
Hinzufügen einer neuen Spalte zu einem bestehenden Datenrahmen in Pandas [2022]
Veröffentlicht: 2021-01-06Python, eine interpretierte, universelle Programmiersprache auf hohem Niveau, hat sich in letzter Zeit aufgrund ihrer riesigen Sammlung von Bibliotheken und ihrer einfachen Implementierung zu einer phänomenalen Computersprache entwickelt. Die Popularität von Python hat mit der Implementierung von Data Science und Data Analytics einen enormen Sprung gemacht. Es gibt Tausende von Bibliotheken, die in Python integriert werden können, damit es in jeder Branche effizient funktioniert.
Pandas ist eine solche Datenanalysebibliothek, die explizit für Python entwickelt wurde, um Datenmanipulation und Datenanalyse durchzuführen. Die Pandas -Bibliothek besteht aus spezifischen Datenstrukturen und Operationen, um mit numerischen Tabellen umzugehen, Daten zu analysieren und mit Zeitreihen zu arbeiten. In diesem Artikel erfahren Sie, wie Sie bereits vorhandene Spalten zu DataFrame in Pandas hinzufügen .
Lesen Sie: Pandas Dataframe Astype
Inhaltsverzeichnis
Was ist DataFrame?
Bevor wir wissen, wie man eine neue Spalte zu einem bestehenden DataFrame hinzufügt , werfen wir zunächst einen Blick auf DataFrames in Pandas . DataFrame ist eine veränderliche Datenstruktur in Form eines zweidimensionalen Arrays, das heterogene Werte mit beschrifteten Achsen (Zeilen und Spalten) speichern kann. DataFrame ist eine Datenstruktur, in der die Daten in einer logischen tabellarischen Anordnung (überschneidende Zeilen und Spalten) gespeichert bleiben. Die drei Hauptkomponenten eines DataFrame sind Zeilen, Spalten und Daten. Das Erstellen eines DataFrame in Python ist sehr einfach.
pandas als pd importieren
l = ['This', 'is', 'a', 'List', 'preparing', 'for', 'DataFrame']
datfr = pd.DataFrame(l)
drucken (datfr)
Das obige Programm erstellt einen DataFrame aus 7 Zeilen und einer Spalte.

Wie füge ich Spalten zu bestehenden DataFrames hinzu?
Es gibt verschiedene Möglichkeiten , neue Spalten zu einem DataFrame in Pandas hinzuzufügen. Wir haben bereits eine Vorstellung davon gesammelt, wie Sie mit der Pandas -Bibliothek einen einfachen DataFrame erstellen können. Lassen Sie uns nun eine bereits vorhandene Bibliothek vorbereiten und daran arbeiten.
pandas als pd importieren
# Definieren Sie ein Wörterbuch, das die Daten von Fachleuten enthält
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Höhe': [6.2, 5.7, 6.1, 5.9],
'Bezeichnung': ['Wissenschaftler', 'Professor', 'Datenanalyst', 'Sicherheitsanalyst']}
df = pd.DataFrame(datfr)
drucken (df)
Ausgabe:
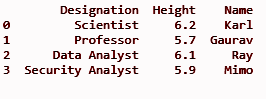
Lesen Sie: Python-Pandas-Tutorial
Technik 1: insert() Methode
Um nun dem vorhandenen DataFrame neue Spalten hinzuzufügen, müssen wir die Methode insert() verwenden. Informieren Sie uns vor der Implementierung der Methode insert() über ihre Funktionsweise. DataFrame.insert() ermöglicht das Hinzufügen einer Spalte an jeder beliebigen Position, die der Datenanalyst wünscht. Es bietet auch mehrere Möglichkeiten zum Einspeisen der Spaltenwerte. Programmierer können den Index angeben, um die Datenspalte an dieser bestimmten Position einzufügen.
pandas als pd importieren
# Definieren Sie ein Wörterbuch, das die Daten von Fachleuten enthält
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Höhe': [6.2, 5.7, 6.1, 5.9],
'Bezeichnung': ['Wissenschaftler', 'Professor', 'Datenanalyst', 'Sicherheitsanalyst']}
df = pd.DataFrame(datfr)
df.insert(3, „Alter“, [40, 33, 27, 26], True)
drucken (df)
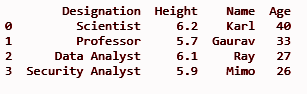
Es fügt die Spalte „Alter“ an der dritten Indexposition hinzu, wie in der Methode insert() als erster Parameter definiert.
Technik 2: Methode assign()
Eine andere Methode zum Hinzufügen einer Spalte zu DataFrame ist die Verwendung der Methode assign() der Pandas-Bibliothek. Diese Methode verwendet einen anderen Ansatz, um dem vorhandenen DataFrame eine neue Spalte hinzuzufügen. Dataframe.assign() erstellt einen neuen DataFrame zusammen mit einer Spalte. Dann wird es an den vorhandenen DataFrame angehängt.

pandas als pd importieren
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Höhe': [6.2, 5.7, 6.1, 5.9],
'Bezeichnung': ['Wissenschaftler', 'Professor', 'Datenanalyst', 'Sicherheitsanalyst']}
dfI = pd.DataFrame(datfr)
dfII = dfI.assign(Location = ['Noida', 'Amsterdam', 'Cambridge', 'Bangaluru'])
drucken (dfII)
AUSGANG:
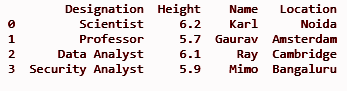
Technik 3: Erstellen einer neuen Liste als Spalte
Die letzte Methode, mit der Programmierer DataFrame eine Spalte hinzufügen können, besteht darin, eine neue Liste als separate Datenspalte zu generieren und die Spalte an den vorhandenen DataFrame anzuhängen.
pandas als pd importieren
datfr = {'Name': ['Karl', 'Gaurav', 'Ray', 'Mimo'],
'Höhe': [6.2, 5.7, 6.1, 5.9],
'Bezeichnung': ['Wissenschaftler', 'Professor', 'Datenanalyst', 'Sicherheitsanalyst']}
df = pd.DataFrame(datfr)
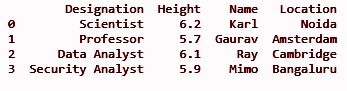
loc = ['Noida', 'Amsterdam', 'Cambridge', 'Bangaluru']
df['Standort'] = loc
drucken (df)
AUSGANG:
Checkout: Pandas-Interviewfragen
Fazit
Datenanalysten führen eine primäre Operation zum Hinzufügen eines zusätzlichen Datensatzes in spaltenweiser Form durch. Es gibt verschiedene Ansätze, die ein Datenanalyst oder Programmierer verwenden kann, um eine neue Spalte zu einem vorhandenen DataFrame in Pandas hinzuzufügen. Diese Methoden machen es Programmierern praktisch, jederzeit Datenspalten hinzuzufügen, während sie Pandas-Daten analysieren.
Wenn Sie neugierig sind, mehr über DataFrame in Pandas zu erfahren, schauen Sie sich das Executive PG Program in Data Science von IIIT-B & upGrad an, das für Berufstätige entwickelt wurde und mehr als 10 Fallstudien und Projekte, praktische praktische Workshops, Mentoring mit Branchenexperten, 1-on-1 mit Mentoren aus der Branche, mehr als 400 Stunden Lern- und Jobunterstützung bei Top-Unternehmen.
Warum ist Pandas eine der am meisten bevorzugten Bibliotheken zum Erstellen von Datenrahmen in Python?
Die Pandas-Bibliothek gilt als am besten geeignet zum Erstellen von Datenrahmen, da sie verschiedene Funktionen bietet, die das Erstellen eines Datenrahmens effizient machen. Einige dieser Funktionen sind wie folgt: Pandas stellen uns verschiedene Datenrahmen zur Verfügung, die nicht nur eine effiziente Datendarstellung ermöglichen, sondern uns auch ermöglichen, sie zu manipulieren. Es bietet effiziente Ausrichtungs- und Indizierungsfunktionen, die intelligente Möglichkeiten zur Kennzeichnung und Organisation der Daten bieten. Einige Funktionen von Pandas machen den Code sauberer und erhöhen seine Lesbarkeit, wodurch er effizienter wird. Es kann auch mehrere Dateiformate lesen. JSON, CSV, HDF5 und Excel sind einige der von Pandas unterstützten Dateiformate. Das Zusammenführen mehrerer Datensätze war für viele Programmierer eine echte Herausforderung. Pandas überwinden auch dies und führen mehrere Datensätze sehr effizient zusammen. Pandas bietet auch Zugriff auf andere wichtige Python-Bibliotheken wie Matplotlib und NumPy, was es zu einer hocheffizienten Bibliothek macht.
Was sind die anderen Python-Bibliotheken, mit denen die Pandas-Bibliothek funktioniert?
Pandas fungiert nicht nur als zentrale Bibliothek zum Erstellen von Datenrahmen, sondern arbeitet auch mit anderen Bibliotheken und Tools von Python zusammen, um effizienter zu sein. Pandas basiert auf dem NumPy-Python-Paket, was darauf hinweist, dass der größte Teil der Pandas-Bibliotheksstruktur aus dem NumPy-Paket repliziert wird. Die statistische Analyse der Daten in der Pandas-Bibliothek wird von SciPy durchgeführt, Plotting-Funktionen auf Matplotlib und maschinelle Lernalgorithmen in Scikit-learn. Jupyter Notebook ist eine webbasierte interaktive Umgebung, die als IDE funktioniert und eine gute Umgebung für Pandas bietet.
Was sind neben dem Einfügen die grundlegenden Operationen des Datenrahmens?
Es ist wichtig, einen Index oder eine Spalte auszuwählen, bevor Sie mit einer Operation wie Hinzufügen oder Löschen beginnen. Sobald Sie gelernt haben, wie Sie auf Werte zugreifen und Spalten aus einem Datenrahmen auswählen, können Sie lernen, Index, Zeile oder Spalte in einem Pandas-Datenrahmen hinzuzufügen. Wenn der Index im Datenrahmen nicht wie gewünscht ausfällt, können Sie ihn zurücksetzen. Um den Index zurückzusetzen, können Sie die Funktion „reset_index()“ verwenden.