
在 Pandas [2022] 中向现有数据框添加新列
已发表: 2021-01-06Python 是一种解释型、通用的高级编程语言,由于其大量的库和易于实现的特性,它最近已成为一种现象级的计算语言。 随着数据科学和数据分析的实施,Python 的流行发生了巨大的飞跃。 有数以千计的库可以与 Python 集成,以使其高效地在任何垂直领域工作。
Pandas是专门为 Python 设计的数据分析库之一,用于执行数据操作和数据分析。 Pandas库由特定的数据结构和操作组成,用于处理数值表、分析数据和处理时间序列。 在本文中,您将了解如何在已经存在的 Pandas 中向 DataFrame 添加列。
阅读: Pandas Dataframe Astype
目录
什么是数据框?
在了解如何向现有 DataFrame 添加新列之前,让我们先了解一下Pandas中的 DataFrame。 DataFrame 是一种二维数组形式的可变数据结构,可以存储带有标签轴(行和列)的异构值。 DataFrame 是一种数据结构,其中数据以表格(相交的行和列)方式的逻辑排列方式存储。 DataFrame 的三个主要组成部分是行、列和数据。 在 Python 中创建 DataFrame 非常简单。
将熊猫导入为 pd
l = ['This', 'is', 'a', 'List', 'preparing', 'for', 'DataFrame']
datfr = pd.DataFrame(l)
打印(datfr)
上面的程序将创建一个 7 行 1 列的 DataFrame。

如何向现有 DataFrame 添加列?
有多种方法可以在Pandas中向 DataFrame 添加新列。 我们已经收集了如何使用Pandas库创建基本 DataFrame 的想法。 现在让我们准备一个已经存在的库并对其进行处理。
将熊猫导入为 pd
# 定义一个包含专业人士数据的字典
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'高度':[6.2, 5.7, 6.1, 5.9],
“职称”:[“科学家”、“教授”、“数据分析师”、“安全分析师”]}
df = pd.DataFrame(datfr)
打印(df)
输出:
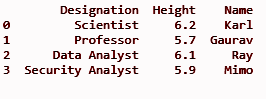
阅读: Python Pandas 教程
技巧一:insert() 方法
现在,要向现有 DataFrame 添加新列,我们必须使用 insert() 方法。 在实现 insert() 方法之前,让我们了解它的工作原理。 DataFrame.insert() 允许在数据分析师想要的任何位置添加一列。 它还提供了几种注入列值的可能性。 程序员可以指定索引以在该特定位置注入数据列。
将熊猫导入为 pd
# 定义一个包含专业人士数据的字典
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'高度':[6.2, 5.7, 6.1, 5.9],
“职称”:[“科学家”、“教授”、“数据分析师”、“安全分析师”]}
df = pd.DataFrame(datfr)
df.insert(3, “年龄”, [40, 33, 27, 26], True)
打印(df)
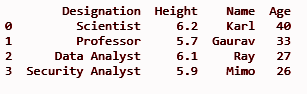

它将在 insert() 方法中定义的第三个索引位置添加“年龄”列作为第一个参数。
技巧 2:assign() 方法
向 DataFrame 添加列的另一种方法是使用 Pandas 库的 assign() 方法。 此方法使用不同的方法向现有 DataFrame 添加新列。 Dataframe.assign() 将创建一个新的 DataFrame 以及一列。 然后它将其附加到现有的 DataFrame 中。
将熊猫导入为 pd
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'高度':[6.2, 5.7, 6.1, 5.9],
“职称”:[“科学家”、“教授”、“数据分析师”、“安全分析师”]}
dfI = pd.DataFrame(datfr)
dfII = dfI.assign(位置 = ['诺伊达','阿姆斯特丹','剑桥','班加罗尔'])
打印(dfII)
输出:
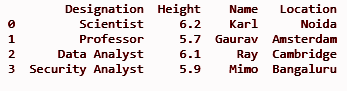
技巧 3:创建新列表作为列
程序员可以用来向 DataFrame 添加列的最后一种方法是生成一个新列表作为单独的数据列,并将该列附加到现有 DataFrame。
将熊猫导入为 pd
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'高度':[6.2, 5.7, 6.1, 5.9],
“职称”:[“科学家”、“教授”、“数据分析师”、“安全分析师”]}
df = pd.DataFrame(datfr)
loc = ['诺伊达','阿姆斯特丹','剑桥','班加罗尔']
df['位置'] = loc
打印(df)
输出:
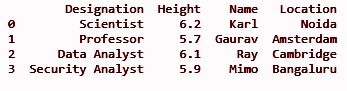
结帐:熊猫面试问题
结论
数据分析师执行主要操作,以按列的形式添加一组额外的数据。 数据分析师或程序员可以使用不同的方法向 Pandas 中的现有 DataFrame 添加新列。 这些方法将使程序员在分析 Pandas 数据时可以方便地随时添加数据列。
如果您想了解 Pandas 中的 DataFrame,请查看 IIIT-B 和 upGrad 的数据科学执行 PG 计划,该计划是为在职专业人士创建的,提供 10 多个案例研究和项目、实用的实践研讨会、与行业专家的指导,与行业导师一对一,400 多个小时的学习和顶级公司的工作协助。
为什么 Pandas 是在 Python 中创建数据帧的首选库之一?
Pandas 库被认为最适合创建数据框,因为它提供了各种功能,可以高效地创建数据框。 其中一些功能如下 - Pandas 为我们提供了各种数据帧,这些数据帧不仅允许有效的数据表示,而且使我们能够对其进行操作。 它提供有效的对齐和索引功能,提供标记和组织数据的智能方式。 Pandas 的一些特性使代码更简洁,增加了可读性,从而提高了效率。 它还可以读取多种文件格式。 JSON、CSV、HDF5 和 Excel 是 Pandas 支持的一些文件格式。 对于许多程序员来说,合并多个数据集是一个真正的挑战。 Pandas 也克服了这一点,并且非常有效地合并了多个数据集。 Pandas 还提供对其他重要 Python 库的访问,例如 Matplotlib 和 NumPy,这使其成为一个高效的库。
与 Pandas 库一起使用的其他 Python 库是什么?
Pandas 不仅可以作为创建数据框的中央库,还可以与 Python 的其他库和工具一起使用以提高效率。 Pandas 是基于 NumPy Python 包构建的,这表明大部分 Pandas 库结构都是从 NumPy 包复制而来的。 Pandas 库中数据的统计分析由 SciPy 操作,Matplotlib 上的绘图函数和 Scikit-learn 中的机器学习算法。 Jupyter Notebook 是一个基于 Web 的交互式环境,可用作 IDE,并为 Pandas 提供良好的环境。
除了插入,Dataframe 的基本操作是什么?
在开始任何操作(如添加或删除)之前选择索引或列很重要。 一旦你学会了如何从数据框中访问值和选择列,你就可以学习在 Pandas 数据框中添加索引、行或列。 如果数据框中的索引不符合您的要求,您可以重置它。 要重置索引,您可以使用“reset_index()”函数。