
베이지안 머신 러닝 – 통계 데이터 모델링의 패러다임 전환 탐색
게시 됨: 2020-11-24목차
베이지안 머신 러닝이란 무엇입니까?
Bayesian Machine Learning(Bayesian ML이라고도 함)은 Bayes' Theorem을 기반으로 통계 모델을 구성하는 체계적인 접근 방식입니다.
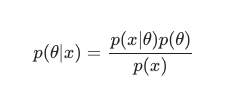 모든 표준 기계 학습 문제에는 분석이 필요한 두 가지 기본 데이터 세트가 포함됩니다.
모든 표준 기계 학습 문제에는 분석이 필요한 두 가지 기본 데이터 세트가 포함됩니다.
- 포괄적인 훈련 데이터 세트
- 사용 가능한 모든 입력 및 기록된 모든 출력 모음
모델링을 위해 이 데이터를 분석하는 전통적인 접근 방식은 이러한 데이터 세트 간에 매핑할 수 있는 몇 가지 패턴을 결정하는 것입니다. 분석가는 일반적으로 모델을 함께 연결하여 이들 간의 매핑을 결정하고 결과 접근 방식은 대상 변수에 대한 예측을 생성하는 매우 결정론적인 방법입니다.
유일한 문제는 명확한 정의 세트로 이 모델 내부 에서 일어나는 일을 설명할 방법이 전혀 없다는 것입니다 . 본질적으로 달성되는 모든 것은 훈련 데이터 세트의 일부 손실 함수를 최소화하는 것입니다. 그러나 이는 진정한 모델링에 적합하지 않습니다.
이상적인(및 바람직하게는 무손실) 모델은 수학적 확률의 언어로 정의 및 방어할 수 있는 통계적 부활절 달걀(예: 신뢰 구간)로 보완된 모델 고유 매개변수의 객관적인 요약을 수반합니다. 이 "이상적인" 시나리오는 베이지안 머신 러닝이 달성하고자 하는 것입니다.
베이지안 머신 러닝의 목표(그리고 마법)
베이지안 머신 러닝의 주요 목적은 가능성 (훈련 데이터의 파생 추정치)과 사전 분포 를 고려 하여 사후 분포 를 추정하는 것 입니다.

일반 머신 러닝 모델을 훈련할 때 이것이 바로 이론과 실습에서 우리가 하는 일입니다. 분석가는 훈련 데이터에 대해 최대 가능성 추정 의 연속적인 반복을 수행하여 훈련 데이터를 볼 확률을 최대화하는 방식으로 모델의 매개변수를 업데이트하는 것으로 알려져 있습니다 이것은 Bayesian Machine Learning이 아름답게 해결하는 것을 목표로 하는 닭과 달걀 문제로 이어집니다.
분석가 가 사후 분포 를 이 과정 을 MAP 으로 줄여서 Maximum A Posteriori 라고 합니다. 이 개념을 이해하는 더 쉬운 방법은 가능성 함수 의 관점에서 생각하는 것입니다 .
Bayes' theorem 을 고려 하면 사후분포는 다음과 같이 정의될 수 있습니다.
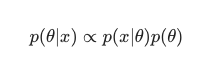
이 시나리오에서는 분모를 단순한 중복 방지 조치로 생략합니다. 모델에 의존하지 않는 모든 것은 최대화 절차에서 무시할 수 있습니다. 이 퍼즐의 핵심 조각인 사전 배포는 베이지안 모델이 고전적인 MLE로 훈련된 모델과 대조적으로 눈에 띄게 하는 것입니다.
분석가는 종종 특정 매개변수 구성이 얼마나 적합한지에 대해 합리적인 가정을 할 수 있으며, 이는 실시간으로 보기 전에도 이러한 매개변수에 대한 믿음을 인코딩하는 데 큰 도움이 됩니다. 예를 들어 모델의 매개변수보다 먼저 가우시안을 사용하는 것은 비교적 일반적입니다.

여기에서 분석가는 이러한 매개변수가 평균과 분산이 모두 표시되는 정규 분포에서 추출되었다고 가정합니다. 이러한 종류의 분포는 평균에 인상적으로 가까운 질량의 상당 부분을 통합하는 고전적인 종 곡선 모양을 특징으로 합니다.
반면에 꼬리 끝쪽으로 값이 발생하는 경우는 매우 드뭅니다. 이러한 사전의 사용은 모델의 가중치의 대부분이 정의된 좁은 범위 내에서 맞아야 하고, 극히 일부 예외적인 이상값이 있는 평균값에 매우 가까워야 한다는 믿음을 효과적으로 나타 냅니다 . 이는 현실 세계의 현상과 비이상적인 상황을 고려하여 추구해야 할 합리적인 믿음입니다.
그러나 베이지안 모델의 효과는 이러한 사전 분포(및 MAP 프로세스)의 사용이 고전적 의미에서 MLE를 수행하여 해결된 결과와 같지 않더라도 엄청나게 유사한 결과를 생성 한다는 것을 관찰할 때 훨씬 더 흥미로웠습니다. 일부 추가된 정규화에 도움이 되었습니다.
"허용된" 모델 가중치를 이전 가중치로 제한함으로써 결국 정규화기를 생성하게 된다는 점에 주목하는 것은 매우 재미있습니다.
전반적으로 베이지안 머신 러닝은 머신 러닝의 하위 분야로 빠르게 진화하고 있으며, 기존 표준으로의 추가 개발 및 진출은 계산 및 통계 하드웨어의 현재 발전 속도의 다소 자연스럽고 가능성 있는 결과로 보입니다.
읽기: 베이지안 네트워크
베이지안 머신 러닝의 다양한 방법
베이지안 머신 러닝에는 크게 세 가지 접근 방식, 즉 MAP , MCMC 및 "가우시안" 프로세스가 있습니다.
MAP을 사용한 베이지안 머신 러닝: 최대 A 사후
MAP 은 진정한 베이지안 머신 러닝을 향한 첫 번째 단계라는 구별을 즐깁니다. 그러나 경험 많은 통계학자들이 일반적으로 언급하는 점 추정치와 같이 기초적인 것을 계산하는 능력에는 한계가 있습니다.
점 추정의 문제는 최적 설정 이외의 매개변수에 대해 많이 밝히지 않는다는 것입니다. 분석가와 통계학자는 종종 추가 핵심 가치 정보(예 : 특정 매개변수 값이 미리 정의된 범위에 들어갈 확률)를 추구합니다. 결국 베이지안 머신 러닝의 진정한 예측력은 바로 여기에 있습니다.
MCMC를 사용한 베이지안 머신 러닝: Markov Chain Monte Carlo
일반적으로 MCMC라고도 알려진 Markov Chain Monte Carlo는 Gibbs 및 Slice Sampling과 같은 유명한 보조 방법 집합을 통해 적용되는 유명하고 유명한 "우산" 알고리즘입니다.
MCMC의 수학은 일반적으로 어렵다고 여겨지지만 여전히 흥미롭고 인상적입니다. 이러한 보조 방법의 절정은 알려진 Markov 체인의 구성으로, 사후에 해당하는 분포로 추가로 안착됩니다.
많은 후속 알고리즘이 분석가가 매개변수 공간을 더 효율적으로 탐색할 수 있도록 하기 위해 기울기 정보를 포함하여 MCMC 방법을 개선하기로 결정했습니다.
그러나 이 정확도를 달성하는 더 간단한 방법이 있습니다. 예를 들어 분석가가 Laplace Approximation 을 사용하는 베이지안 선형 및 로지스틱 회귀 분석이 있습니다 . 사후 분포에 대한 분석적 근사 (종이에서 설명할 수 있음)는 이 프로세스를 구분하는 요소입니다.
반드시 읽어야 함: Naive Bayes 설명
가우스 프로세스를 사용한 베이지안 머신 러닝
가우시안 프로세스 는 확률적 프로세스이며 모든 구성 확률 변수에 엄격한 가우스 조건이 적용됩니다. 가능한 모든 라인의 공간에 대한 확률 분포를 결정한 다음 데이터를 고려하여 실제 예측 변수가 될 가능성이 가장 높은 라인을 선택하여 작동합니다.
이러한 프로세스를 통해 분석가는 기능 공간에서 회귀를 수행할 수 있습니다. 전체 사후 분포 가 이 방법에서 분석적으로 계산 된다는 점을 감안할 때 이것은 의심할 여지 없이 가장 정확한 베이지안 추정이므로 통계적으로나 논리적으로 가장 훌륭합니다.
기계 학습 및 인공 지능 분야의 경력에 대해 더 알고 싶다면 IIT Madras와 upGrad의 기계 학습 및 클라우드 고급 인증을 확인하십시오.