
Aggiunta di una nuova colonna al dataframe esistente in Panda [2022]
Pubblicato: 2021-01-06Python, un linguaggio di programmazione interpretato, generico e di alto livello, è recentemente diventato un linguaggio informatico fenomenale grazie alla sua vasta collezione di librerie e alla natura facile da implementare. La popolarità di Python ha fatto un enorme balzo in avanti con l'implementazione della scienza dei dati e dell'analisi dei dati. Esistono migliaia di librerie che possono essere integrate con Python per farlo funzionare in modo efficiente su qualsiasi verticale.
Pandas è una di queste librerie di analisi dei dati progettata esplicitamente per Python per eseguire la manipolazione e l'analisi dei dati. La libreria Pandas è costituita da specifiche strutture di dati e operazioni per gestire tabelle numeriche, analizzare dati e lavorare con serie temporali. In questo articolo imparerai come aggiungere colonne a DataFrame in Panda che già esiste.
Leggi: Pandas Dataframe Astype
Sommario
Cos'è DataFrame?
Prima di sapere come aggiungere una nuova colonna al DataFrame esistente , diamo prima un'occhiata a DataFrames in Pandas . DataFrame è una struttura dati mutevole sotto forma di un array bidimensionale in grado di memorizzare valori eterogenei con assi etichettati (righe e colonne). DataFrame è una struttura di dati in cui i dati rimangono archiviati in una disposizione logica di modo tabulare (righe e colonne che si intersecano). I tre componenti principali di un DataFrame sono righe, colonne e dati. Creare un DataFrame in Python è molto semplice.
importa panda come pd
l = ['Questo', 'è', 'a', 'Elenco', 'preparazione', 'per', 'DataFrame']
datfr = pd.DataFrame(l)
stampa(datfr)
Il programma sopra creerà un DataFrame di 7 righe e una colonna.

Come aggiungere colonne ai frame di dati esistenti?
Esistono vari modi per aggiungere nuove colonne a un DataFrame in Pandas . Abbiamo già raccolto un'idea su come creare un DataFrame di base utilizzando la libreria Pandas . Prepariamo ora una libreria già esistente e lavoriamo su di essa.
importa panda come pd
# Definire un dizionario contenente i dati dei Professionisti
datfr = {'Nome': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altezza': [6.2, 5.7, 6.1, 5.9],
'Designazione': ['Scienziato', 'Professore', 'Analista dati', 'Analista sicurezza']}
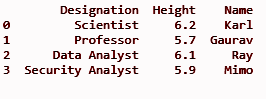
df = pd.DataFrame(datfr)
stampa (df)
Produzione:
Leggi: Tutorial Python Pandas
Tecnica 1: metodo insert()
Ora, per aggiungere nuove colonne al DataFrame esistente, dobbiamo usare il metodo insert(). Prima di implementare il metodo insert(), informaci sul suo funzionamento. DataFrame.insert() consente di aggiungere una colonna in qualsiasi posizione l'analista di dati desidera. Comprende anche diverse possibilità per inserire i valori delle colonne. I programmatori possono specificare l'indice per inserire la colonna di dati in quella particolare posizione.
importa panda come pd
# Definire un dizionario contenente i dati dei Professionisti
datfr = {'Nome': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altezza': [6.2, 5.7, 6.1, 5.9],
'Designazione': ['Scienziato', 'Professore', 'Analista dati', 'Analista sicurezza']}
df = pd.DataFrame(datfr)
df.insert(3, “Età”, [40, 33, 27, 26], Vero)
stampa (df)
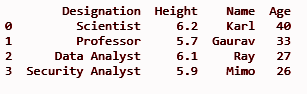
Aggiungerà la colonna 'Età' nella terza posizione dell'indice come definito nel metodo insert() come primo parametro.
Tecnica 2: metodo assign()
Un altro metodo per aggiungere una colonna a DataFrame utilizza il metodo assign() della libreria Pandas. Questo metodo usa un approccio diverso per aggiungere una nuova colonna al DataFrame esistente. Dataframe.assign() creerà un nuovo DataFrame insieme a una colonna. Quindi lo aggiungerà al DataFrame esistente.

importa panda come pd
datfr = {'Nome': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altezza': [6.2, 5.7, 6.1, 5.9],
'Designazione': ['Scienziato', 'Professore', 'Analista dati', 'Analista sicurezza']}
dfI = pd.DataFrame(datfr)
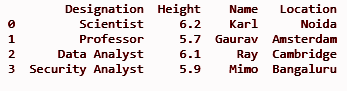
dfII = dfI.assign(Location = ['Noida', 'Amsterdam', 'Cambridge', 'Bangaluru'])
stampa(dfII)
PRODUZIONE:
Tecnica 3: creazione di un nuovo elenco come colonna
L'ultimo metodo che i programmatori possono utilizzare per aggiungere una colonna a DataFrame consiste nel generare un nuovo elenco come colonna di dati separata e aggiungere la colonna al DataFrame esistente.
importa panda come pd
datfr = {'Nome': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altezza': [6.2, 5.7, 6.1, 5.9],
'Designazione': ['Scienziato', 'Professore', 'Analista dati', 'Analista sicurezza']}
df = pd.DataFrame(datfr)
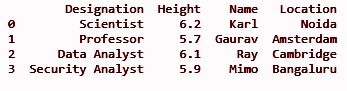
loc = ['Noida', 'Amsterdam', 'Cambridge', 'Bangaluru']
df['Posizione'] = loc
stampa (df)
PRODUZIONE:
Checkout: Domande sull'intervista di Pandas
Conclusione
Gli analisti di dati eseguono un'operazione principale per aggiungere un ulteriore set di dati in un formato a colonne. Esistono diversi approcci che un analista di dati o un programmatore possono utilizzare per aggiungere una nuova colonna a un DataFrame esistente in Pandas. Questi metodi renderanno i programmatori a portata di mano per aggiungere colonne di dati in qualsiasi momento durante l'analisi dei dati di Pandas.
Se sei curioso di conoscere DataFrame in Pandas, dai un'occhiata all'Executive PG Program in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1 contro 1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Perché Pandas è una delle librerie preferite per creare frame di dati in Python?
La libreria Pandas è considerata la più adatta per la creazione di frame di dati poiché fornisce varie funzionalità che rendono efficiente la creazione di un frame di dati. Alcune di queste funzionalità sono le seguenti: i Panda ci forniscono vari frame di dati che non solo consentono una rappresentazione efficiente dei dati, ma ci consentono anche di manipolarli. Fornisce funzionalità di allineamento e indicizzazione efficienti che forniscono metodi intelligenti per etichettare e organizzare i dati. Alcune funzionalità di Panda rendono il codice pulito e ne aumentano la leggibilità, rendendolo così più efficiente. Può anche leggere più formati di file. JSON, CSV, HDF5 ed Excel sono alcuni dei formati di file supportati da Pandas. La fusione di più set di dati è stata una vera sfida per molti programmatori. I panda superano anche questo e uniscono più set di dati in modo molto efficiente. Pandas fornisce anche l'accesso ad altre importanti librerie Python come Matplotlib e NumPy, il che la rende una libreria altamente efficiente.
Quali sono le altre librerie Python con cui funziona la libreria Pandas?
Pandas non funziona solo come libreria centrale per la creazione di frame di dati, ma funziona anche con altre librerie e strumenti di Python per essere più efficiente. Pandas è basato sul pacchetto NumPy Python che indica che la maggior parte della struttura della libreria Pandas viene replicata dal pacchetto NumPy. L'analisi statistica sui dati nella libreria Pandas è gestita da SciPy, tracciando funzioni su Matplotlib e algoritmi di apprendimento automatico in Scikit-learn. Jupyter Notebook è un ambiente interattivo basato sul Web che funziona come IDE e offre un buon ambiente per Panda.
Insieme all'inserimento, quali sono le operazioni fondamentali del Dataframe?
È importante selezionare un indice o una colonna prima di iniziare qualsiasi operazione come l'aggiunta o l'eliminazione. Dopo aver appreso come accedere ai valori e selezionare le colonne da un Data Frame, puoi imparare ad aggiungere un indice, una riga o una colonna in un Pandas Dataframe. Se l'indice nel frame di dati non risulta essere quello desiderato, è possibile reimpostarlo. Per ripristinare l'indice, puoi utilizzare la funzione "reset_index()".