
Ajout d'une nouvelle colonne à la trame de données existante dans Pandas [2022]
Publié: 2021-01-06Python, un langage de programmation interprété, polyvalent et de haut niveau, est récemment devenu un langage informatique phénoménal en raison de sa vaste collection de bibliothèques et de sa nature facile à mettre en œuvre. La popularité de Python a fait un bond énorme avec la mise en œuvre de la science des données et de l'analyse des données. Il existe des milliers de bibliothèques qui peuvent être intégrées à Python pour le faire fonctionner efficacement sur n'importe quel secteur vertical.
Pandas est l'une de ces bibliothèques d'analyse de données conçue explicitement pour Python pour effectuer la manipulation et l'analyse des données. La bibliothèque Pandas se compose de structures de données et d'opérations spécifiques pour traiter des tableaux numériques, analyser des données et travailler avec des séries chronologiques. Dans cet article, vous apprendrez à ajouter des colonnes à DataFrame dans Pandas qui existe déjà.
Lire : Pandas Dataframe Astype
Table des matières
Qu'est-ce que DataFrame ?
Avant de savoir comment ajouter une nouvelle colonne au DataFrame existant , jetons d'abord un coup d'œil sur les DataFrames dans Pandas . DataFrame est une structure de données modifiable sous la forme d'un tableau à deux dimensions pouvant stocker des valeurs hétérogènes avec des axes étiquetés (lignes et colonnes). DataFrame est une structure de données où les données restent stockées dans un arrangement logique de mode tabulaire (lignes et colonnes qui se croisent). Les trois principaux composants d'un DataFrame sont les lignes, les colonnes et les données. Créer un DataFrame en Python est très simple.
importer des pandas en tant que pd
l = ['This', 'is', 'a', 'List', 'preparing', 'for', 'DataFrame']
datfr = pd.DataFrame(l)
print(datfr)
Le programme ci-dessus créera un DataFrame de 7 lignes et une colonne.

Comment ajouter des colonnes aux DataFrames existants ?
Il existe différentes façons d' ajouter de nouvelles colonnes à un DataFrame dans Pandas . Nous avons déjà rassemblé une idée de la façon de créer un DataFrame de base à l'aide de la bibliothèque Pandas . Préparons maintenant une bibliothèque déjà existante et travaillons dessus.
importer des pandas en tant que pd
# Définir un dictionnaire contenant les données des professionnels
datfr = {'Nom': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Hauteur' : [6.2, 5.7, 6.1, 5.9],
'Désignation' : ['Scientifique', 'Professeur', 'Analyste de données', 'Analyste de sécurité']}
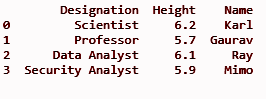
df = pd.DataFrame(datfr)
imprimer (df)
Sortir:
Lis: Tutoriel Python Pandas
Technique 1 : méthode insert()
Maintenant, pour ajouter de nouvelles colonnes au DataFrame existant, nous devons utiliser la méthode insert(). Avant d'implémenter la méthode insert(), informez-nous de son fonctionnement. Le DataFrame.insert() permet d'ajouter une colonne à n'importe quelle position souhaitée par l'analyste de données. Il offre également plusieurs possibilités pour injecter les valeurs de colonne. Les programmeurs peuvent spécifier l'index pour injecter la colonne de données à cette position particulière.
importer des pandas en tant que pd
# Définir un dictionnaire contenant les données des professionnels
datfr = {'Nom': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Hauteur' : [6.2, 5.7, 6.1, 5.9],
'Désignation' : ['Scientifique', 'Professeur', 'Analyste de données', 'Analyste de sécurité']}
df = pd.DataFrame(datfr)
df.insert(3, "Âge", [40, 33, 27, 26], Vrai)
imprimer (df)
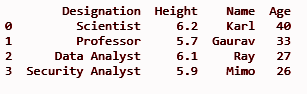
Il ajoutera la colonne 'Age' dans la troisième position d'index comme défini dans la méthode insert() comme premier paramètre.
Technique 2 : Méthode assign()
Une autre méthode pour ajouter une colonne à DataFrame consiste à utiliser la méthode assign() de la bibliothèque Pandas. Cette méthode utilise une approche différente pour ajouter une nouvelle colonne au DataFrame existant. Dataframe.assign() créera un nouveau DataFrame avec une colonne. Ensuite, il l'ajoutera au DataFrame existant.

importer des pandas en tant que pd
datfr = {'Nom': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Hauteur' : [6.2, 5.7, 6.1, 5.9],
'Désignation' : ['Scientifique', 'Professeur', 'Analyste de données', 'Analyste de sécurité']}
dfI = pd.DataFrame(datfr)
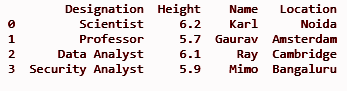
dfII = dfI.assign(Location = ['Noida', 'Amsterdam', 'Cambridge', 'Bangaluru'])
impression(dfII)
SORTIR:
Technique 3 : Création d'une nouvelle liste en tant que colonne
La dernière méthode que les programmeurs peuvent utiliser pour ajouter une colonne à DataFrame consiste à générer une nouvelle liste en tant que colonne de données distincte et à ajouter la colonne au DataFrame existant.
importer des pandas en tant que pd
datfr = {'Nom': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Hauteur' : [6.2, 5.7, 6.1, 5.9],
'Désignation' : ['Scientifique', 'Professeur', 'Analyste de données', 'Analyste de sécurité']}
df = pd.DataFrame(datfr)
loc = ['Noida', 'Amsterdam', 'Cambridge', 'Bangaluru']
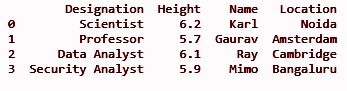
df['Emplacement'] = loc
imprimer (df)
SORTIR:
Paiement : questions d'entrevue avec les pandas
Conclusion
Les analystes de données effectuent une opération principale pour ajouter un ensemble supplémentaire de données sous une forme par colonne. Il existe différentes approches qu'un analyste de données ou un programmeur peut utiliser pour ajouter une nouvelle colonne à un DataFrame existant dans Pandas. Ces méthodes permettront aux programmeurs d'ajouter des colonnes de données à tout moment lors de l'analyse des données Pandas.
Si vous êtes curieux d'en savoir plus sur DataFrame dans Pandas, consultez le programme Executive PG en science des données de IIIT-B & upGrad qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1-on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Pourquoi Pandas est-il l'une des bibliothèques préférées pour créer des cadres de données en Python ?
La bibliothèque Pandas est considérée comme la mieux adaptée à la création de trames de données car elle fournit diverses fonctionnalités qui la rendent efficace pour créer une trame de données. Certaines de ces fonctionnalités sont les suivantes - Pandas nous fournit diverses trames de données qui permettent non seulement une représentation efficace des données, mais nous permettent également de les manipuler. Il fournit des fonctionnalités d'alignement et d'indexation efficaces qui offrent des moyens intelligents d'étiqueter et d'organiser les données. Certaines fonctionnalités de Pandas rendent le code propre et augmentent sa lisibilité, le rendant ainsi plus efficace. Il peut également lire plusieurs formats de fichiers. JSON, CSV, HDF5 et Excel sont quelques-uns des formats de fichiers pris en charge par Pandas. La fusion de plusieurs ensembles de données a été un véritable défi pour de nombreux programmeurs. Les pandas surmontent également cela et fusionnent très efficacement plusieurs ensembles de données. Pandas donne également accès à d'autres bibliothèques Python importantes telles que Matplotlib et NumPy, ce qui en fait une bibliothèque très efficace.
Quelles sont les autres bibliothèques Python avec lesquelles la bibliothèque Pandas fonctionne ?
Pandas fonctionne non seulement comme une bibliothèque centrale pour créer des cadres de données, mais il fonctionne également avec d'autres bibliothèques et outils de Python pour être plus efficace. Pandas est construit sur le package NumPy Python, ce qui indique que la majeure partie de la structure de la bibliothèque Pandas est répliquée à partir du package NumPy. L'analyse statistique des données de la bibliothèque Pandas est opérée par SciPy, des fonctions de traçage sur Matplotlib et des algorithmes d'apprentissage automatique dans Scikit-learn. Jupyter Notebook est un environnement interactif basé sur le Web qui fonctionne comme un IDE et offre un bon environnement pour Pandas.
Outre l'insertion, quelles sont les opérations fondamentales du Dataframe ?
Il est important de sélectionner un index ou une colonne avant de commencer toute opération comme l'ajout ou la suppression. Une fois que vous avez appris à accéder aux valeurs et à sélectionner des colonnes à partir d'un cadre de données, vous pouvez apprendre à ajouter un index, une ligne ou une colonne dans un cadre de données Pandas. Si l'index dans le bloc de données ne correspond pas à ce que vous souhaitiez, vous pouvez le réinitialiser. Pour réinitialiser l'index, vous pouvez utiliser la fonction "reset_index()".