
Архитектура сверточной нейронной сети: что нужно знать?
Опубликовано: 2020-12-01Сверточные нейронные сети, обычно называемые такими именами, как ConvNets или CNN, являются одной из наиболее часто используемых архитектур нейронных сетей. CNN обычно используются для данных на основе изображений. Распознавание изображений, классификация изображений, обнаружение объектов и т. д. — вот некоторые из областей, в которых широко используются CNN.
Раздел прикладного ИИ, специально предназначенный для данных изображения, называется компьютерным зрением. С момента появления CNN произошел монументальный рост компьютерного зрения. Первая часть CNN извлекает признаки из изображений, используя функцию свертки и активации для нормализации.
Последний блок использует эти функции с нейронной сетью для решения любой конкретной проблемы, например, проблема классификации будет иметь «n» количество выходных нейронов в зависимости от количества классов, представленных для классификации. Давайте попробуем понять архитектуру и работу CNN.
Оглавление
свертка
Свертка — это метод обработки изображений, в котором используется взвешенное ядро (квадратная матрица) для вращения по изображению, умножения и добавления элементов ядра с пикселями изображения. Этот метод можно легко представить на изображении, показанном ниже.
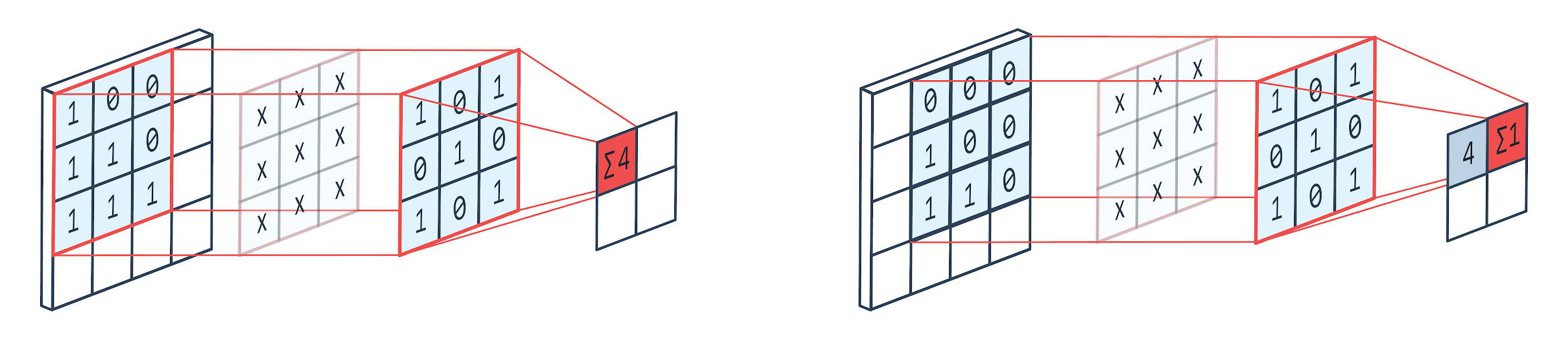
Изображение: Пелтарион
Фильтр свертки и вывод

Как мы видим, когда мы используем сверточный питомник 3×3, обрабатывается часть изображения 3×3, и после умножения и последующего сложения на выходе получается одно значение. Таким образом, на изображении 4 × 4 мы получим свернутую матрицу 2 × 2, учитывая, что размер ядра равен 3 × 3.
Свернутый вывод может варьироваться в зависимости от размера ядра, используемого для свертки. Это типичный начальный уровень CNN. Свернутый результат — это функции, найденные на изображении. Это напрямую связано с размером используемого ядра.
Если характеристики изображения таковы, что даже небольшие различия в изображении заставят его попасть в другую категорию вывода, тогда для извлечения признаков используется небольшой размер ядра. В противном случае можно использовать большее ядро. Значения, используемые в ядре, часто называют сверточными весами. Они инициализируются, а затем обновляются при обратном распространении с использованием градиентного спуска.
Читайте: Учебное пособие по обнаружению объектов TensorFlow для начинающих
Объединение
Слой пула помещается между слоями свертки. Он отвечает за выполнение операций объединения на картах объектов, отправленных слоем свертки. Операция объединения уменьшает пространственный размер объектов, также известный как уменьшение размерности.
Одной из основных причин объединения является снижение вычислительной мощности, необходимой для обработки данных. Хотя объединяющий слой уменьшает размер изображений, он сохраняет их важные характеристики. Работа похожа на фильтр CNN. Ядро просматривает функции и агрегирует значения, покрываемые фильтром.
Из изображения хорошо видно, что могут быть различные функции агрегации. Среднее и максимальное объединение являются наиболее часто используемыми операциями объединения. Объединение уменьшает размеры элементов, но сохраняет характеристики нетронутыми.
За счет уменьшения количества параметров сокращаются и расчеты в сети. Это снижает избыточное обучение и повышает эффективность сети. Максимальный пул в основном используется, потому что максимальные значения определяются менее точно в объединенной карте по сравнению с картами из свертки.
Это хорошо во многих случаях. Скажем, если вы хотите распознать собаку, ее уши не нужно располагать как можно точнее, достаточно знать, что они расположены почти рядом с головой.
Max Pooling также работает как шумоподавитель. Он полностью отбрасывает шумовые активации, а также выполняет шумоподавление вместе с уменьшением размерности. С другой стороны, Average Pooling просто выполняет уменьшение размерности в качестве механизма подавления шума. Следовательно, мы можем сказать, что максимальный пул работает намного лучше, чем средний пул.
Функция активации
ReLU (выпрямленные линейные единицы) — это наиболее часто используемый уровень функции активации.
Уравнение для того же: ReLU(x)=max(0,x)
И графическое представление приведено ниже:
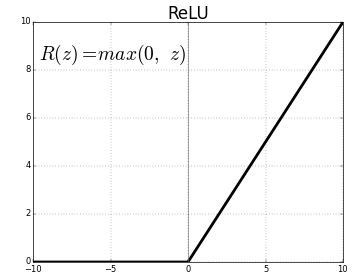
Источник: Средний
Представление ReLU
ReLU сопоставляет отрицательные значения с нулем и сохраняет положительные значения как есть.
Полностью подключенный слой
Полносвязный слой обычно является последним слоем любой нейронной сети. Этот слой получает входные векторы и создает новый выходной слой. Этот выходной слой имеет n нейронов, где n — количество классов в классификации изображения. Каждый элемент вектора обеспечивает вероятность того, что изображение принадлежит определенному классу. Следовательно, сумма всех векторов в выходном слое всегда равна 1.

Вычисления, происходящие в выходном слое, выглядят следующим образом:
- Элемент, умноженный на вес нейрона
- Примените функцию активации к слою (логистическая при n=2, сигмоидальная при n>2)
Результатом теперь будет вероятность принадлежности изображения к определенному классу. Веса слоя изучаются во время обучения путем обратного распространения градиента.
Читайте также: Введение в модель нейронной сети
Выпадающий слой
Слои исключения работают как слой регуляризации, который уменьшает переоснащение и улучшает ошибку обобщения. Переоснащение является серьезной проблемой при использовании нейронной сети. Dropout, как следует из названия, выбрасывает некоторый процент нейронов в слоях, после которых он используется.
Метод регуляризации, используемый отсевом, заключается в том, что он приближает обучение большого количества нейронных сетей с различными параллельными архитектурами. В течение периода обучения некоторые выходные данные слоя случайным образом удаляются или игнорируются. Это делает слой похожим на слой с разным количеством узлов, а некоторые нейроны отключены. Следовательно, связь также изменяется в соответствии с предыдущим уровнем.
Гиперпараметры
Существуют определенные параметры, которыми можно управлять в соответствии с обрабатываемыми данными изображения. Каждый уровень CNN может быть параметризован, будь то слой свертки или слой пула. Параметры влияют на размер карты объектов, которая является выходной для этого конкретного слоя.
Каждое изображение (входное) или карта объектов (последующие выходные слои) имеют размеры: Ш x В x Г, где Ш x В — ширина x высота, то есть размер карты или изображения. D представляет измерение на основе цветовых сегментов. Монохромные изображения будут иметь D=1 и RGB, т.е. цветные изображения будут иметь D=3.
Гиперпараметры слоя свертки
- Количество фильтров (К)
- Размер фильтра (F) размерности FxFxD
- Шаги: количество шагов, предпринятых ядром для перемещения по изображению. S=1 означает, что ядро будет двигаться с шагом 1 пиксель.
- Нулевое заполнение: нулевое заполнение выполняется для изображений меньшего размера, потому что слои свертки и максимального пула уменьшают размер карты объектов на каждой итерации.
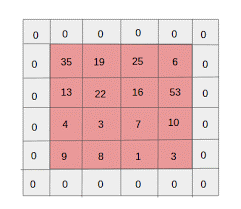
Источник: XRDS
Заполнение нулями увеличило размер входного изображения
Для каждого входного изображения размера W×H×D объединяющий слой возвращает матрицу размеров Wc×Hc×Dc. Где
Wc= (W-F+2P)/S+1
Hc= (H-F+2P)/S+1
Дк = К
Решение уравнений для нахождения значений Padding(P)=F-1/2 и Stride(S)=1
Обычно мы выбираем F=3,P=1,S=1 или F=5,P=2,S=1.
Гиперпараметры слоя пула
- Размер ячейки (F): Размер квадратной ячейки, на которую будет разделена карта для объединения. ФхФ
- Размер шага (S): ячейки разделены S пикселями.
Для каждого входного изображения размера W×H×D объединяющий слой возвращает матрицу размеров Wp×Hp×Dp, где
Wp= (WF)/S+1
Hp= (HF)/S+1
Др= Д
Для слоя объединения обычно выбирают F=2 и S=2. 75% входных пикселей удаляются. Можно также выбрать F=3 и S=2. Большой размер ячейки приведет к большой потере информации, поэтому подходит только для входных изображений очень большого размера.
Общие гиперпараметры
- Скорость обучения: для оптимизации скорости обучения можно выбрать такие оптимизаторы, как SGD, AdaGrad или RMSProp.
- Эпохи: количество эпох следует увеличивать до тех пор, пока не появится пробел в обучении и ошибка проверки.
- Размер партии: можно выбрать от 16 до 128. Зависит от количества вычислительной мощности, которая у него есть.
- Функция активации: вводит нелинейность в модель. ReLu обычно используется для Conv Nets. Другие варианты: сигмовидная, танх.
- Отсев: значение отсева 0,1 отбрасывает 10% нейронов. 0,5 - хорошая отправная точка. 0,25 - хороший окончательный вариант.
- Инициализация веса: небольшие случайные веса могут быть инициализированы, чтобы отклонить возможность мертвых нейронов. Но не слишком мало для градиентного спуска. Подходит равномерное распределение.
- Скрытые слои: Скрытые слои можно увеличивать до тех пор, пока ошибка теста не уменьшится. Увеличение числа скрытых слоев увеличит объем вычислений и потребует регуляризации.
Заключение
У нас есть основная информация для создания CNN с нуля. Хотя это всеобъемлющая статья, которая охватывает все на базовом уровне, каждый параметр или уровень можно изучить глубже. Математика, стоящая за каждой концепцией, также может быть понята для улучшения модели.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, IIIT- Статус B Alumni, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.