
Agregar nueva columna al marco de datos existente en Pandas [2022]
Publicado: 2021-01-06Python, un lenguaje de programación interpretado, de propósito general y de alto nivel, se ha convertido recientemente en un lenguaje informático fenomenal debido a su vasta colección de bibliotecas y su naturaleza fácil de implementar. La popularidad de Python dio un salto enorme con la implementación de la ciencia de datos y el análisis de datos. Hay miles de bibliotecas que se pueden integrar con Python para que funcione en cualquier vertical de manera eficiente.
Pandas es una de esas bibliotecas de análisis de datos diseñada explícitamente para que Python realice la manipulación y el análisis de datos. La biblioteca de Pandas consta de estructuras de datos y operaciones específicas para manejar tablas numéricas, analizar datos y trabajar con series temporales. En este artículo, conocerá cómo agregar columnas a DataFrame en Pandas que ya existe.
Leer: Pandas Dataframe Astype
Tabla de contenido
¿Qué es DataFrame?
Antes de saber cómo agregar una nueva columna al DataFrame existente , primero echemos un vistazo a los DataFrames en Pandas . DataFrame es una estructura de datos mutable en forma de matriz bidimensional que puede almacenar valores heterogéneos con ejes etiquetados (filas y columnas). DataFrame es una estructura de datos donde los datos permanecen almacenados en un arreglo lógico de forma tabular (filas y columnas que se cruzan). Los tres componentes principales de un DataFrame son filas, columnas y datos. Crear un DataFrame en Python es muy fácil.
importar pandas como pd
l = ['Esto', 'es', 'un', 'Lista', 'preparando', 'para', 'Marco de datos']
datfr = pd.DataFrame(l)
imprimir (datfr)
El programa anterior creará un DataFrame de 7 filas y una columna.

¿Cómo agregar columnas a marcos de datos existentes?
Hay varias formas de agregar nuevas columnas a un DataFrame en Pandas . Ya hemos recopilado una idea de cómo crear un DataFrame básico utilizando la biblioteca de Pandas . Preparemos ahora una biblioteca ya existente y trabajemos en ella.
importar pandas como pd
# Definir un diccionario que contenga datos de Profesionales
datfr = {'Nombre': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altura': [6.2, 5.7, 6.1, 5.9],
'Designación': ['Científico', 'Profesor', 'Analista de datos', 'Analista de seguridad']}
df = pd.DataFrame(datfr)
imprimir (df)
Producción:
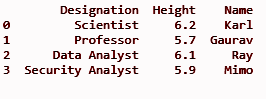
Leer: Tutorial de Python Pandas
Técnica 1: Método insert()
Ahora, para agregar nuevas columnas al DataFrame existente, debemos usar el método insert(). Antes de implementar el método insert(), infórmenos sobre su funcionamiento. DataFrame.insert() permite agregar una columna en cualquier posición que desee el analista de datos. También acomoda varias posibilidades para inyectar los valores de la columna. Los programadores pueden especificar el índice para inyectar la columna de datos en esa posición en particular.
importar pandas como pd
# Definir un diccionario que contenga datos de Profesionales
datfr = {'Nombre': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altura': [6.2, 5.7, 6.1, 5.9],
'Designación': ['Científico', 'Profesor', 'Analista de datos', 'Analista de seguridad']}
df = pd.DataFrame(datfr)
df.insert(3, “Edad”, [40, 33, 27, 26], Verdadero)
imprimir (df)
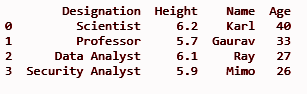
Agregará la columna 'Edad' en la tercera posición del índice como se define en el método insert() como primer parámetro.
Técnica 2: método de asignación ()
Otro método para agregar una columna a DataFrame es usar el método de asignación () de la biblioteca de Pandas. Este método utiliza un enfoque diferente para agregar una nueva columna al DataFrame existente. Dataframe.assign() creará un nuevo DataFrame junto con una columna. Luego lo agregará al DataFrame existente.

importar pandas como pd
datfr = {'Nombre': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altura': [6.2, 5.7, 6.1, 5.9],
'Designación': ['Científico', 'Profesor', 'Analista de datos', 'Analista de seguridad']}
dfI = pd.DataFrame(datfr)
dfII = dfI.assign(Ubicación = ['Noida', 'Ámsterdam', 'Cambridge', 'Bangaluru'])
imprimir (dfII)
PRODUCCIÓN:
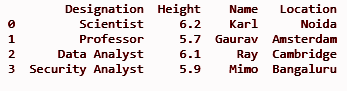
Técnica 3: Creación de una nueva lista como columna
El último método que los programadores pueden usar para agregar una columna a DataFrame es generar una nueva lista como una columna de datos separada y agregar la columna al DataFrame existente.
importar pandas como pd
datfr = {'Nombre': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Altura': [6.2, 5.7, 6.1, 5.9],
'Designación': ['Científico', 'Profesor', 'Analista de datos', 'Analista de seguridad']}
df = pd.DataFrame(datfr)
loc = ['Noida', 'Ámsterdam', 'Cambridge', 'Bangaluru']
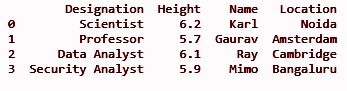
df['Ubicación'] = loc
imprimir (df)
PRODUCCIÓN:
Pago: preguntas de la entrevista de pandas
Conclusión
Los analistas de datos realizan una operación principal para agregar un conjunto adicional de datos en forma de columnas. Existen diferentes enfoques que un analista de datos o un programador pueden usar para agregar una nueva columna a un DataFrame existente en Pandas. Estos métodos harán que los programadores sean útiles para agregar columnas de datos en cualquier momento mientras analizan los datos de Pandas.
Si tiene curiosidad por aprender sobre DataFrame en Pandas, consulte el Programa PG Ejecutivo en Ciencia de Datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos prácticos, tutoría con expertos de la industria, 1 a 1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Por qué Pandas es una de las bibliotecas preferidas para crear marcos de datos en Python?
Se considera que la biblioteca de Pandas es la más adecuada para crear marcos de datos, ya que proporciona varias funciones que hacen que sea eficiente para crear un marco de datos. Algunas de estas características son las siguientes: los pandas nos brindan varios marcos de datos que no solo permiten una representación de datos eficiente sino que también nos permiten manipularlos. Proporciona características eficientes de alineación e indexación que brindan formas inteligentes de etiquetar y organizar los datos. Algunas características de Pandas hacen que el código sea limpio y aumentan su legibilidad, haciéndolo así más eficiente. También puede leer múltiples formatos de archivo. JSON, CSV, HDF5 y Excel son algunos de los formatos de archivo compatibles con Pandas. La fusión de múltiples conjuntos de datos ha sido un verdadero desafío para muchos programadores. Los pandas también superan esto y fusionan múltiples conjuntos de datos de manera muy eficiente. Pandas también brinda acceso a otras bibliotecas Python importantes como Matplotlib y NumPy, lo que la convierte en una biblioteca altamente eficiente.
¿Cuáles son las otras bibliotecas de Python con las que funciona la biblioteca de Pandas?
Pandas no solo funciona como una biblioteca central para crear marcos de datos, sino que también funciona con otras bibliotecas y herramientas de Python para ser más eficiente. Pandas se basa en el paquete NumPy Python, lo que indica que la mayor parte de la estructura de la biblioteca de Pandas se replica desde el paquete NumPy. El análisis estadístico de los datos en la biblioteca de Pandas es operado por SciPy, las funciones de trazado en Matplotlib y los algoritmos de aprendizaje automático en Scikit-learn. Jupyter Notebook es un entorno interactivo basado en web que funciona como un IDE y ofrece un buen entorno para Pandas.
Junto con la inserción, ¿cuáles son las operaciones fundamentales del Dataframe?
Es importante seleccionar un índice o una columna antes de iniciar cualquier operación, como agregar o eliminar. Una vez que aprenda cómo acceder a los valores y seleccionar columnas de un marco de datos, puede aprender a agregar índices, filas o columnas en un marco de datos de Pandas. Si el índice en el marco de datos no resulta ser el deseado, puede restablecerlo. Para restablecer el índice, puede utilizar la función "reset_index()".