
Добавление нового столбца в существующий фрейм данных в Pandas [2022]
Опубликовано: 2021-01-06Python, интерпретируемый язык программирования высокого уровня общего назначения, в последнее время стал феноменальным вычислительным языком благодаря обширному набору библиотек и простоте реализации. Популярность Python резко возросла с внедрением науки о данных и анализа данных. Существуют тысячи библиотек, которые можно интегрировать с Python, чтобы он эффективно работал на любой вертикали.
Pandas — одна из таких библиотек анализа данных, разработанная специально для Python для выполнения манипуляций с данными и их анализа. Библиотека Pandas состоит из определенных структур данных и операций для работы с числовыми таблицами, анализа данных и работы с временными рядами. В этой статье вы узнаете, как добавить уже существующие столбцы в DataFrame в Pandas.
Читайте: Pandas Dataframe Astype
Оглавление
Что такое датафрейм?
Прежде чем узнать, как добавить новый столбец в существующий DataFrame , давайте сначала взглянем на DataFrames в Pandas . DataFrame — это изменяемая структура данных в виде двумерного массива, который может хранить разнородные значения с размеченными осями (строки и столбцы). DataFrame — это структура данных, в которой данные хранятся в логической табличной (пересекающиеся строки и столбцы) форме. Три основных компонента DataFrame — это строки, столбцы и данные. Создать DataFrame в Python очень просто.
импортировать панд как pd
l = ['Это', 'есть', 'а', 'Список', 'подготовка', 'для', 'Кадр данных']
datfr = pd.DataFrame(l)
печать (датфр)
Приведенная выше программа создаст DataFrame из 7 строк и одного столбца.

Как добавить столбцы в существующие фреймы данных?
Существуют различные способы добавления новых столбцов в DataFrame в Pandas . Мы уже получили представление о том, как создать базовый DataFrame с помощью библиотеки Pandas . Давайте теперь подготовим уже существующую библиотеку и поработаем над ней.
импортировать панд как pd
# Определить словарь, содержащий данные профессионалов
datfr = {'Имя': ['Карл', 'Гаурав', 'Рэй', 'Мимо'],
«Высота»: [6.2, 5.7, 6.1, 5.9],
«Должность»: [«Ученый», «Профессор», «Аналитик данных», «Аналитик по безопасности»]}
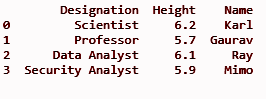
df = pd.DataFrame(datfr)
печать (дф)
Выход:
Читайте: Учебник по Python Pandas
Техника 1: Метод вставки()
Теперь, чтобы добавить новые столбцы в существующий DataFrame, мы должны использовать метод вставки(). Перед реализацией метода insert() сообщите нам о его работе. DataFrame.insert() позволяет добавить столбец в любую позицию, которую хочет аналитик данных. Он также предоставляет несколько возможностей для ввода значений столбца. Программисты могут указать индекс для вставки столбца данных в эту конкретную позицию.
импортировать панд как pd
# Определить словарь, содержащий данные профессионалов
datfr = {'Имя': ['Карл', 'Гаурав', 'Рэй', 'Мимо'],
«Высота»: [6.2, 5.7, 6.1, 5.9],
«Должность»: [«Ученый», «Профессор», «Аналитик данных», «Аналитик по безопасности»]}
df = pd.DataFrame(datfr)
df.insert(3, «Возраст», [40, 33, 27, 26], Истина)
печать (дф)
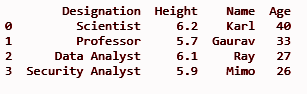
Он добавит столбец «Возраст» в третью позицию индекса, как определено в методе вставки (), в качестве первого параметра.
Техника 2: метод assign()
Другой способ добавить столбец в DataFrame — использовать метод assign() библиотеки Pandas. Этот метод использует другой подход для добавления нового столбца в существующий DataFrame. Dataframe.assign() создаст новый DataFrame вместе со столбцом. Затем он добавит его к существующему DataFrame.

импортировать панд как pd
datfr = {'Имя': ['Карл', 'Гаурав', 'Рэй', 'Мимо'],
«Высота»: [6.2, 5.7, 6.1, 5.9],
«Должность»: [«Ученый», «Профессор», «Аналитик данных», «Аналитик по безопасности»]}
dfI = pd.DataFrame(datfr)
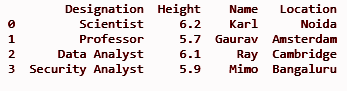
dfII = dfI.assign(Location = ['Нойда', 'Амстердам', 'Кембридж', 'Бангалор'])
печать (dfII)
ВЫХОД:
Метод 3: создание нового списка в виде столбца
Последний метод, который программисты могут использовать для добавления столбца в DataFrame , — создание нового списка в виде отдельного столбца данных и добавление столбца в существующий DataFrame.
импортировать панд как pd
datfr = {'Имя': ['Карл', 'Гаурав', 'Рэй', 'Мимо'],
«Высота»: [6.2, 5.7, 6.1, 5.9],
«Назначение»: [«Ученый», «Профессор», «Аналитик данных», «Аналитик по безопасности»]}
df = pd.DataFrame(datfr)
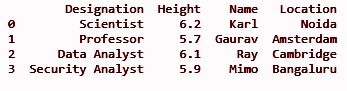
loc = ['Нойда', 'Амстердам', 'Кембридж', 'Бангалуру']
df['Расположение'] = местоположение
печать (дф)
ВЫХОД:
Оформить заказ: Pandas Interview Вопросы
Заключение
Аналитики данных выполняют основную операцию по добавлению дополнительного набора данных в виде столбцов. Аналитик данных или программист могут использовать различные подходы для добавления нового столбца в существующий DataFrame в Pandas. Эти методы помогут программистам добавлять столбцы данных в любой момент времени при анализе данных Pandas.
Если вам интересно узнать о DataFrame в Pandas, ознакомьтесь с программой Executive PG IIIT-B и upGrad по науке о данных, которая создана для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические семинары, наставничество с отраслевыми экспертами, Индивидуальные встречи с отраслевыми наставниками, более 400 часов обучения и помощь в трудоустройстве в ведущих фирмах.
Почему Pandas является одной из наиболее предпочтительных библиотек для создания фреймов данных в Python?
Библиотека Pandas считается наиболее подходящей для создания фреймов данных, поскольку она предоставляет различные функции, которые делают создание фрейма данных более эффективным. Вот некоторые из этих функций: Pandas предоставляет нам различные фреймы данных, которые не только обеспечивают эффективное представление данных, но и позволяют нам манипулировать ими. Он обеспечивает эффективные функции выравнивания и индексации, которые обеспечивают интеллектуальные способы маркировки и организации данных. Некоторые функции Pandas делают код чистым и повышают его читабельность, что делает его более эффективным. Он также может читать несколько форматов файлов. JSON, CSV, HDF5 и Excel — это некоторые из форматов файлов, поддерживаемых Pandas. Слияние нескольких наборов данных стало настоящей проблемой для многих программистов. Панды преодолевают и это и очень эффективно объединяют несколько наборов данных. Pandas также предоставляет доступ к другим важным библиотекам Python, таким как Matplotlib и NumPy, что делает его высокоэффективной библиотекой.
Какие еще есть библиотеки Python, с которыми работает библиотека Pandas?
Pandas работает не только как центральная библиотека для создания фреймов данных, но и работает с другими библиотеками и инструментами Python для большей эффективности. Pandas построен на основе пакета NumPy Python, что указывает на то, что большая часть структуры библиотеки Pandas реплицирована из пакета NumPy. Статистический анализ данных в библиотеке Pandas выполняется SciPy, функции построения графиков — в Matplotlib, а алгоритмы машинного обучения — в Scikit-learn. Jupyter Notebook — это интерактивная веб-среда, которая работает как IDE и предлагает хорошую среду для Pandas.
Наряду со вставкой, каковы основные операции Dataframe?
Важно выбрать индекс или столбец перед началом любой операции, такой как добавление или удаление. Как только вы научитесь получать доступ к значениям и выбирать столбцы из фрейма данных, вы сможете научиться добавлять индекс, строку или столбец в фрейм данных Pandas. Если индекс во фрейме данных не соответствует вашим ожиданиям, вы можете сбросить его. Для сброса индекса вы можете использовать функцию «reset_index()».