
Architettura della rete neurale convoluzionale: cosa devi sapere?
Pubblicato: 2020-12-01Le reti neurali convoluzionali solitamente chiamate con nomi come ConvNets o CNN sono una delle architetture di rete neurale più comunemente utilizzate. Le CNN sono generalmente utilizzate per i dati basati su immagini. Il riconoscimento delle immagini, la classificazione delle immagini, il rilevamento di oggetti, ecc., sono alcune delle aree in cui le CNN sono ampiamente utilizzate.
La branca dell'IA applicata specificatamente sui dati di immagine è denominata Visione artificiale. C'è stata una crescita monumentale in Computer Vision dall'introduzione delle CNN. La prima parte della CNN estrae le caratteristiche dalle immagini utilizzando la convoluzione e la funzione di attivazione per la normalizzazione.
L'ultimo blocco utilizza queste funzionalità con Neural Network per risolvere qualsiasi problema specifico, ad esempio un problema di classificazione avrà un numero 'n' di neuroni di output a seconda del numero di classi presenti per la classificazione. Cerchiamo di capire l'architettura e il funzionamento di una CNN.
Sommario
Convoluzione
La convoluzione è una tecnica di elaborazione delle immagini che utilizza un kernel ponderato (matrice quadrata) per ruotare sull'immagine, moltiplicare e aggiungere gli elementi del kernel con i pixel dell'immagine. Questo metodo può essere facilmente visualizzato dall'immagine mostrata di seguito.
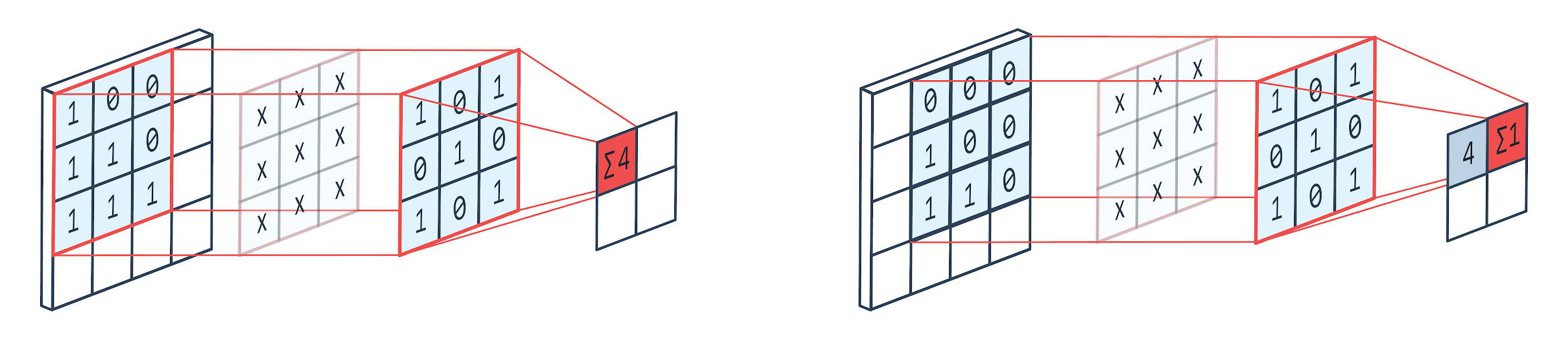
Immagine di: Peltarion
Filtro e uscita di convoluzione

Come possiamo vedere quando utilizziamo un canile a convoluzione 3×3, viene utilizzata una parte 3×3 dell'immagine e dopo la moltiplicazione e la successiva addizione, viene visualizzato un valore come output. Quindi su un'immagine 4 × 4 otterremo un output di matrice contorta 2 × 2 dato che la dimensione del kernel è 3 × 3.
L'output contorto può variare in base alla dimensione del kernel utilizzato per la convoluzione. Questo è il tipico livello di partenza di una CNN. L'output contorto sono le caratteristiche trovate dall'immagine. Questo è direttamente correlato alla dimensione del kernel in uso.
Se la caratteristica di un'immagine è tale che anche piccole differenze in un'immagine la faranno rientrare in una categoria di output diversa, per l'estrazione delle caratteristiche viene utilizzata una dimensione del kernel ridotta. Altrimenti è possibile utilizzare un kernel più grande. I valori utilizzati nel kernel sono spesso definiti come pesi convoluzionali. Questi vengono inizializzati e quindi aggiornati alla backpropagation utilizzando la discesa del gradiente.
Leggi: Tutorial sul rilevamento di oggetti TensorFlow per principianti
Raggruppamento
Lo strato di pooling viene posizionato tra gli strati di convoluzione. È responsabile dell'esecuzione delle operazioni di raggruppamento sulle mappe delle caratteristiche inviate da un livello di convoluzione. L'operazione di pooling riduce la dimensione spaziale delle caratteristiche note anche come riduzione della dimensionalità.
Uno dei motivi principali per il pooling è la riduzione della potenza di calcolo richiesta per elaborare i dati. Sebbene un livello di pooling riduca le dimensioni delle immagini, ne preserva le caratteristiche importanti. Il funzionamento è simile a un filtro CNN. Il kernel esamina le funzionalità e aggrega i valori coperti dal filtro.
Dall'immagine è ben visibile che possono esserci diverse funzioni di aggregazione. Il pooling medio e massimo sono le operazioni di pooling più comunemente utilizzate. Il pooling riduce le dimensioni delle caratteristiche ma mantiene intatte le caratteristiche.
Riducendo il numero di parametri, i calcoli si riducono anche nella rete. Ciò riduce l'apprendimento eccessivo e aumenta l'efficienza della rete. Il max-pool viene utilizzato principalmente perché i valori massimi vengono individuati in modo meno accurato nella mappa raggruppata rispetto alle mappe della convoluzione.
Questo va bene in molti casi. Diciamo che se si vuole riconoscere un cane, non è necessario che le sue orecchie siano posizionate nel modo più preciso possibile, basta sapere che si trovano quasi vicino alla testa.
Max Pooling funziona anche come soppressore del rumore. Elimina del tutto le attivazioni rumorose ed esegue anche la riduzione del rumore insieme alla riduzione della dimensionalità. D'altra parte, Average Pooling esegue semplicemente la riduzione della dimensionalità come meccanismo di soppressione del rumore. Quindi, possiamo dire che Max Pooling funziona molto meglio di Average Pooling.
Funzione di attivazione
ReLU (Rectified Linear Units) è il livello di funzione di attivazione più comunemente utilizzato.
L'equazione per lo stesso è: ReLU(x)=max(0,x)
E la rappresentazione grafica è data di seguito:
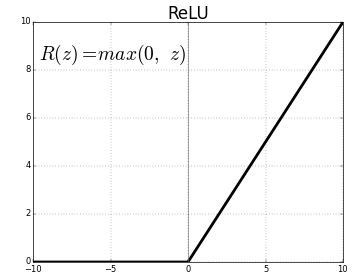
Fonte: medio
Rappresentanza ReLU
ReLU mappa i valori negativi su zero e mantiene i positivi così come sono.
Livello completamente connesso
Un livello completamente connesso è solitamente l'ultimo livello di qualsiasi rete neurale. Questo livello riceve i vettori di input e produce un nuovo livello di output. Questo livello di output ha n numero di neuroni dove n è il numero di classi nella classificazione dell'immagine. Ogni elemento del vettore fornisce la probabilità che l'immagine sia di una certa classe. Quindi la somma di tutti i vettori nel livello di output è sempre 1.

I calcoli che avvengono nel livello di output sono i seguenti:
- Elemento moltiplicato per il peso del neurone
- Applicare la funzione di attivazione sul livello (logistica quando n=2, sigmoide quando n>2)
L'output sarà ora la probabilità che l'immagine appartenga a una certa classe. I pesi dello strato vengono appresi durante l'allenamento mediante backpropagation del gradiente.
Leggi anche: Introduzione al modello di rete neurale
Strato di abbandono
I livelli di esclusione funzionano come un livello di regolarizzazione che riduce l'overfitting e migliora l'errore di generalizzazione. L'overfitting è una delle principali preoccupazioni durante l'utilizzo di una rete neurale. Dropout, come suggerisce il nome, elimina una certa percentuale di neurone negli strati dopo i quali viene utilizzato.
Il metodo di regolarizzazione impiegato dal dropout è che si avvicina all'addestramento di un gran numero di reti neurali con diverse architetture parallele. Durante il periodo di addestramento, alcuni degli output del livello vengono eliminati o ignorati in modo casuale. Questo fa sembrare il livello uno strato con un numero diverso di nodi e alcuni neuroni sono disattivati. Quindi anche la connettività cambia in base al livello precedente.
Iperparametri
Ci sono alcuni parametri che possono essere controllati in base ai dati dell'immagine trattati. Ciascun livello di una CNN può essere parametrizzato, sia esso livello di convoluzione o livello di pooling. I parametri influiscono sulla dimensione della mappa delle caratteristiche che è l'output per quel layer specifico.
Ogni immagine (input) o mappa caratteristica (output successivi dei livelli) ha le dimensioni: L x A x P dove L x A è larghezza x altezza, ovvero la dimensione della mappa o dell'immagine. D rappresenta la dimensione sulla base dei segmenti di colore. Le immagini in bianco e nero avranno D=1 e le immagini a colori RGB, ad esempio, avranno D=3.
Iperparametri del livello di convoluzione
- Numero di filtri (K)
- Dimensione del filtro (F) della dimensione FxFxD
- Strides: numero di passaggi eseguiti dal kernel per spostarsi sull'immagine. S=1 significa che il kernel si sposterà con 1 pixel come passaggio.
- Zero padding: il riempimento zero viene eseguito per le immagini di dimensioni inferiori, poiché la convoluzione e i livelli massimi del pool riducono le dimensioni della mappa delle caratteristiche ad ogni iterazione.
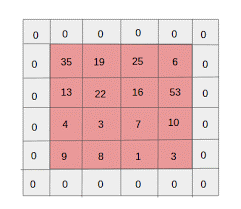
Fonte: XRDS
Il riempimento zero ha aumentato le dimensioni dell'immagine di input
Per ogni immagine di input di dimensione L×A×P, il livello di raggruppamento restituisce una matrice di dimensioni Wc×Hc×Dc. Dove
Bc= (V-V+2P)/V+1
Hc= (H-F+2P)/S+1
Dc= K
Risolvere le equazioni per trovare il valore di Padding(P)=F-1/2 e Stride(S)=1
In generale, scegliamo quindi F=3,P=1,S=1 o F=5,P=2,S=1
Raggruppamento degli iperparametri del livello
- Dimensione cella (F): la dimensione della cella quadrata in cui verrà suddivisa la mappa per il raggruppamento. FxF
- Dimensioni del passaggio (S): le celle sono separate da S pixel
Per ogni immagine di input di dimensione L×A×P, il livello di pooling restituisce una matrice di dimensioni Wp×Hp×P, dove
Wp= (WF)/S+1
Hp= (AC)/S+1
Dp= D
Per lo strato di pooling, F=2 e S=2 è ampiamente scelto. Il 75% dei pixel di input viene eliminato. Si può anche scegliere F=3 e S=2. Una cella di dimensioni maggiori comporterà una grande perdita di informazioni, quindi adatta solo per immagini di input di dimensioni molto grandi.
Iperparametri generali
- Tasso di apprendimento: è possibile scegliere ottimizzatori come SGD, AdaGrad o RMSProp per ottimizzare il tasso di apprendimento.
- Epoche: il numero di Epoche deve essere aumentato fino a quando non viene visualizzata una lacuna nell'addestramento e nell'errore di convalida
- Dimensione del lotto: è possibile selezionare da 16 a 128. Dipende dalla quantità di potenza di elaborazione che si ha.
- Funzione di attivazione: introduce la non linearità nel modello. ReLu viene in genere utilizzato per le reti conv. Altre opzioni sono: sigmoide, tanh.
- Dropout: un valore di dropout di 0,1 fa cadere il 10% dei neuroni. 0,5 è un buon punto di partenza. 0,25 è una buona opzione finale.
- Inizializzazione del peso: è possibile inizializzare piccoli pesi casuali per deviare la possibilità di neuroni morti. Ma non troppo piccolo per la discesa in pendenza. La distribuzione uniforme è adatta.
- Livelli nascosti: i livelli nascosti possono essere aumentati finché l'errore di test non diminuisce. L'aumento dei livelli nascosti aumenterà il calcolo e richiederà la regolarizzazione.
Conclusione
Abbiamo le informazioni di base per creare una CNN da zero. Sebbene sia un articolo completo che copre tutto a livello di base, ogni parametro o livello può essere approfondito. La matematica dietro ogni concetto è anche qualcosa che può essere compreso per il miglioramento del modello
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.