是为了对您的数据的外观有一个高级概述。 准备就绪后,您可以使用 Matplotlib 开始主要的数据可视化任务。 打入以下代码以使绘图具有交互性并在笔记本本身中查看相同的内容。
%matplotlib 内联
我们将在 matplotlib 中看到前 5 个可视化的功能。 在进入它之前,我们应该知道一些控制我们的情节的其他功能。 功能如下:
- 标签:xlabel()、ylabel()。 它们用于 x 轴和 y 轴标签。
- 图例:用于制作情节的图例。
- 标题:为您的绘图分配标题
- 最后,显示功能以查看绘图。
结帐:印度的数据分析师薪水
可视化
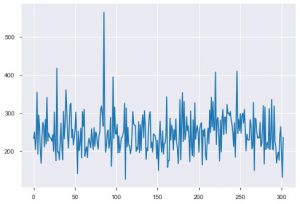
现在让我们看看可视化。 我们将从基本情节开始。 plt.plot() 用于为您的数据生成简单的线图。 该函数强制需要两个参数,分别是x轴数据和y轴数据。 您可以选择为绘图提供样式、名称和颜色。 这是它在代码中的样子。
plt.plot(data_df['chol'])
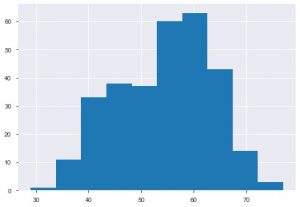
第二个图是直方图。 直方图可帮助您查看特定特征的频率或分布。 它可以帮助您查看数量之间的关系。 Plt.hist() 是在数据上创建直方图的基本函数。 您可以提及 bins 参数来控制绘图上的数字。 如果要进行单变量分析,则只需要传递单轴数据。
plt.hist(data_df['年龄'])

您会经常看到的另一个图是条形图。 它有助于分析和比较不同的特征。 与直方图不同,条形图用于处理分类数据。
您可以直接在 DataFrame 上应用绘图,也可以在 plt.bar() 函数中指定参数。 以下是我们如何使用它。
df = pd.DataFrame(np.random.rand(15, 5), columns=['t1', 't2', 't3', 't4', 't5'])
df.plot.bar()
您还可以使用 barh() 函数水平使用条形图。
另一个有见地的图表是箱线图。 它有助于理解每个特征中值的分布。 您可以使用 plt.boxplot() 函数指定要在其上生成箱线图的数据。 当您需要快速查看数据集中的离散度或偏度时,该图特别有用。 这是您可以使用它的方法。
plt.boxplot(data_df['chol'])
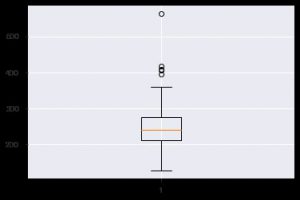
每当您使用统计数据时,您肯定会看到散点图。 散点图有助于观察两个特征之间的关系。 该图需要 x 轴数据和 y 轴的数值。 您可以简单地在 plt.scatter() 函数中提供这两个值,也可以通过在 x 和 y 属性中指定列名直接应用于 DataFrame。 以下是如何使用它:
plt.scatter(data_df['age'], data_df['chol'])
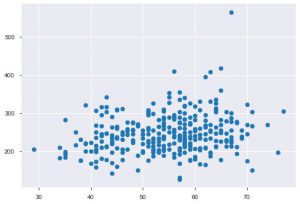
现在是向您介绍 Seaborn 函数的合适时机。 seaborn 中的散点图比 matplotlib 更直观,因为它还默认在图中提供回归线,以更好地可视化图。 您可以使用 sns.lmplot() 函数来绘制该图。
sns.lmplot('年龄', 'chol', data=data_df)
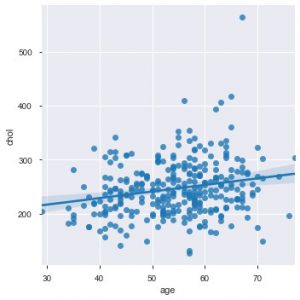
正如您在上图中所见,回归线有助于更好地理解分布。
使用 seaborn 的另一个改进是群体图。 它用于绘制分类散点图。 与类似的条形图相比,群图的优点之一是它仅使用非重叠点。 因此,这是一个更清晰的情节,因此可以提供更好的洞察力。
sns.swarmplot(data_df['age'], data_df['chol'])
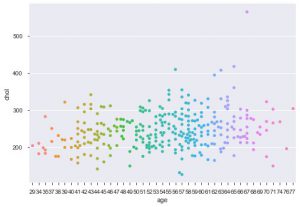
因此,这些是 Matplotlib 和 Seaborn 中不同类型的图。 这只是冰山一角,还有数百种其他不同的方法可以绘制数据以提取有关数据的创造性见解。
现在您知道了这些图,让我们看看如何使用 python 进行实际数据分析。 我们将看一些更多的图,看看它们向我们展示了关于使用 python 进行数据分析的内容。
开始吧。
加载数据后,任何数据分析师现在要做的第一件事就是制作 pandas 配置文件。 现在,这也可以看作是一种快捷方式,但是如果您想查看数据集中变量的所有关系、计数和直方图,您可以使用 pandas 分析。 很容易生成,只需下载pandas-profiling模块,打入如下代码即可:
导入pandas_profiling
profile = pandas_profiling.ProfileReport(data_df)
轮廓
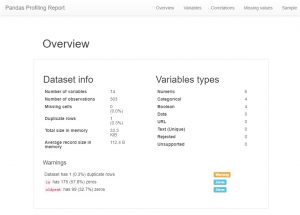
如您所见,有大量的元数据信息和个别特征信息。 这些可能会导致一些很好的理解。
我们可以做的第二件事是生成热图。 现在热图所做的是,它显示了每个特征与另一个特征的相关性。 如果我们发现具有更高相关性的值,这意味着这两个特征彼此非常相似。 因此,我们可以删除其中一项功能,但该模型仍然可以正常工作。
sns.heatmap(data_df.corr(), annot = True , cmap='Oranges')
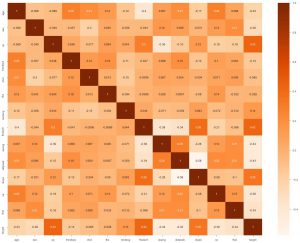
在这里我们可以看到没有一个是高度相关的,因此我们可以告诉模型工程师我们需要所有特征作为输入。
我们可以看到年龄分布是什么,因为我们正在处理心脏病数据集,让我们看看分布,所以我们可以使用 seaborn 的 distplot。
sns.distplot(data_df['age'], color = 'cyan')
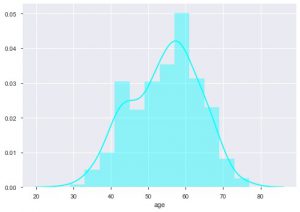
从图中可以看出,大多数患有心脏病的人都在 50 到 60 岁之间。同理,我们还可以看到其他一些重要的特征,比如静息血压,用 tresbps 表示。 我们可以制作一个箱线图来查看与目标值(即 0 和 1)相比的分布。
sns.boxplot(data_df['target'],data_df['trestbps'],调色板 = 'twilight')
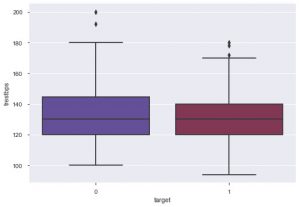
我们可以从图中得出结论,如果这个人的 tres bps 值较低,那么他们患心脏病的机会就会低于 tres bps 值较高的人。
同样,我们也可以看到与胆固醇水平的关系。 我们确实看到胆固醇水平较低的人患心脏病的几率较低。
您可以记录所有这些见解并将其提供给机器学习工程师,然后他们可以使用它们来制作有效的模型。
结论
因此,这就是使用 python 进行数据分析的方法。 这只是数据科学之旅的第一步。 要了解有关从数据和整体数据科学中提取创造性见解的更多信息,请在此处访问 upGrad 提供的课程。 您将找到一系列有用的课程,这些课程将有效地指导使用 python 进行数据分析。
学习世界顶尖大学的数据科学课程。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。
我应该如何开始学习 Python 进行数据分析?
如果您正在学习 Python 进行数据分析,那么您来对地方了。 你需要有一个循序渐进的方法来使学习过程变得更简单。 该过程如下所示:
1. 明确学习 Python 的目的以及如何在您的领域中使用它。
2.下载所需的Python终端并将其安装在您的系统中。
3.通过学习不同的课程和了解不同的Python库开始学习Python的基础知识。
4.熟悉Python中使用的正则表达式。
5. 深入了解不同的 Python 库,如 Pandas、NumPy、Matplotlib 和 SciPy。
6. 开始学习数据分析概念以及如何将 Python 与其集成。
7. 现在,您只需要继续练习不同的工具和技术,以便更好地使用 Python 进行数据分析。 通过这种循序渐进的方法,您会发现学习 Python 非常容易,并且可以更好地使用数据分析。
Python如何用于数据分析?
众所周知,Python 是一种非常重要的数据分析资源。 Python 以不同的方式帮助执行数据分析。 但在此之前,您需要准备用于分析的数据、执行统计分析、创建可以提供一些洞察力的数据可视化、根据可用数据预测未来趋势等等。
Python 被发现是数据分析的关键元素,因为它有助于:
1. 导入数据集
2.清理和准备数据以进行分析
3. 操作 Pandas DataFrame
4. 总结数据集
5. 使用 Python 开发用于数据分析的机器学习模型
我可以在一个月内学习 Python 吗?
是的,如果你精通任何其他编程语言,如 Java、C、C++ 等,你绝对可以做到这一点。如果你的基础很清楚,你会发现即使在一个月内学习 Python 也很容易。 除此之外,如果你努力并以一种有纪律的方式循序渐进的方法,即使你没有其他编程语言的先验知识,你也可以在一个月内学习 Python。 你只需要设定一个时间表,并在一个月内专注于学习 Python。