
Les pandas concatènent des trames de données [2022]
Publié: 2021-01-06Imaginez que vous avez deux ensembles de données que vous devez combiner pour effectuer une analyse. Lors de l'utilisation de SQL, les enregistrements de deux ou plusieurs tables d'une base de données peuvent être combinés à l'aide de jointures SQL. De même, il existe également des options en Python pour concaténer des cadres de données. Alors, qu'est-ce qu'une trame de données ? Un bloc de données en Python comporte plusieurs lignes et colonnes. Il est similaire à une table en SQL. Vous disposez de la bibliothèque logicielle pandas pour l'analyse de données en Python. Les pandas concatènent des trames de données nous aident à combiner des trames de données en fonction d'une certaine logique.
Les différentes manières de combiner les trames de données :
- Jointure interne : la jointure interne s'apparente à l'intersection de deux ensembles. Dans le cas d'une jointure interne, un bloc de données est renvoyé contenant uniquement les lignes ayant des propriétés communes. Ainsi, chaque ligne des deux blocs de données combinés doit avoir des valeurs de colonne correspondantes.
- Jointure gauche : une jointure gauche renvoie toutes les lignes du bloc de données de gauche et uniquement les lignes correspondantes du bloc de données de droite.
- Jointure droite : une jointure droite renvoie toutes les lignes du bloc de données de droite et uniquement les lignes correspondantes du bloc de données de gauche.
- Jointure complète ou externe : une jointure complète conserve toutes les lignes du bloc de données gauche et du bloc de données droit.
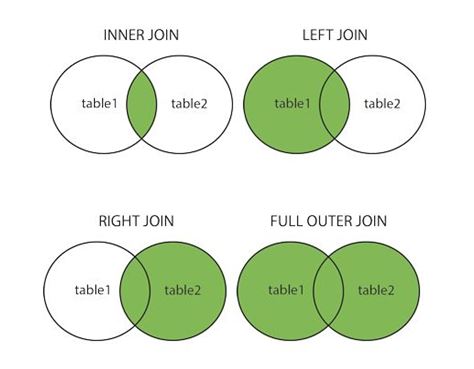 La source
La source
Voyons maintenant les fonctions présentes dans Pandas pour combiner des data frames ou des séries.
Table des matières
Fonctions dans les pandas
1. Fonction de jointure
Comme nous l'avons lu, Python dispose de nombreuses fonctionnalités similaires à SQL pour combiner des données. Les trames de données ont un index qui agit comme une adresse. Habituellement, les indices de ligne sont appelés index tandis que les colonnes sont adressées par les noms de colonne. L'opération Join vous permet de fusionner toutes les colonnes de deux blocs de données. Vous pouvez renommer les colonnes de gauche et de droite en mettant à jour les paramètres « lsuffix » et « rsuffix ». Vous avez la possibilité de choisir le mode de fusion en mettant à jour le paramètre "comment".
2. Fonction de fusion
La fonction de fusion est assez similaire à l'opération de jointure. Cependant, vous obtenez un contrôle flexible tout en combinant toutes les colonnes de deux blocs de données. Vous pouvez utiliser on = Column Name pour fusionner des blocs de données sur la colonne commune. Vous pouvez mettre à jour left_on = Column Name ou right_on = Column Name pour aligner les tables en utilisant les colonnes du bloc de données gauche ou droit comme clés. Choisir left_index = True ou right_index = True vous permet d'utiliser les étiquettes de ligne du bloc de données gauche ou du bloc de données droit comme clés de jointure.
Syntaxe:
DataFrame.merge( self , right , how='left' , on=None , left_on=None ,
right_on=Aucun , left_index=False , right_index=False , sort=False , suffixes=('_x' , '_y') , copy=True , indicator=False , validate=None )
Lire : Questions d'entretien avec Pandas
3. Fonction Concat
À l'aide de la fonction Concat, vous pouvez combiner des données sur des colonnes ou des lignes en fonction de votre choix. Vous pouvez définir la logique de jointure (jointure gauche/droite/intérieure/complète) sur l'un ou l'autre des deux axes. Vous obtenez également une option pour vérifier si le nouvel axe concaténé a des valeurs en double présentes à l'aide de verify_integrity. Si aucune valeur d'index n'est spécifiée sur l'axe de concaténation, l'axe résultant sera étiqueté comme 0,1,… n-1. Le paramètre keys permet de former une indexation hiérarchique à l'aide des clés passées.

Syntaxe
pandas.concat( objs , axis=0 , join='left' , join_axes=None ,
ignore_index=False , keys=Aucun , niveaux=Aucun , names=Aucun ,
verify_integrity=False , sort=Aucun , copy=True )
Lire : Algorithme de structure de données en Python
Emballer
Comme nous l'avons vu dans pandas.DataFrame, les fonctions de fusion et de jointure sont utilisées pour combiner des cadres de données travaillant sur des colonnes. Il existe également une option pour renommer les colonnes en fonction du suffixe fourni. La fonction de fusion offre plus de flexibilité dans le cas d'un alignement par rangée. Au contraire, la fonction Concat des pandas peut fonctionner sur des lignes ou des colonnes.
Aucun changement de nom de colonnes n'est effectué lors de l'utilisation de la fonction Concat. La concaténation des trames de données par Pandas est une fonctionnalité essentielle lorsque nous devons combiner deux trames de données. La fusion de deux blocs de données à l'aide de certaines conditions vous aide à préparer les données nécessaires à l'analyse et à d'autres tâches. Ainsi, pour la bibliothèque de logiciels, les pandas concatènent les trames de données est une fonction intégrale.
Souhaitez-vous en savoir plus sur les différentes fonctions disponibles dans les pandas et approfondir l'analyse des données ? Vous pouvez consulter le diplôme PG en science des données offert par upGrad. Les cours sont dispensés par des experts de l'industrie et vous aideront à en savoir plus sur l'analyse exploratoire des données, diverses techniques de visualisation des données et les algorithmes sur l'apprentissage automatique. Lancez votre carrière dans le domaine de l'analyse de données et de l'apprentissage automatique avec upGrad.
Quels sont les différents types d'articulations chez les Pandas ?
La bibliothèque Pandas fournit quatre types de jointures différentes pour combiner des trames de données. Ces jointures sont les suivantes - La jointure interne est la jointure la plus basique pour combiner des trames de données. La jointure interne renvoie un bloc de données contenant uniquement les lignes qui ont des propriétés communes. Par conséquent, les deux trames de données combinées doivent avoir des valeurs communes. La jointure complète ou externe renvoie toutes les lignes des blocs de données gauche et droit. En d'autres termes, il fournit l'union des deux trames de données. La jointure gauche renvoie toutes les lignes du bloc de données de gauche ainsi que les lignes correspondantes du bloc de données de droite. La jointure droite est exactement l'opposée de la jointure gauche. Il renvoie toutes les lignes du bloc de données de droite ainsi que les lignes correspondantes du bloc de données de gauche.
Quelles sont les différentes manières de concaténer des lignes ou des colonnes ?
Les lignes ou les colonnes de deux blocs de données peuvent être concaténées des manières suivantes : 1. Concaténation de DataFrame à l'aide de .concat() - c'est le moyen le plus simple de concaténer deux lignes ou colonnes lorsque nous utilisons la fonction ".concat()". 2. Concaténation de DataFrame en définissant la logique sur les axes - Dans cette méthode, nous définissons une logique différente sur les axes. Voici les façons de définir les axes : prendre l'union (jointure = extérieure), prendre l'intersection (jointure = intérieure), utiliser un index spécifique. 3. Concaténation de DataFrame à l'aide de .append() - la fonction ".append()" est utilisée juste avant la fonction ".concat()" et concatène le long de l'axe = 0. 4. Concaténation de DataFrame en ignorant les index - Dans cette méthode , nous ignorons les indices sans signification et ajoutons le bloc de données. Nous utilisons ignore_index comme argument pour ignorer les index qui se chevauchent.
Que savez-vous de la fonction de fusion ?
La fonction de fusion est opérée sur deux blocs de données pour fusionner les lignes ou les colonnes. Il s'agit d'une opération de jointure à mémoire élevée qui ressemble aux bases de données relationnelles. Vous pouvez utiliser on = Column Name pour fusionner des blocs de données sur la colonne commune.
Vous pouvez mettre à jour left_on = Column Name ou right_on = Column Name pour aligner les tables en utilisant les colonnes du bloc de données gauche ou droit comme clés. Choisir left_index = True ou right_index = True vous permet d'utiliser les étiquettes de ligne du bloc de données gauche ou du bloc de données droit comme clés de jointure.