
Regressione lineare vs. Regressione logistica: differenza tra regressione lineare e regressione logistica
Pubblicato: 2020-09-10Il mondo del machine learning non sarebbe completo senza la presenza di due dei più semplici algoritmi di machine learning. Sì, sia la regressione lineare che la regressione logistica sono gli algoritmi di machine learning più semplici che puoi implementare. Prima di discutere le differenze tra regressione lineare e logistica, dobbiamo prima comprendere le basi su cui sono poste le basi di entrambi questi algoritmi.
Innanzitutto, entrambi questi algoritmi sono di natura di apprendimento supervisionato. Ciò significa che i dati che alimenterai in entrambi questi algoritmi dovrebbero essere ben etichettati. Un'altra cosa critica da notare sono i casi d'uso. A prima vista, una differenza evidente tra questi due algoritmi è i casi d'uso di entrambi. La regressione lineare viene utilizzata ogni volta che si desidera eseguire la regressione. Ciò significa che utilizziamo la regressione lineare ogni volta che vogliamo prevedere numeri continui, come i prezzi delle case in una particolare area.
Tuttavia, l'uso della regressione logistica viene fatto nei problemi di classificazione. In altre parole, se vogliamo prevedere se una particolare casa è costosa o poco costosa (invece del prezzo), utilizziamo l'algoritmo della regressione logistica. Sì, anche se la regressione logistica ha la parola regressione nel nome, viene utilizzata per la classificazione.
Ci sono altre sottigliezze così eccitanti che troverai elencate di seguito. Ma prima di confrontare frontalmente la regressione lineare con la regressione logistica, impariamo prima di tutto su ciascuno di questi algoritmi.
Sommario
Regressione lineare
La regressione lineare è l'algoritmo di machine learning più semplice e semplice da comprendere e implementare. È un algoritmo di apprendimento supervisionato, quindi se vogliamo prevedere i valori continui (o eseguire la regressione), dovremmo servire questo algoritmo con un set di dati ben etichettato. Questo algoritmo di apprendimento automatico è molto semplice a causa della sua natura lineare. Per prevedere con successo i valori futuri, la regressione lineare tenta di ottenere una linea retta attraverso i dati inseriti nell'algoritmo.
Quindi, ogni volta che un'informazione viene inserita in un algoritmo di regressione lineare, prende i dati e prende l'equazione di una retta, selezionando casualmente la pendenza e intercetta finché non trova la linea di adattamento migliore. Se i dati che inseriamo in questo algoritmo contengono solo una singola variabile indipendente, allora si parla di regressione lineare semplice.

D'altra parte, se i dati hanno più variabili indipendenti, la regressione diventa una regressione lineare multipla. La forma matematica della regressione lineare è semplicemente quella di una retta, che è mostrata di seguito.
y= a0+a1x+ c
Qui, y è la variabile dipendente, a0 e a1 è il coefficiente che questo algoritmo ha il compito di trovare, x è la variabile dipendente e c è il valore di intercetta di questa retta.
Regressione logistica
Inutile dire che la regressione logistica è uno degli algoritmi di apprendimento automatico di classificazione più semplici ma molto potenti sotto l'ombrello di un algoritmo di apprendimento supervisionato. Questo algoritmo può essere utilizzato per problemi di regressione, ma viene utilizzato principalmente per risolvere problemi di classificazione. L'output che otteniamo da questo algoritmo è sempre compreso tra 0 e 1, per cui diventa facile classificare le istanze in classi utilizzando un valore di classificazione di soglia.
La parola logistica nel nome si riferisce alla funzione di attivazione, utilizzata in questa regressione. La funzione di attivazione o la funzione logistica, in questo caso, non è in realtà altro che la funzione sigmoidea. È la proprietà di questa funzione sigmoidea, che mantiene il valore della regressione logistica sempre compreso tra zero e uno. La funzione sigmoide è simile a questa:
![]()
Qui, y è l'output attraverso la funzione sigmoide e x è la variabile indipendente. Nel caso della regressione logistica, la variabile x sarebbe effettivamente l'intera equazione di regressione lineare. Quindi, l'equazione per la regressione logistica può essere sviluppata, che è scritta di seguito:
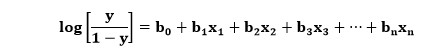
Qui il significato delle variabili è simile a quello della regressione logistica, x è la variabile indipendente e y è la variabile dipendente, b0, b1, b2, ecc., sono il coefficiente che questo algoritmo determina.

Differenza tra regressione lineare e logistica
Di seguito, troverai un confronto completo tra regressione lineare e regressione logistica fianco a fianco:
| REGRESSIONE LINEARE | REGRESSIONE LOGISTICA |
| Richiede dati ben etichettati, il che significa che necessita di supervisione e viene utilizzato per la regressione. Pertanto, la regressione lineare è un algoritmo di regressione supervisionato. | Richiede inoltre che i dati inseriti in esso siano ben etichettati. Tuttavia, questo algoritmo viene utilizzato per la classificazione anziché per la regressione. Quindi la regressione logistica è un algoritmo di classificazione supervisionato. |
| La previsione ottenuta tramite l'algoritmo di regressione lineare è solitamente un valore che può essere compreso tra l'infinito negativo e l'infinito positivo. | La previsione che si ottiene attraverso la regressione logistica è in realtà nell'intervallo da zero a uno. Questa caratteristica consente una facile classificazione con l'aiuto di un valore di soglia. |
| La regressione lineare non richiede alcuna funzione di attivazione. | Qui abbiamo bisogno di una funzione di attivazione. In questo caso, quella funzione è la funzione sigmoidea. |
| Non esiste un valore di soglia nella regressione lineare. | Nella regressione logistica, è necessario un valore di soglia per determinare correttamente le classi di ciascuna istanza. |
| La variabile dipendente nel caso della regressione lineare deve essere di natura continua. Ciò significa che non possiamo passare la variabile, che è categoriale e ci aspettiamo un valore continuo nella previsione. | La variabile dipendente nel caso della regressione logistica deve essere categoriale. Significa che dovrebbe avere categorie diverse (non più di due). |
| L'obiettivo di questo algoritmo è trovare la linea di adattamento migliore attraverso i punti dati di addestramento. Pertanto, la linea retta risultante, che disegniamo, dovrebbe toccare quasi tutti i punti di allenamento se l'adattamento non è né sopra né sotto. | Se apportiamo modifiche al coefficiente della curva di regressione logistica, l'intero grafico cambierà la sua forma. |
| Per prevedere i valori, l'algoritmo della regressione lineare fa un'assunzione fondamentale. Si presuppone che i valori passati a questo algoritmo seguano la distribuzione normale standard o siano distribuiti secondo la distribuzione gaussiana. | L'algoritmo di regressione logistica fa anche un'ipotesi sulla distribuzione dei dati che vengono passati nella funzione sigmoidea. Presuppone che i dati seguano la distribuzione binomiale. |
Vuoi saperne di più?
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Quali sono i contro dell'utilizzo della regressione logistica?
Un modello di regressione logistica anticipa una variabile di dati dipendente esaminando la connessione tra una o più variabili indipendenti preesistenti. La regressione logistica, comunemente utilizzata per le attività di classificazione, presenta numerosi vantaggi, ma presenta anche alcuni svantaggi. Quando si lavora con set di dati ad alta dimensione, può verificarsi un overfitting del modello, con conseguenti conclusioni imprecise. Poiché la preparazione dei dati è una procedura che richiede tempo quando si utilizza la regressione logistica, anche la manutenzione dei dati diventa difficile. Uno dei principali inconvenienti della regressione logistica è che non può affrontare problemi non lineari.
Cosa si intende per regressione logistica multinomiale?
La regressione logistica multinomiale è un'estensione di regressione logistica binaria che può gestire più di due variabili dipendenti o di risultato. È simile alla regressione logistica, tranne per il fatto che ci sono molti risultati possibili anziché uno solo. Si tratta di un tradizionale approccio di apprendimento automatico supervisionato con capacità di classificazione multi-classe. Il modello logistico multinomiale include vari presupposti, uno dei quali è che i dati siano considerati casi specifici, il che significa che ogni variabile indipendente ha un valore singolo per ogni istanza. Il modello logistico multinomiale postula anche che in un dato scenario, la variabile dipendente non può essere prevista con precisione dalle variabili indipendenti.
Come può essere utilizzata la regressione lineare per risolvere problemi della vita reale?
La regressione lineare è ampiamente utilizzata in una varietà di situazioni e settori del mondo reale. Le aziende in genere utilizzano la regressione lineare per comprendere la relazione tra pubblicità, spesa e profitto. I ricercatori medici utilizzano spesso la regressione lineare per esaminare l'associazione tra dose di medicinale e pressione sanguigna del paziente. Gli scienziati agrari utilizzano spesso la regressione lineare per valutare l'influenza dei fertilizzanti e dell'acqua sui raccolti. Pertanto, gli usi della regressione lineare sono vari nella risoluzione di problemi della vita reale.