
Adăugarea unei noi coloane la cadrul de date existent în Pandas [2022]
Publicat: 2021-01-06Python, un limbaj de programare interpretat, de uz general, de nivel înalt, a devenit recent un limbaj de calcul fenomenal datorită colecției sale vaste de biblioteci și a naturii ușor de implementat. Popularitatea lui Python a făcut un salt enorm odată cu implementarea științei datelor și a analizei datelor. Există mii de biblioteci care pot fi integrate cu Python pentru ca acesta să funcționeze eficient pe orice verticală.
Pandas este o astfel de bibliotecă de analiză a datelor concepută în mod explicit pentru ca Python să efectueze manipularea și analiza datelor. Biblioteca Pandas constă din structuri de date și operațiuni specifice pentru a se ocupa de tabele numerice, de a analiza date și de a lucra cu serii de timp. În acest articol, veți afla cum să adăugați coloane la DataFrame în Pandas care există deja.
Citiți: Pandas Dataframe Astype
Cuprins
Ce este DataFrame?
Înainte de a ști cum să adăugați o nouă coloană la DataFrame existent , mai întâi să aruncăm o privire asupra DataFrame-urilor din Pandas . DataFrame este o structură de date mutabilă sub forma unei matrice bidimensionale care poate stoca valori eterogene cu axe etichetate (rânduri și coloane). DataFrame este o structură de date în care datele rămân stocate într-un aranjament logic de formă tabelară (intersectarea rândurilor și coloanelor). Cele trei componente majore ale unui DataFrame sunt rândurile, coloanele și datele. Crearea unui DataFrame în Python este foarte ușoară.
importa panda ca pd
l = [„Acesta”, „este”, „a”, „Lista”, „pregătire”, „pentru”, „Cadru de date”]
datfr = pd.DataFrame(l)
print(datfr)
Programul de mai sus va crea un DataFrame de 7 rânduri și o coloană.

Cum să adăugați coloane la cadrele de date existente?
Există diferite moduri de a adăuga coloane noi la un DataFrame în Pandas . Am adunat deja o idee despre cum să creăm un DataFrame de bază folosind biblioteca Pandas . Să pregătim acum o bibliotecă deja existentă și să lucrăm la ea.
importa panda ca pd
# Definiți un dicționar care să conțină datele profesioniștilor
datfr = {'Nume': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
„Înălțime”: [6,2, 5,7, 6,1, 5,9],
„Desemnare”: [„Scientist”, „Professor”, „Data Analyst”, „Security Analyst”]}
df = pd.DataFrame(datfr)
print(df)
Ieșire:
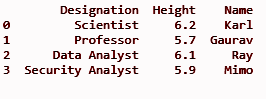
Citiți: Tutorial Python Pandas
Tehnica 1: Metoda insert().
Acum, pentru a adăuga coloane noi la DataFrame existent, trebuie să folosim metoda insert(). Înainte de a implementa metoda insert(), anunțați-ne despre funcționarea acesteia. DataFrame.insert() permite adăugarea unei coloane în orice poziție pe care dorește analistul de date. De asemenea, găzduiește mai multe posibilități de injectare a valorilor coloanei. Programatorii pot specifica indexul pentru a injecta coloana de date în acea poziție specială.
importa panda ca pd
# Definiți un dicționar care să conțină datele profesioniștilor
datfr = {'Nume': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
„Înălțime”: [6,2, 5,7, 6,1, 5,9],
„Desemnare”: [„Scientist”, „Professor”, „Data Analyst”, „Security Analyst”]}
df = pd.DataFrame(datfr)
df.insert(3, „Vârsta”, [40, 33, 27, 26], Adevărat)
print(df)
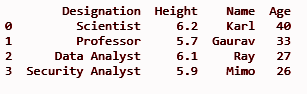
Va adăuga coloana „Vârsta” în a treia poziție de index, așa cum este definită în metoda insert() ca prim parametru.
Tehnica 2: Metoda assign().
O altă metodă de a adăuga o coloană la DataFrame este utilizarea metodei assign() a bibliotecii Pandas. Această metodă folosește o abordare diferită pentru a adăuga o nouă coloană la DataFrame existent. Dataframe.assign() va crea un nou DataFrame împreună cu o coloană. Apoi îl va adăuga la DataFrame-ul existent.

importa panda ca pd
datfr = {'Nume': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
„Înălțime”: [6,2, 5,7, 6,1, 5,9],
„Desemnare”: [„Scientist”, „Professor”, „Data Analyst”, „Security Analyst”]}
dfI = pd.DataFrame(datfr)
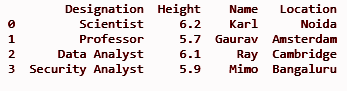
dfII = dfI.assign(Locație = ['Noida', 'Amsterdam', 'Cambridge', 'Bangaluru'])
print(dfII)
IEȘIRE:
Tehnica 3: Crearea unei noi liste ca coloană
Ultima metodă pe care programatorii o pot folosi pentru a adăuga o coloană la DataFrame este prin generarea unei noi liste ca o coloană separată de date și prin adăugarea coloanei la DataFrame existent.
importa panda ca pd
datfr = {'Nume': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
„Înălțime”: [6,2, 5,7, 6,1, 5,9],
„Desemnare”: [„Scientist”, „Professor”, „Data Analyst”, „Security Analyst”]}
df = pd.DataFrame(datfr)
loc = ['Noida', 'Amsterdam', 'Cambridge', 'Bangaluru']
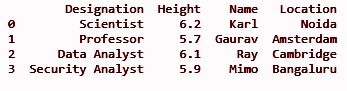
df['Locația'] = loc
print(df)
IEȘIRE:
Checkout: Întrebări la interviu Pandas
Concluzie
Analiștii de date efectuează o operațiune principală pentru adăugarea unui set suplimentar de date într-o formă de coloane. Există diferite abordări pe care un analist de date sau un programator le poate folosi pentru a adăuga o nouă coloană la un DataFrame existent în Pandas. Aceste metode vor face programatorii la îndemână să adauge coloane de date în orice moment în timp ce analizează datele Pandas.
Dacă sunteți curios să aflați despre DataFrame în Pandas, consultați Programul Executive PG în știința datelor de la IIIT-B și upGrad, care este creat pentru profesioniști care lucrează și oferă peste 10 studii de caz și proiecte, ateliere practice practice, mentorat cu experți din industrie, 1-la-1 cu mentori din industrie, peste 400 de ore de învățare și asistență profesională cu firme de top.
De ce este Pandas una dintre cele mai preferate biblioteci pentru a crea cadre de date în Python?
Biblioteca Pandas este considerată a fi cea mai potrivită pentru crearea de cadre de date, deoarece oferă diverse caracteristici care fac eficientă crearea unui cadru de date. Unele dintre aceste caracteristici sunt următoarele - Pandas ne oferă diverse cadre de date care nu numai că permit o reprezentare eficientă a datelor, dar ne permit și să le manipulăm. Oferă funcții eficiente de aliniere și indexare care oferă modalități inteligente de etichetare și organizare a datelor. Unele caracteristici ale Pandas fac codul curat și îi sporesc lizibilitatea, făcându-l astfel mai eficient. De asemenea, poate citi mai multe formate de fișiere. JSON, CSV, HDF5 și Excel sunt unele dintre formatele de fișiere acceptate de Pandas. Fuzionarea mai multor seturi de date a fost o adevărată provocare pentru mulți programatori. Pandas depășesc acest lucru și îmbină mai multe seturi de date foarte eficient. Pandas oferă, de asemenea, acces la alte biblioteci importante Python, cum ar fi Matplotlib și NumPy, ceea ce o face o bibliotecă foarte eficientă.
Care sunt celelalte biblioteci Python cu care lucrează biblioteca Pandas?
Pandas nu numai că funcționează ca o bibliotecă centrală pentru crearea cadrelor de date, dar funcționează și cu alte biblioteci și instrumente Python pentru a fi mai eficient. Pandas este construit pe pachetul NumPy Python, ceea ce indică faptul că cea mai mare parte a structurii bibliotecii Pandas este replicată din pachetul NumPy. Analiza statistică a datelor din biblioteca Pandas este operată de SciPy, funcții de trasare pe Matplotlib și algoritmi de învățare automată în Scikit-learn. Jupyter Notebook este un mediu interactiv bazat pe web care funcționează ca IDE și oferă un mediu bun pentru Pandas.
Alături de inserare, care sunt operațiunile fundamentale ale Dataframe-ului?
Selectarea unui index sau a unei coloane înainte de a începe orice operațiune, cum ar fi adăugarea sau ștergerea, este importantă. Odată ce învățați cum să accesați valori și să selectați coloane dintr-un cadru de date, puteți învăța să adăugați index, rând sau coloană într-un cadru de date Pandas. Dacă indexul din cadrul de date nu iese așa cum doriți, îl puteți reseta. Pentru resetarea indexului, puteți utiliza funcția „reset_index()”.