
Pythonを使用したデータ分析[知っておくべきことすべて]
公開: 2020-09-02データ分析を始めたい人にとって、頭に浮かぶ最初の言語はRまたはPythonです。 そして、開発者がPythonに傾倒するようになった理由は、一般的なソフトウェア開発分野でのPythonの幅広い適応性によるものです。 したがって、 Pythonを使用したデータ分析は、データサイエンスへの旅を始める人にとって最もよく耳にする用語の1つです。
目次
なぜデータ分析なのか?
まず、なぜデータ分析なのか? さて、それはあなたがどのタイプのデータを扱っているかを知るための最初のステップです。 これは、他の方法では見られない可能性のある、データ内の貴重なパターンを見つけるステップです。 全体として、手元にあるデータセットを直感的に理解できます。
ここでは、データ分析とデータ前処理の間に線を引く必要があります。 データの前処理では、データセットをモデル化して、トレーニングの準備ができていることを確認します。 データ分析は、データの前処理の前段階であるデータセットを理解することです。 データ分析では、データをより適切に表示するためにデータをモデル化することを試みます。したがって、手元にあるデータセットに関する洞察を学びます。
なぜPythonなのか?
2番目の質問は、なぜPythonなのかということです。 さて、Pythonは広く適応された言語であるとすでに述べました。 はい、データ分析に関してはそれが唯一の選択肢ではありませんが、かなり良い選択肢です。 もう一つの理由はそれがもっと使われているということです! Pythonは簡単で、Pythonを使用したデータ分析に関して支援する開発者の大規模なコミュニティがあります。 さらに、 Pythonを使用したデータ分析は、データ分析と視覚化のために多数のクリエイティブライブラリを提供しているため、非常に楽しいものです。
Pythonでは、データ分析の基本ライブラリはPandasです。 これは、科学計算および数値解析用のNumPyライブラリに基づいて構築された高レベルのライブラリです。 Pandasは、DataFrameと呼ばれるデータ構造を提供することにより、データの操作を容易にします。 DataFrameは、データセットの読み取りと保存に役立ちます。 これは、データセットの読み取りと書き込み、およびメタデータの表示とデータセットからすべての洞察を抽出するためのクエリ関数の基本関数を提供します。
データの視覚化は、全体的なデータ分析のかなりの部分であることに注意することが重要です。 それは、データを自分自身でよりよく理解するのに役立つだけでなく、洞察を提供している人にも役立つからです。 視覚化に最もよく使用される2つのライブラリ、MatplotlibとSeabornについて説明します。 Matplotlibは、Pythonでの視覚化のベースライブラリです。 Seabornは、最もクリエイティブなデータ視覚化機能のいくつかを提供するMatplotlibの上にも作成されています。
環境のセットアップ
最初のステップは、環境をセットアップすることです。 Pythonを使用してデータ分析を実行するときは、すべての作業を維持するための適切な環境を用意することが重要です。 Pythonを使用したデータ分析は単なるスクリプトではなく、データセットとの相互作用であり、そのためには、適切な作業場所が必要です。
Pythonでは、そのサービスはAnacondaディストリビューションによって提供されます。 Anacondaの主要な職場はJupyterノートブックです。 では、なぜJupyterなのか? まあ、それはあなたがあなたのノートブックの中に直接視覚化を持つことを可能にします。 また、必要な場所を明示的に指定せずに出力を直接表示できるいくつかの魔法の関数もあります。
ライブラリ、Pandas、およびMatplotlibはプリインストールされているため、それらを使用するために追加のセットアップは必要ありません。
Pythonを使用してデータ分析を回避する方法の概要は次のとおりです。
- データセットのロード
- Pandasを使用したデータセットのメタデータの表示
- Matplotlibを使用したデータの視覚化
- データに関する洞察の収集
必要なライブラリをインポートする
手順のコードを確認する前に、プログラム全体で呼び出す名前のように、疑似タグを使用して必要なライブラリをインポートするだけです。
numpyをnpとしてインポートします
パンダをpdとしてインポートします
#データの視覚化用
matplotlib.pyplotをpltとしてインポートします
Seabornをsnsとしてインポートする
次に、各ステップを見て、使用可能な機能とその使用方法について説明します。
まず、データセットを読み取ります。 パンダは、データセットをコアデータ構造であるDataFrameにロードするためのいくつかの基本的な機能を提供します。 以下のように使用できます。
data_df = pd.read_csv('heart.csv')
読み取り関数の出力はDataFrameになります。 CSVリーダーとは別に、パンダはほぼすべての種類のデータのリーダーを提供します。 HTMLからJSONへと優れています。
これとは別に、そのようなデータがなく、データセットを作成したい場合は、PandasのSeriesおよびDataFrameオブジェクト関数を簡単に使用できます。
したがって、データを入手したら、データの内容の表示に移りましょう。 データの最初のビューを取得するには、df.infoやdf.describeなどの関数を使用して、データセットの構造を知ることができます。
data_df.info()
data_df.describe()
データセットに含まれる機能がわかったら、それらの値を確認することをお勧めします。 df.head()関数を使用して、最初の5つのサンプルを取得できます。
data_df.head()
#また
data_df.head(3)
サンプル数を指定して、デフォルト値の5をオーバーライドすることもできます。df.tail()関数を使用して、データセットの最後の5つの値を取得することもできます。
data_df.tail()
これは、データがどのように見えるかについての概要を把握するためだけのものです。 準備ができたら、Matplotlibを使用して主要なデータ視覚化タスクを開始できます。 次のコードをパンチして、プロットをインタラクティブにし、ノートブック自体で同じものを表示します。
%matplotlibインライン
matplotlibの上位5つの視覚化の機能が表示されます。 それに入る前に、プロットを制御する他のいくつかの関数を知っておく必要があります。 次のような機能:
- ラベル:xlabel()、ylabel()。 これらは、x軸とy軸のラベル用です。
- 凡例:プロットの凡例を作成するために使用されます。
- タイトル:プロットにタイトルを割り当てるには
- そして最後に、プロットを表示する関数を表示します。
チェックアウト:インドのデータアナリスト給与
視覚化
ここで視覚化を見てみましょう。 基本的なプロットから始めます。 plt.plot()は、データの単純な折れ線グラフを生成するために使用されます。 この関数には、強制的に2つのパラメーターが必要です。これらは、x軸データとy軸データです。 オプションで、プロットのスタイルと名前および色を指定できます。 これがコードでどのように見えるかです。
plt.plot(data_df ['chol'])
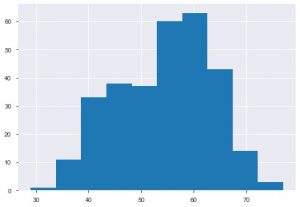
2番目のプロットはヒストグラムです。 ヒストグラムは、特定の機能の頻度または分布を表示するのに役立ちます。 数量が互いにどのように関連しているかを確認するのに役立ちます。 Plt.hist()は、データにヒストグラムを作成するための基本関数です。 binsパラメーターに言及して、プロット上の数値を制御できます。 単変量分析が必要な場合にのみ、単一軸データを渡す必要があります。

plt.hist(data_df ['age'])
よく目にするもう1つのプロットは、棒グラフです。 さまざまな機能の分析と比較に役立ちます。 ヒストグラムとは異なり、棒グラフはカテゴリデータの操作に使用されます。
プロットをDataFrameに直接適用することも、plt.bar()関数内でパラメーターを指定することもできます。 これが私たちの使い方です。
df = pd.DataFrame(np.random.rand(15、5)、columns = ['t1'、't2'、't3'、't4'、't5'])
df.plot.bar()
barh()関数を使用して、棒グラフを水平方向に使用することもできます。
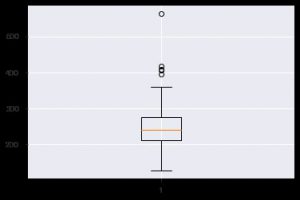
もう1つの洞察に満ちたグラフは、箱ひげ図です。 これは、各機能内の値の分布を理解するのに役立ちます。 plt.boxplot()関数を使用して、箱ひげ図を生成するデータを指定できます。 プロットは、データセットの分散または歪度をすばやく表示する必要がある場合に特に役立ちます。 使い方は次のとおりです。
plt.boxplot(data_df ['chol'])
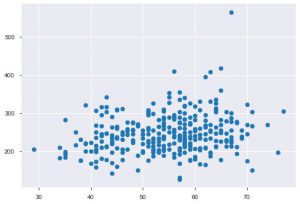
統計データを操作するときはいつでも、散布図が確実に表示されます。 散布図は、2つの特徴間の関係を観察するのに役立ちます。 プロットには、x軸データとy軸の両方の数値が必要です。 これらの2つの値をplt.scatter()関数で指定するか、x属性とy属性で列名を指定してDataFrameに直接適用することができます。 これを使用する方法は次のとおりです。
plt.scatter(data_df ['age']、data_df ['chol'])
今こそ、Seabornの機能を紹介するのにふさわしい時期です。 seabornの散布図は、デフォルトでプロットに回帰直線を提供し、プロットをより適切に視覚化できるため、matplotlibよりも直感的です。 sns.lmplot()関数を使用して、そのプロットを作成できます。
sns.lmplot('age'、'chol'、data = data_df)
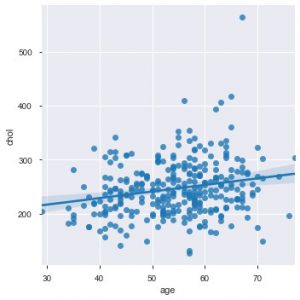
上のプロットでわかるように、回帰直線は分布をさらによく理解するのに役立ちます。
シーボーンを使用したもう1つの改善点は、群れのプロットです。 これは、カテゴリ散布図を描画するために使用されます。 同様のストリッププロットに対するスウォームプロットの利点の1つは、重複しないポイントのみを使用することです。 したがって、それはよりクリーンなプロットであり、したがってより良い洞察を提供します。
sns.swarmplot(data_df ['age']、data_df ['chol'])
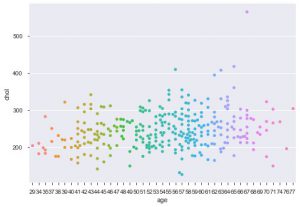
したがって、これらはMatplotlibとSeabornのさまざまなタイプのプロットです。 これは氷山の一角に過ぎず、データをプロットしてそれに関する創造的な洞察を抽出する方法は他にも何百もあります。
プロットがわかったので、 Pythonを使用して実際のデータ分析を行う方法を見てみましょう。 さらにいくつかのプロットを見て、 Pythonを使用したデータ分析についてそれらが何を示しているかを確認します。
はじめましょう。
データを読み込んだ後、データアナリストが最初に行うことは、パンダのプロファイルを作成することです。 これはショートカットとしても表示できますが、データセット内の変数のすべての関係とカウントおよびヒストグラムを表示したい場合は、パンダプロファイリングを使用できます。 生成は非常に簡単です。pandas-profilingモジュールをダウンロードして、次のコードを入力するだけです。
pandas_profilingをインポートします
プロファイル=pandas_profiling.ProfileReport(data_df)
プロフィール
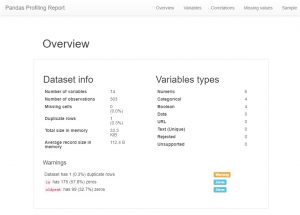
ご覧のとおり、膨大な量のメタデータ情報と個々の機能情報があります。 これらはいくつかの素晴らしい理解につながる可能性があります。
次にできることは、ヒートマップを生成することです。 ヒートマップが行うことは、各機能と他の機能との相関関係を示しています。 そして、より高い相関のある値を見つけた場合、それは2つの機能が互いに非常に似ていることを意味します。 したがって、機能の1つを削除しても、モデルは正常に機能します。
sns.heatmap(data_df.corr()、annot = True 、cmap ='Oranges')
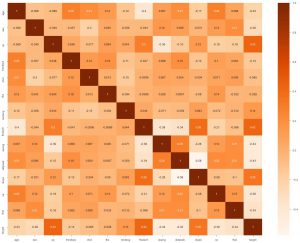
ここでは、関連性の高いものがないことがわかります。したがって、入力としてすべての機能が必要であることをモデルエンジニアに伝えることができます。
心臓病のデータセットを扱っているため、年齢分布を確認できます。分布を確認して、海生まれの分布を使用できるようにします。
sns.distplot(data_df ['age']、color ='cyan')
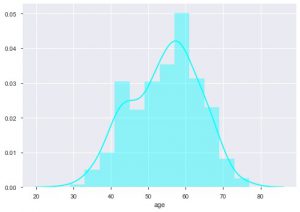
プロットから、心臓病に苦しむほとんどの人は50歳から60歳の間であると言うことができます。同様に、tresbpsで示される安静時血圧のような他のいくつかの重要な特徴も見ることができます。 箱ひげ図を作成して、目標値、つまり0と1と比較した分布を確認できます。
sns.boxplot(data_df ['target']、data_df ['trestbps']、palette ='twilight')
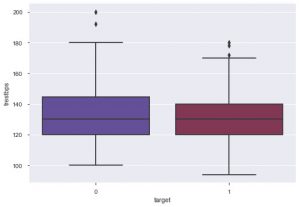
プロットから、その人のtres bpsが低い場合、心臓病に苦しむ可能性は、tresbpsの値が高い人よりも低いと結論付けることができます。
同様に、コレステロール値との関係もわかります。 コレステロール値が低い人は心臓病にかかる可能性が低いことがわかります。
これらすべての洞察を文書化し、それを機械学習エンジニアに提供して、効率的なモデルを作成するために同じものを使用することができます。
結論
したがって、これは、 Pythonを使用してデータ分析を行う方法です。 これは、データサイエンスの旅の最初のステップにすぎません。 データおよび全体的なデータサイエンスから創造的な洞察を抽出する方法の詳細については、upGradが提供するコースをご覧ください。 Pythonを使用したデータ分析を効果的にガイドするさまざまな役立つコースがあります。
世界のトップ大学からデータサイエンスコースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
データ分析のためにPythonを学ぶにはどうすればよいですか?
あなたがデータ分析のためのPythonを学ぶ道を進んでいるなら、あなたは正しい場所にいます。 何に対しても学習プロセスを簡単にするために、段階的なアプローチが必要です。 プロセスは次のようになります。
1. Pythonを学習する目的と、Pythonを自分の分野でどのように使用できるかを明確にします。
2.必要なPythonターミナルをダウンロードして、システムにインストールします。
3.さまざまなコースを受講し、さまざまなPythonライブラリを理解して、Pythonの基本を学び始めます。
4.Pythonで使用されている正規表現に慣れます。
5. Pandas、NumPy、Matplotlib、SciPyなどのさまざまなPythonライブラリの詳細な知識を習得します。
6.データ分析の概念と、Pythonを統合する方法の学習を開始します。
7.これで、Python for Data Analysisをより良くするために、さまざまなツールとテクニックを練習し続ける必要があります。 この段階的なアプローチを実行することで、Pythonを習得し、データ分析をより上手に活用できるようになります。
Pythonはデータ分析にどのように使用されますか?
Pythonは、データ分析にとって非常に重要なリソースであることが知られています。 Pythonは、データ分析を実行するためにさまざまな方法で役立ちます。 ただし、その前に、分析用のデータを準備し、統計分析を実行し、洞察を提供できるデータの視覚化を作成し、利用可能なデータに基づいて将来の傾向を予測する必要があります。
Pythonは、次の点で役立つため、データ分析の重要な要素であることがわかります。
1.データセットのインポート
2.分析を実行するためのデータのクリーニングと準備
3.PandasDataFrameの操作
4.データセットの要約
5.Pythonを使用したデータ分析のための機械学習モデルの開発
1か月でPythonを学ぶことはできますか?
はい、Java、C、C ++などの他のプログラミング言語に精通していれば、間違いなくこれを実現できます。ベースが明確であれば、1か月でもPythonを学ぶのは非常に簡単です。 それ以外に、努力を惜しまず、規律ある方法で段階的なアプローチに従うと、他のプログラミング言語の予備知識がなくても、1か月でPythonを学ぶことができます。 スケジュールを設定し、1か月でPythonの学習に専念する必要があります。