
Adicionando nova coluna ao dataframe existente no Pandas [2022]
Publicados: 2021-01-06Python, uma linguagem de programação interpretada, de propósito geral e de alto nível, tornou-se recentemente uma linguagem de computação fenomenal devido à sua vasta coleção de bibliotecas e natureza fácil de implementar. A popularidade do Python deu um salto enorme com a implementação da ciência de dados e análise de dados. Existem milhares de bibliotecas que podem ser integradas ao Python para que funcione em qualquer vertical com eficiência.
Pandas é uma dessas bibliotecas de análise de dados projetada explicitamente para Python realizar manipulação e análise de dados. A biblioteca Pandas consiste em estruturas de dados e operações específicas para lidar com tabelas numéricas, analisar dados e trabalhar com séries temporais. Neste artigo, você conhecerá como adicionar colunas ao DataFrame em Pandas que já existe.
Leia: Pandas Dataframe Astype
Índice
O que é DataFrame?
Antes de saber como adicionar uma nova coluna ao DataFrame existente , vamos primeiro dar uma olhada nos DataFrames no Pandas . DataFrame é uma estrutura de dados mutável na forma de uma matriz bidimensional que pode armazenar valores heterogêneos com eixos rotulados (linhas e colunas). DataFrame é uma estrutura de dados onde os dados permanecem armazenados em um arranjo lógico de forma tabular (interseção de linhas e colunas). Os três principais componentes de um DataFrame são linhas, colunas e dados. Criar um DataFrame em Python é muito fácil.
importar pandas como pd
l = ['Este', 'é', 'a', 'Lista', 'preparando', 'para', 'DataFrame']
datfr = pd.DataFrame(l)
print(datfr)
O programa acima criará um DataFrame de 7 linhas e uma coluna.

Como adicionar colunas a DataFrames existentes?
Existem várias maneiras de adicionar novas colunas a um DataFrame no Pandas . Já reunimos uma ideia de como criar um DataFrame básico usando a biblioteca Pandas . Vamos agora preparar uma biblioteca já existente e trabalhar nela.
importar pandas como pd
# Definir um dicionário contendo os dados dos Profissionais
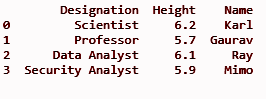
datfr = {'Nome': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altura': [6,2, 5,7, 6,1, 5,9],
'Designação': ['Cientista', 'Professor', 'Analista de Dados', 'Analista de Segurança']}
df = pd.DataFrame(datfr)
imprimir(df)
Saída:
Leia: Tutorial do Python Pandas
Técnica 1: método insert()
Agora, para adicionar novas colunas ao DataFrame existente, temos que usar o método insert(). Antes de implementar o método insert(), informe-nos sobre seu funcionamento. O DataFrame.insert() permite adicionar uma coluna em qualquer posição que o analista de dados desejar. Ele também acomoda várias possibilidades para injetar os valores da coluna. Os programadores podem especificar o índice para injetar a coluna de dados nessa posição específica.
importar pandas como pd
# Definir um dicionário contendo os dados dos Profissionais
datfr = {'Nome': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altura': [6,2, 5,7, 6,1, 5,9],
'Designação': ['Cientista', 'Professor', 'Analista de Dados', 'Analista de Segurança']}
df = pd.DataFrame(datfr)
df.insert(3, “Idade”, [40, 33, 27, 26], Verdadeiro)
imprimir(df)
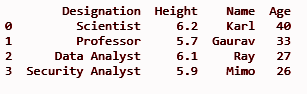
Ele adicionará a coluna 'Age' na terceira posição do índice conforme definido no método insert() como o primeiro parâmetro.
Técnica 2: método assign()
Outro método para adicionar uma coluna ao DataFrame é usar o método assign() da biblioteca Pandas. Esse método usa uma abordagem diferente para adicionar uma nova coluna ao DataFrame existente. Dataframe.assign() criará um novo DataFrame junto com uma coluna. Em seguida, ele irá anexá-lo ao DataFrame existente.

importar pandas como pd
datfr = {'Nome': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altura': [6,2, 5,7, 6,1, 5,9],
'Designação': ['Cientista', 'Professor', 'Analista de Dados', 'Analista de Segurança']}
dfI = pd.DataFrame(datfr)
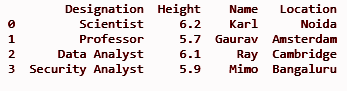
dfII = dfI.assign(Localização = ['Noida', 'Amsterdam', 'Cambridge', 'Bangaluru'])
imprimir(dfII)
SAÍDA:
Técnica 3: Criando Nova Lista como Coluna
O último método que os programadores podem usar para adicionar uma coluna ao DataFrame é gerar uma nova lista como uma coluna separada de dados e anexar a coluna ao DataFrame existente.
importar pandas como pd
datfr = {'Nome': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altura': [6,2, 5,7, 6,1, 5,9],
'Designação': ['Cientista', 'Professor', 'Analista de Dados', 'Analista de Segurança']}
df = pd.DataFrame(datfr)
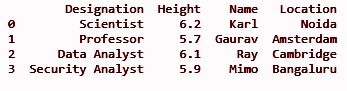
loc = ['Noida', 'Amsterdam', 'Cambridge', 'Bangaluru']
df['Local'] = loc
imprimir(df)
SAÍDA:
Checkout: Perguntas da entrevista do Pandas
Conclusão
Os analistas de dados realizam uma operação primária para adicionar um conjunto extra de dados em um formato de coluna. Existem diferentes abordagens que um analista de dados ou um programador pode usar para adicionar uma nova coluna a um DataFrame existente no Pandas. Esses métodos tornarão os programadores úteis para adicionar colunas de dados a qualquer momento enquanto analisam os dados do Pandas.
Se você está curioso para aprender sobre DataFrame no Pandas, confira o Programa PG Executivo em Ciência de Dados do IIIT-B & upGrad, que é criado para profissionais que trabalham e oferece mais de 10 estudos de caso e projetos, workshops práticos práticos, orientação com especialistas do setor, 1-on-1 com mentores do setor, mais de 400 horas de aprendizado e assistência de trabalho com as principais empresas.
Por que o Pandas é uma das bibliotecas mais preferidas para criar quadros de dados em Python?
A biblioteca Pandas é considerada a mais adequada para a criação de quadros de dados, pois fornece vários recursos que tornam a criação de um quadro de dados eficiente. Alguns desses recursos são os seguintes - Pandas nos fornece vários quadros de dados que não apenas permitem uma representação de dados eficiente, mas também nos permitem manipulá-los. Ele fornece recursos eficientes de alinhamento e indexação que fornecem maneiras inteligentes de rotular e organizar os dados. Alguns recursos do Pandas tornam o código limpo e aumentam sua legibilidade, tornando-o mais eficiente. Ele também pode ler vários formatos de arquivo. JSON, CSV, HDF5 e Excel são alguns dos formatos de arquivo suportados pelo Pandas. A fusão de vários conjuntos de dados tem sido um verdadeiro desafio para muitos programadores. Os pandas também superam isso e mesclam vários conjuntos de dados com muita eficiência. O Pandas também fornece acesso a outras bibliotecas Python importantes, como Matplotlib e NumPy, o que o torna uma biblioteca altamente eficiente.
Quais são as outras bibliotecas Python com as quais a biblioteca Pandas trabalha?
O Pandas não funciona apenas como uma biblioteca central para criar quadros de dados, mas também funciona com outras bibliotecas e ferramentas do Python para ser mais eficiente. Pandas é construído no pacote NumPy Python, que indica que a maior parte da estrutura da biblioteca Pandas é replicada a partir do pacote NumPy. A análise estatística dos dados na biblioteca Pandas é operada pelo SciPy, plotando funções no Matplotlib e algoritmos de aprendizado de máquina no Scikit-learn. Jupyter Notebook é um ambiente interativo baseado na web que funciona como um IDE e oferece um bom ambiente para Pandas.
Junto com a inserção, quais são as operações fundamentais do Dataframe?
Selecionar um índice ou uma coluna antes de iniciar qualquer operação como adição ou exclusão é importante. Depois de aprender a acessar valores e selecionar colunas de um Data Frame, você pode aprender a adicionar índice, linha ou coluna em um Pandas Dataframe. Se o índice no quadro de dados não for o desejado, você poderá redefini-lo. Para redefinir o índice, você pode usar a função “reset_index()”.