
بنية الشبكة العصبية التلافيفية: ما الذي تحتاج إلى معرفته؟
نشرت: 2020-12-01الشبكات العصبية التلافيفية التي يطلق عليها عادة أسماء مثل ConvNets أو CNN هي واحدة من أكثر الشبكات العصبية استخدامًا. تُستخدم شبكات CNN بشكل عام للبيانات القائمة على الصور. يعد التعرف على الصور ، وتصنيف الصور ، واكتشاف الأشياء ، وما إلى ذلك ، بعض المجالات التي تستخدم فيها شبكات CNN على نطاق واسع.
يُطلق على فرع الذكاء الاصطناعي التطبيقي تحديدًا على بيانات الصورة اسم رؤية الكمبيوتر. كان هناك نمو هائل في رؤية الكمبيوتر منذ إدخال شبكات CNN. يستخرج الجزء الأول من CNN ميزات من الصور باستخدام وظيفة الالتفاف والتفعيل للتطبيع.
تستخدم الكتلة الأخيرة هذه الميزات مع الشبكة العصبية لحل أي مشكلة محددة ، على سبيل المثال ، سيكون لمشكلة التصنيف عدد "n" من الخلايا العصبية المخرجة اعتمادًا على عدد الفئات الموجودة للتصنيف. دعونا نحاول فهم بنية وعمل شبكة سي إن إن.
جدول المحتويات
التفاف
الالتفاف هو أسلوب لمعالجة الصور يستخدم نواة مرجحة (مصفوفة مربعة) للدوران فوق الصورة ، وضرب وإضافة عناصر النواة بوحدات بكسل الصورة. يمكن تصور هذه الطريقة بسهولة من خلال الصورة الموضحة أدناه.
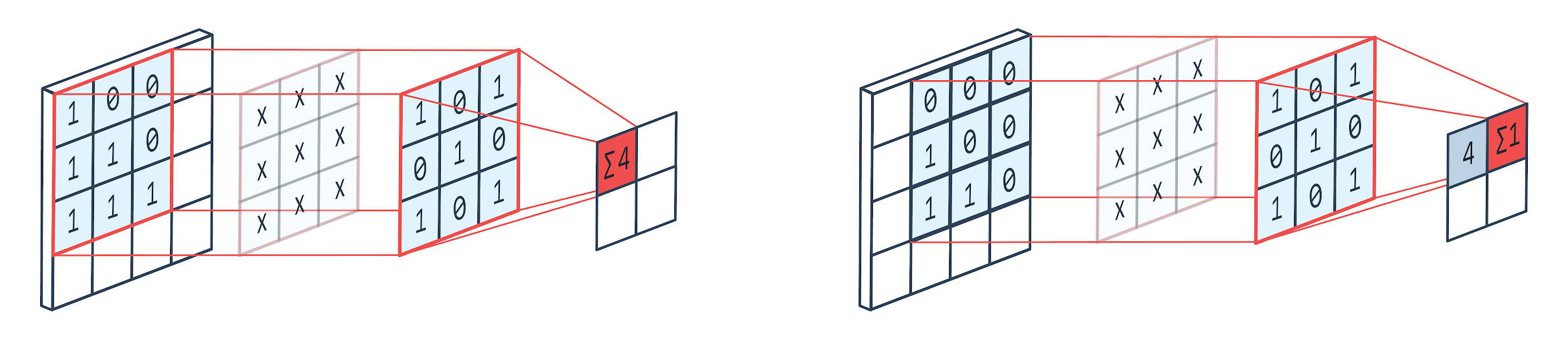
ملكية الصورة تعود إلى: بيلتاريون
مرشح الالتفاف والإخراج

كما نرى عندما نستخدم بيت تربية 3 × 3 ، يتم تشغيل جزء 3 × 3 من الصورة وبعد الضرب والإضافة اللاحقة ، تأتي قيمة واحدة كمخرج. إذن في صورة 4 × 4 ، سنحصل على ناتج مصفوفة ملتف 2 × 2 نظرًا لأن حجم النواة هو 3 × 3.
قد يختلف المخرجات الملتفة حسب حجم النواة المستخدمة للالتفاف. هذه هي طبقة البداية النموذجية لشبكة CNN. الناتج الملتوي هو الميزات الموجودة في الصورة. هذا مرتبط بشكل مباشر بحجم النواة المستخدم.
إذا كانت خاصية الصورة تجعلها حتى الاختلافات الصغيرة في الصورة تندرج في فئة مخرجات مختلفة ، فسيتم استخدام حجم نواة صغير لاستخراج الميزة. وإلا يمكن استخدام نواة أكبر. غالبًا ما تسمى القيم المستخدمة في النواة على أنها أوزان تلافيفية. يتم تهيئتها ثم تحديثها عند التكاثر العكسي باستخدام النسب المتدرج.
قراءة: برنامج TensorFlow لاكتشاف الأشياء للمبتدئين
تجمع
يتم وضع طبقة التجميع بين طبقات الالتفاف. وهي مسؤولة عن تنفيذ عمليات التجميع على خرائط المعالم المرسلة بواسطة طبقة الالتواء. تعمل عملية التجميع على تقليل الحجم المكاني للسمات المعروفة أيضًا باسم تقليل الأبعاد.
أحد الأسباب الرئيسية للتجميع هو تقليل القوة الحسابية المطلوبة لمعالجة البيانات. على الرغم من أن طبقة التجميع تقلل من حجم الصور ، إلا أنها تحافظ على خصائصها المهمة. العمل مشابه لمرشح CNN. تتخطى النواة الميزات وتجمع القيم التي يغطيها عامل التصفية.
يتضح من الصورة أنه يمكن أن يكون هناك وظائف تجميع مختلفة. يعد التجميع المتوسط والحد الأقصى من أكثر عمليات التجميع شيوعًا. يقلل التجميع من أبعاد الميزات ولكنه يحافظ على الخصائص سليمة.
من خلال تقليل عدد المعلمات ، تقل الحسابات أيضًا في الشبكة. هذا يقلل من التعلم الزائد ويزيد من كفاءة الشبكة. يتم استخدام الحد الأقصى للتجمع في الغالب لأن القيم القصوى يتم رصدها بدقة أقل في الخريطة المجمعة مقارنة بالخرائط من الالتواء.
هذا جيد للعديد من الحالات ، دعنا نقول إذا كان المرء يريد التعرف على كلب ، فلا حاجة إلى تحديد موقع أذنيه بدقة قدر الإمكان ، مع العلم أنهما يقعان بجوار الرأس تقريبًا.
يعمل Max Pooling أيضًا كمانع للضوضاء. إنه يتجاهل عمليات التنشيط الصاخبة تمامًا ويقوم أيضًا بإزالة الضوضاء جنبًا إلى جنب مع تقليل الأبعاد. من ناحية أخرى ، يقوم متوسط التجميع ببساطة بتقليل الأبعاد كآلية لقمع الضوضاء. ومن ثم ، يمكننا القول أن أداء Max Pooling أفضل بكثير من متوسط التجميع.
وظيفة التنشيط
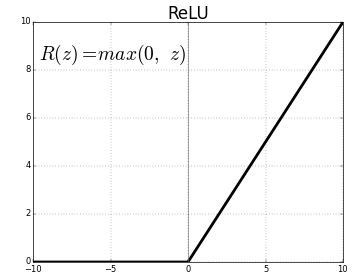
ReLU (الوحدات الخطية المصححة) هي طبقة وظيفة التنشيط الأكثر استخدامًا.
المعادلة لنفسه هي: ReLU (x) = max (0، x)
ويرد تمثيل رسومي أدناه:
المصدر: متوسط
تمثيل ReLU
يعين ReLU القيم السالبة إلى الصفر ويحافظ على الإيجابيات كما هي.
طبقة متصلة بالكامل
عادةً ما تكون الطبقة المتصلة بالكامل هي الطبقة الأخيرة من أي شبكة عصبية. تستقبل هذه الطبقة نواقل الإدخال وتنتج طبقة إخراج جديدة. تحتوي طبقة الإخراج هذه على عدد n من الخلايا العصبية حيث n هو عدد الفئات في تصنيف الصورة. يوفر كل عنصر من عناصر المتجه احتمالية أن تكون الصورة من فئة معينة. ومن ثم يكون مجموع جميع المتجهات في طبقة الإخراج دائمًا 1.
العمليات الحسابية التي تحدث في طبقة الإخراج هي كما يلي:

- عنصر مضروبا بوزن العصبون
- تطبيق وظيفة التنشيط على الطبقة (اللوجيستية عندما ن = 2 ، السيني عندما ن> 2)
سيكون الإخراج الآن هو احتمال انتماء الصورة إلى فئة معينة. يتم التعرف على أوزان الطبقة أثناء التدريب عن طريق الانتشار العكسي للتدرج.
اقرأ أيضًا: مقدمة نموذج الشبكة العصبية
طبقة التسرب
تعمل الطبقات المنسدلة كطبقة تنظيم تقلل من فرط التخصيص وتحسن خطأ التعميم. يعد التخصيص مصدر قلق كبير أثناء استخدام الشبكة العصبية. التسرب كما يوحي الاسم يسقط بعض النسبة المئوية للخلايا العصبية في الطبقات التي يتم استخدامها بعدها.
طريقة التنظيم التي يستخدمها التسرب هي أنه يقترب من تدريب عدد كبير من الشبكات العصبية ذات البنى المتوازية المختلفة. خلال فترة التدريب ، يتم إسقاط بعض نواتج الطبقة أو تجاهلها بشكل عشوائي. هذا يجعل الطبقة تبدو وكأنها طبقة بأعداد مختلفة من العقد ويتم إيقاف تشغيل بعض الخلايا العصبية. ومن ثم يتغير الاتصال أيضًا وفقًا للطبقة السابقة.
Hyperparameters
هناك معلمات معينة يمكن التحكم فيها وفقًا لبيانات الصورة التي يتم التعامل معها. يمكن تحديد معلمات لكل طبقة من طبقات CNN ، سواء كانت طبقة التفاف أو طبقة تجميع. تؤثر المعلمات على حجم خريطة المعالم التي تُعد ناتج تلك الطبقة المحددة.
كل صورة (إدخال) أو خريطة معالم (مخرجات لاحقة للطبقات) لها أبعاد: W x H x D حيث W x H هو العرض x الارتفاع ، أي حجم الخريطة أو الصورة. يمثل D البعد على أساس شرائح اللون. ستحتوي الصور أحادية اللون على D = 1 و RGB ، أي أن الصور الملونة سيكون لها D = 3.
المعايير الفوقية لطبقة الالتواء
- عدد المرشحات (K)
- حجم المرشح (F) للبعد FxFxD
- الخطوات: عدد الخطوات التي تتخذها النواة للتحول فوق الصورة. تعني S = 1 أن النواة ستتحرك بمقدار 1 بكسل كخطوة.
- الحشو الصفري: يتم إجراء حشوة صفرية للصور ذات الحجم الأقل ، لأن طبقات الالتفاف والحد الأقصى للتجمع يقللان من حجم خريطة المعالم في كل تكرار.
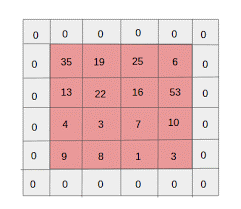
المصدر: XRDS
زاد الحشو الصفري من حجم الصورة المدخلة
لكل صورة إدخال بالحجم W × H × D ، تقوم طبقة التجميع بإرجاع مصفوفة من الأبعاد Wc × Hc × Dc. أين
Wc = (W-F + 2P) / S + 1
Hc = (H-F + 2P) / S + 1
العاصمة = ك
حل المعادلات لإيجاد قيمة الحشو (P) = F-1/2 و Stride (S) = 1
بشكل عام ، نختار بعد ذلك F = 3 ، P = 1 ، S = 1 أو F = 5 ، P = 2 ، S = 1
تجميع المعلمات الفوقية طبقة
- حجم الخلية (F): حجم الخلية المربعة التي سيتم تقسيم الخريطة عليها للتجميع. FxF
- حجم الخطوة (S): يتم فصل الخلايا ببكسل S.
لكل صورة إدخال بالحجم W × H × D ، تقوم طبقة التجميع بإرجاع مصفوفة من الأبعاد Wp × Hp × Dp ، حيث
Wp = (WF) / S + 1
حصان = (HF) / S + 1
موانئ دبي = د
بالنسبة لطبقة التجميع ، يتم اختيار F = 2 و S = 2 على نطاق واسع. يتم التخلص من 75٪ من وحدات البكسل المدخلة. يمكن للمرء أيضًا اختيار F = 3 و S = 2. سيؤدي حجم الخلية الأكبر إلى فقد كبير للمعلومات ، وبالتالي فهو مناسب فقط لصور الإدخال كبيرة الحجم.
المعلمات التشعبية العامة
- معدل التعلم: يمكن اختيار أدوات تحسين مثل SGD أو AdaGrad أو RMSProp لتحسين معدل التعلم.
- العهود: يجب زيادة عدد العهود حتى تظهر فجوة في التدريب وخطأ التحقق من الصحة
- حجم الدفعة: يمكن تحديد 16 إلى 128. يعتمد على مقدار قوة المعالجة التي يمتلكها المرء.
- وظيفة التنشيط: إدخال اللاخطية للنموذج. يتم استخدام ReLu عادةً لشبكات التحويل. الخيارات الأخرى هي: السيني ، تانه.
- التسرب: قيمة التسرب 0.1 تسقط 10٪ من الخلايا العصبية. 0.5 نقطة انطلاق جيدة. 0.25 خيار نهائي جيد.
- تهيئة الوزن: يمكن تهيئة الأوزان العشوائية الصغيرة لتشتيت احتمالية موت الخلايا العصبية. لكنها ليست صغيرة جدًا بالنسبة للهبوط المتدرج. التوزيع الموحد مناسب.
- الطبقات المخفية: يمكن زيادة الطبقات المخفية حتى يقل خطأ الاختبار. ستؤدي زيادة الطبقات المخفية إلى زيادة الحساب وتتطلب التنظيم.
خاتمة
لدينا المعلومات الأساسية لإنشاء CNN من البداية. على الرغم من أنها مقالة شاملة تغطي كل شيء على المستوى الأساسي ، يمكن التعمق في كل معلمة أو طبقة. الرياضيات وراء كل مفهوم هي أيضًا شيء يمكن فهمه لتحسين النموذج
إذا كنت مهتمًا بمعرفة المزيد حول التعلم الآلي ، فراجع دبلوم PG في IIIT-B & upGrad في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، IIIT- حالة الخريجين B ، أكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع أفضل الشركات.