
Regresión lineal vs. Regresión logística: diferencia entre regresión lineal y regresión logística
Publicado: 2020-09-10El mundo del aprendizaje automático no estaría completo sin la presencia de dos de los algoritmos de aprendizaje automático más simples. Sí, tanto la regresión lineal como la regresión logística son los algoritmos de aprendizaje automático más sencillos que puede implementar. Antes de analizar cualquiera de las diferencias entre la regresión lineal y la logística, primero debemos comprender los conceptos básicos sobre los que se establecen los cimientos de estos dos algoritmos.
En primer lugar, ambos algoritmos son de aprendizaje supervisado por naturaleza. Es decir, los datos que ingresará en ambos algoritmos deben estar bien etiquetados. Otra cosa crítica a tener en cuenta son los casos de uso. Desde el principio, una diferencia evidente entre estos dos algoritmos son los casos de uso de ambos. La regresión lineal se usa siempre que nos gustaría realizar una regresión. Es decir, usamos la regresión lineal siempre que queremos predecir números continuos, como los precios de la vivienda en un área en particular.
Sin embargo, el uso de la regresión logística se realiza en problemas de clasificación. Es decir, si queremos predecir si una casa en particular es cara o barata (en lugar del precio), usamos el algoritmo de regresión logística. Sí, aunque la regresión logística tiene la palabra regresión en su nombre, se usa para clasificación.
Hay más sutilezas emocionantes que encontrará a continuación. Pero antes de comparar de frente la regresión lineal con la regresión logística, primero aprendamos más sobre cada uno de estos algoritmos.
Tabla de contenido
Regresión lineal
La regresión lineal es el algoritmo de aprendizaje automático más fácil y simple de comprender e implementar. Es un algoritmo de aprendizaje supervisado, por lo que si queremos predecir los valores continuos (o realizar una regresión), tendríamos que servir este algoritmo con un conjunto de datos bien etiquetado. Este algoritmo de aprendizaje automático es más sencillo debido a su naturaleza lineal. Para predecir con éxito los valores futuros, la regresión lineal intenta una línea recta a través de los datos introducidos en el algoritmo.
Entonces, cada vez que se ingresa información en un algoritmo de regresión lineal, toma los datos y toma la ecuación de una línea recta, seleccionando aleatoriamente la pendiente y la intersección hasta que encuentra la línea que mejor se ajusta. Si los datos que ingresamos en este algoritmo solo contienen una sola variable independiente, entonces se llama regresión lineal simple.

Por otro lado, si los datos tienen múltiples variables independientes, la regresión se convierte en una regresión lineal múltiple. La forma matemática de la regresión lineal es simplemente la de una línea recta, que se muestra a continuación.
y= a0+a1x+ c
Aquí, y es la variable dependiente, a0 y a1 es el coeficiente que este algoritmo tiene la tarea de encontrar, x es la variable dependiente y c es el valor de intersección de esta línea recta.
Regresión logística
No hace falta decir que la regresión logística es uno de los algoritmos de aprendizaje automático de clasificación más sencillos pero muy poderosos bajo el paraguas de un algoritmo de aprendizaje supervisado. Este algoritmo se puede usar para problemas de regresión, pero se usa principalmente para resolver problemas de clasificación. El resultado que obtenemos de este algoritmo siempre está entre 0 y 1, por lo que resulta sencillo clasificar las instancias en clases mediante el uso de un valor de clasificación de umbral.
La palabra logística en el nombre se refiere a la función de activación, que se utiliza en esta regresión. La función de activación o la función logística, en este caso, en realidad no es más que la función sigmoidea. Es propiedad de esta función sigmoidea, que mantiene el valor de la regresión logística siempre entre cero y uno. La función sigmoidea se parece a esto:
![]()
Aquí, y es la salida a través de la función sigmoidea y x es la variable independiente. En el caso de la regresión logística, la variable x sería en realidad la ecuación de regresión lineal completa. Por lo tanto, se puede desarrollar la ecuación para la regresión logística, que se escribe a continuación:
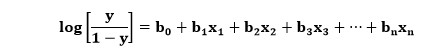
Aquí, el significado de las variables es similar al de la regresión logística, x es la variable independiente, y es la variable dependiente, b0, b1, b2, etc., son el coeficiente que determina este algoritmo.

Diferencia entre regresión lineal y logística.
A continuación, encontrará una comparación completa de la regresión lineal frente a la regresión logística una al lado de la otra:
| REGRESIÓN LINEAL | REGRESIÓN LOGÍSTICA |
| Requiere datos bien etiquetados, lo que significa que necesita supervisión y se utiliza para la regresión. Por lo tanto, la regresión lineal es un algoritmo de regresión supervisado. | También requiere que los datos que se introducen en él estén bien etiquetados. Sin embargo, este algoritmo se utiliza para la clasificación en lugar de la regresión. Entonces, la regresión logística es un algoritmo de clasificación supervisado. |
| La predicción obtenida a través del algoritmo de regresión lineal suele ser un valor que puede estar en el rango de infinito negativo a infinito positivo. | La predicción que se obtiene a través de la regresión logística está en realidad en el rango de cero a uno. Esta característica permite una fácil clasificación con la ayuda de un valor de umbral. |
| La regresión lineal no requiere ninguna función de activación. | Aquí necesitamos una función de activación. En este caso, esa función es la función sigmoidea. |
| No hay un valor de umbral en la regresión lineal. | En la regresión logística, se necesita un valor de umbral para determinar correctamente las clases de cada instancia. |
| La variable dependiente en el caso de la regresión lineal tiene que ser de naturaleza continua. Lo que significa que no podemos pasar la variable, que es categórica y esperar un valor continuo en la predicción. | La variable dependiente en el caso de la regresión logística tiene que ser categórica. Lo que significa que debe tener diferentes categorías (no más de dos). |
| El objetivo de este algoritmo es encontrar la línea de mejor ajuste a través de los puntos de datos de entrenamiento. Por lo tanto, la línea recta resultante, que dibujamos, debería tocar casi todos los puntos de entrenamiento si el ajuste no es ni por encima ni por debajo. | Si hacemos algún cambio en el coeficiente de la curva de regresión logística, todo el gráfico cambiará de forma. |
| Para predecir los valores, el algoritmo de regresión lineal hace una suposición fundamental. Asume que los valores que se pasan a este algoritmo siguen la distribución normal estándar o se distribuyen de acuerdo con la distribución gaussiana. | El algoritmo de regresión logística también asume la distribución de los datos que se pasan a la función sigmoidea. Asume que los datos siguen la distribución binomial. |
¿Querer aprender más?
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT- B Estado de exalumno, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿Cuáles son las desventajas de usar la regresión logística?
Un modelo de regresión logística anticipa una variable de datos dependiente al examinar la conexión entre una o más variables independientes preexistentes. La regresión logística, que se usa comúnmente para tareas de clasificación, tiene numerosas ventajas, pero también tiene algunos inconvenientes. Cuando se trabaja con conjuntos de datos de alta dimensión, puede ocurrir un ajuste excesivo del modelo, lo que da como resultado conclusiones inexactas. Dado que la preparación de datos es un procedimiento que requiere mucho tiempo cuando se emplea la regresión logística, el mantenimiento de datos también se vuelve difícil. Uno de los principales inconvenientes de la regresión logística es que no puede tratar problemas no lineales.
¿Qué se entiende por regresión logística multinomial?
La regresión logística multinomial es una extensión de regresión logística binaria que puede manejar más de dos variables dependientes o de resultado. Es similar a la regresión logística, excepto que hay muchos resultados posibles en lugar de uno solo. Es un enfoque tradicional de aprendizaje automático supervisado con capacidades de clasificación multiclase. El modelo logístico multinomial incluye varios supuestos, uno de los cuales es que se cree que los datos son específicos de cada caso, lo que significa que cada variable independiente tiene un valor único para cada caso. El modelo logístico multinomial también postula que en cualquier escenario dado, la variable dependiente no puede predecirse con precisión a partir de las variables independientes.
¿Cómo se puede usar la regresión lineal para resolver problemas de la vida real?
La regresión lineal se usa ampliamente en una variedad de situaciones y sectores del mundo real. Las empresas suelen utilizar la regresión lineal para comprender la relación entre publicidad, gastos y ganancias. Los investigadores médicos emplean con frecuencia la regresión lineal para examinar la asociación entre la dosis del medicamento y la presión arterial del paciente. Los científicos agrícolas emplean con frecuencia la regresión lineal para evaluar la influencia de los fertilizantes y el agua en el rendimiento de los cultivos. Por lo tanto, los usos de la regresión lineal son variados para resolver problemas de la vida real.