
在 Pandas [2022] 中向現有數據框添加新列
已發表: 2021-01-06Python 是一種解釋型、通用的高級編程語言,由於其大量的庫和易於實現的特性,它最近已成為一種現象級的計算語言。 隨著數據科學和數據分析的實施,Python 的流行發生了巨大的飛躍。 有數以千計的庫可以與 Python 集成,以使其高效地在任何垂直領域工作。
Pandas是專門為 Python 設計的數據分析庫之一,用於執行數據操作和數據分析。 Pandas庫由特定的數據結構和操作組成,用於處理數值表、分析數據和處理時間序列。 在本文中,您將了解如何在已經存在的 Pandas 中向 DataFrame 添加列。
閱讀: Pandas Dataframe Astype
目錄
什麼是數據框?
在了解如何向現有 DataFrame 添加新列之前,讓我們先了解一下Pandas中的 DataFrame。 DataFrame 是一種二維數組形式的可變數據結構,可以存儲帶有標籤軸(行和列)的異構值。 DataFrame 是一種數據結構,其中數據以表格(相交的行和列)方式的邏輯排列方式存儲。 DataFrame 的三個主要組成部分是行、列和數據。 在 Python 中創建 DataFrame 非常簡單。
將熊貓導入為 pd
l = ['This', 'is', 'a', 'List', 'preparing', 'for', 'DataFrame']
datfr = pd.DataFrame(l)
打印(datfr)
上面的程序將創建一個 7 行 1 列的 DataFrame。

如何向現有 DataFrame 添加列?
有多種方法可以在Pandas中向 DataFrame 添加新列。 我們已經收集瞭如何使用Pandas庫創建基本 DataFrame 的想法。 現在讓我們準備一個已經存在的庫並對其進行處理。
將熊貓導入為 pd
# 定義一個包含專業人士數據的字典
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'高度':[6.2, 5.7, 6.1, 5.9],
“職稱”:[“科學家”、“教授”、“數據分析師”、“安全分析師”]}
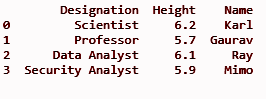
df = pd.DataFrame(datfr)
打印(df)
輸出:
閱讀: Python Pandas 教程
技巧一:insert() 方法
現在,要向現有 DataFrame 添加新列,我們必須使用 insert() 方法。 在實現 insert() 方法之前,讓我們了解它的工作原理。 DataFrame.insert() 允許在數據分析師想要的任何位置添加一列。 它還提供了幾種注入列值的可能性。 程序員可以指定索引以在該特定位置注入數據列。
將熊貓導入為 pd
# 定義一個包含專業人士數據的字典
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'高度':[6.2, 5.7, 6.1, 5.9],
“職稱”:[“科學家”、“教授”、“數據分析師”、“安全分析師”]}
df = pd.DataFrame(datfr)
df.insert(3, “年齡”, [40, 33, 27, 26], True)
打印(df)
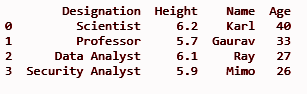

它將在 insert() 方法中定義的第三個索引位置添加“年齡”列作為第一個參數。
技巧 2:assign() 方法
向 DataFrame 添加列的另一種方法是使用 Pandas 庫的 assign() 方法。 此方法使用不同的方法向現有 DataFrame 添加新列。 Dataframe.assign() 將創建一個新的 DataFrame 以及一列。 然後它將其附加到現有的 DataFrame 中。
將熊貓導入為 pd
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'高度':[6.2, 5.7, 6.1, 5.9],
“職稱”:[“科學家”、“教授”、“數據分析師”、“安全分析師”]}
dfI = pd.DataFrame(datfr)
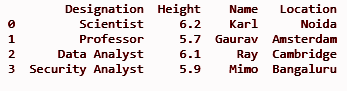
dfII = dfI.assign(位置 = ['諾伊達','阿姆斯特丹','劍橋','班加羅爾'])
打印(dfII)
輸出:
技巧 3:創建新列表作為列
程序員可以用來向 DataFrame 添加列的最後一種方法是生成一個新列表作為單獨的數據列,並將該列附加到現有 DataFrame。
將熊貓導入為 pd
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'高度':[6.2, 5.7, 6.1, 5.9],
“職稱”:[“科學家”、“教授”、“數據分析師”、“安全分析師”]}
df = pd.DataFrame(datfr)
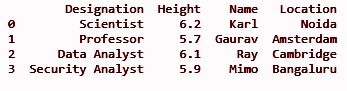
loc = ['諾伊達','阿姆斯特丹','劍橋','班加羅爾']
df['位置'] = loc
打印(df)
輸出:
結帳:熊貓面試問題
結論
數據分析師執行主要操作,以按列的形式添加一組額外的數據。 數據分析師或程序員可以使用不同的方法向 Pandas 中的現有 DataFrame 添加新列。 這些方法將使程序員在分析 Pandas 數據時可以方便地隨時添加數據列。
如果您想了解 Pandas 中的 DataFrame,請查看 IIIT-B 和 upGrad 的數據科學執行 PG 計劃,該計劃是為在職專業人士創建的,提供 10 多個案例研究和項目、實用的實踐研討會、與行業專家的指導,與行業導師一對一,400 多個小時的學習和頂級公司的工作協助。
為什麼 Pandas 是在 Python 中創建數據幀的首選庫之一?
Pandas 庫被認為最適合創建數據框,因為它提供了各種功能,可以高效地創建數據框。 其中一些功能如下 - Pandas 為我們提供了各種數據幀,這些數據幀不僅允許有效的數據表示,而且使我們能夠對其進行操作。 它提供有效的對齊和索引功能,提供標記和組織數據的智能方式。 Pandas 的一些特性使代碼更簡潔,增加了可讀性,從而提高了效率。 它還可以讀取多種文件格式。 JSON、CSV、HDF5 和 Excel 是 Pandas 支持的一些文件格式。 對於許多程序員來說,合併多個數據集是一個真正的挑戰。 Pandas 也克服了這一點,並且非常有效地合併了多個數據集。 Pandas 還提供對其他重要 Python 庫的訪問,例如 Matplotlib 和 NumPy,這使其成為一個高效的庫。
與 Pandas 庫一起使用的其他 Python 庫是什麼?
Pandas 不僅可以作為創建數據框的中央庫,還可以與 Python 的其他庫和工具一起使用以提高效率。 Pandas 是基於 NumPy Python 包構建的,這表明大部分 Pandas 庫結構都是從 NumPy 包複製而來的。 Pandas 庫中數據的統計分析由 SciPy 操作,Matplotlib 上的繪圖函數和 Scikit-learn 中的機器學習算法。 Jupyter Notebook 是一個基於 Web 的交互式環境,可用作 IDE,並為 Pandas 提供良好的環境。
除了插入,Dataframe 的基本操作是什麼?
在開始任何操作(如添加或刪除)之前選擇索引或列很重要。 一旦你學會瞭如何從數據框中訪問值和選擇列,你就可以學習在 Pandas 數據框中添加索引、行或列。 如果數據框中的索引不符合您的要求,您可以重置它。 要重置索引,您可以使用“reset_index()”函數。