
畳み込みニューラルネットワークアーキテクチャ:知っておくべきこと
公開: 2020-12-01通常、ConvNetsやCNNなどの名前で呼ばれる畳み込みニューラルネットワークは、最も一般的に使用されるニューラルネットワークアーキテクチャの1つです。 CNNは通常、画像ベースのデータに使用されます。 画像認識、画像分類、オブジェクト検出などは、CNNが広く使用されている分野の一部です。
特に画像データに関するAppliedAIのブランチは、コンピュータービジョンと呼ばれます。 CNNの導入以来、コンピュータービジョンは飛躍的に成長しています。 CNNの最初の部分は、正規化のための畳み込みおよび活性化関数を使用して画像から特徴を抽出します。
最後のブロックは、ニューラルネットワークでこれらの機能を使用して特定の問題を解決します。たとえば、分類問題には、分類に存在するクラスの数に応じて、「n」個の出力ニューロンがあります。 CNNのアーキテクチャと動作を理解してみましょう。
目次
畳み込み
畳み込みは、重み付きカーネル(正方行列)を使用して画像上で回転し、カーネル要素に画像ピクセルを乗算および追加する画像処理技術です。 この方法は、以下の画像で簡単に視覚化できます。
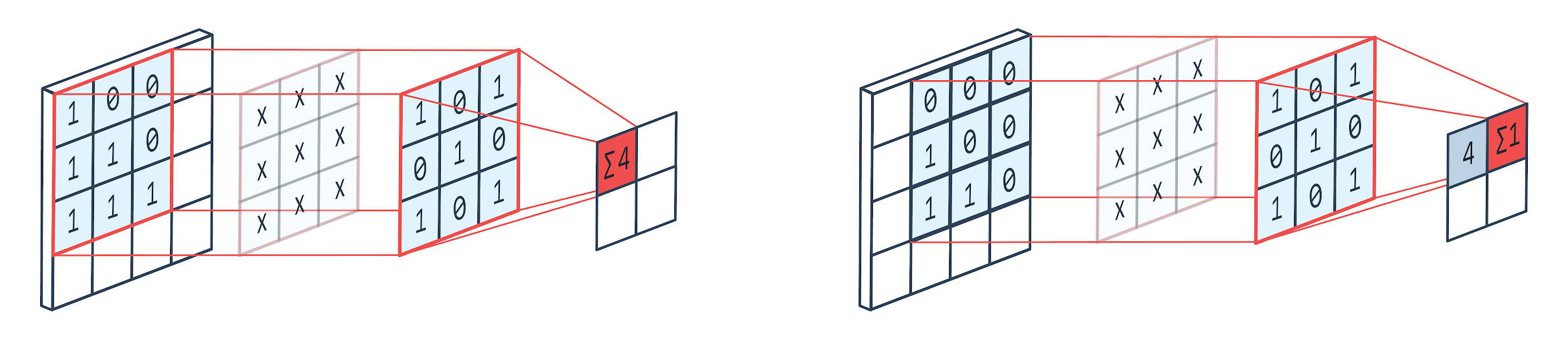
画像提供: Peltarion
畳み込みフィルターと出力

3×3の畳み込み犬舎を使用するとわかるように、画像の3×3の部分が操作され、乗算とその後の加算の後に、1つの値が出力として提供されます。 したがって、4×4の画像では、カーネルサイズが3×3の場合、2×2の複雑なマトリックス出力が得られます。
畳み込み出力は、畳み込みに使用されるカーネルのサイズによって異なる場合があります。 これは、CNNの典型的な開始層です。 複雑な出力は、画像から見つかった特徴です。 これは、使用されているカーネルサイズに直接関係しています。
画像の特性が、画像のわずかな違いでも異なる出力カテゴリに分類されるようなものである場合、特徴抽出には小さなカーネルサイズが使用されます。 それ以外の場合は、より大きなカーネルを使用できます。 カーネルで使用される値は、畳み込み重みと呼ばれることがよくあります。 これらは初期化され、勾配降下法を使用した逆伝播時に更新されます。
読む:初心者向けのTensorFlowオブジェクト検出チュートリアル
プーリング
プーリングレイヤーは、畳み込みレイヤーの間に配置されます。 畳み込みレイヤーによって送信されたフィーチャマップに対してプーリング操作を実行する役割を果たします。 プーリング操作は、次元削減とも呼ばれるフィーチャの空間サイズを削減します。
プーリングの主な理由の1つは、データを処理するために必要な計算能力を減らすことです。 ただし、プーリングレイヤーは画像のサイズを縮小し、重要な特性を保持します。 動作はCNNフィルターに似ています。 カーネルは機能を調べ、フィルターによってカバーされる値を集約します。
画像から、さまざまな集計関数が存在する可能性があることがはっきりとわかります。 平均および最大プーリングは、最も一般的に使用されるプーリング操作です。 プーリングは機能の寸法を縮小しますが、特性はそのまま維持します。
パラメータの数を減らすことにより、ネットワーク内の計算も削減されます。 これにより、過剰学習が減り、ネットワークの効率が向上します。 max-poolが主に使用されるのは、畳み込みからのマップと比較して、プールされたマップで最大値が正確に検出されないためです。
これは多くの場合に適しています。犬を認識したい場合は、耳が頭のほぼ隣にあることを知っていれば、耳をできるだけ正確に配置する必要はありません。
Max Poolingは、ノイズ抑制剤としても機能します。 ノイズの多いアクティベーションを完全に破棄し、次元削減とともにノイズ除去も実行します。 一方、平均プーリングは、ノイズ抑制メカニズムとして次元削減を実行するだけです。 したがって、最大プーリングは平均プーリングよりもはるかに優れたパフォーマンスを発揮すると言えます。
活性化関数
ReLU(Rectified Linear Units)は、最も一般的に使用される活性化関数層です。
同じ式は次のとおりです。ReLU(x)= max(0、x)
そして、グラフィック表現を以下に示します。
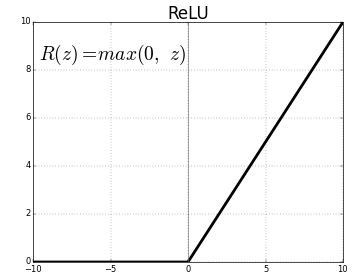
出典:中
ReLU表現
ReLUは負の値をゼロにマップし、正の値をそのまま保持します。
完全に接続されたレイヤー
完全に接続された層は通常、ニューラルネットワークの最後の層です。 このレイヤーは入力ベクトルを受け取り、新しい出力レイヤーを生成します。 この出力層にはn個のニューロンがあり、nは画像の分類におけるクラスの数です。 ベクトルの各要素は、画像が特定のクラスである確率を提供します。 したがって、出力層のすべてのベクトルの合計は常に1です。

出力層で行われる計算は次のとおりです。
- ニューロンの重量を掛けた要素
- 層に活性化関数を適用します(n = 2の場合はロジスティック、n> 2の場合はシグモイド)
出力は、特定のクラスに属する画像の確率になります。 層の重みは、勾配の逆伝播によってトレーニング中に学習されます。
また読む:ニューラルネットワークモデルの紹介
ドロップアウトレイヤー
ドロップアウトレイヤーは、過剰適合を減らし、汎化誤差を改善する正則化レイヤーとして機能します。 ニューラルネットワークを使用する場合、過剰適合は大きな懸念事項です。 名前が示すようにドロップアウトは、レイヤー内のニューロンの一部をドロップアウトし、その後使用されます。
ドロップアウトで採用されている正則化方法は、異なる並列アーキテクチャを使用した多数のニューラルネットワークのトレーニングを近似することです。 トレーニング期間中、一部のレイヤー出力はランダムにドロップまたは無視されます。 これにより、レイヤーはノード数が異なるレイヤーのように見え、一部のニューロンはオフになります。 したがって、接続性も前のレイヤーに従って変化します。
ハイパーパラメータ
扱われる画像データに応じて制御できる特定のパラメータがあります。 CNNの各層は、畳み込み層であれプーリング層であれ、パラメーター化できます。 パラメータは、その特定のレイヤーの出力である特徴マップのサイズに影響します。
各画像(入力)または特徴マップ(後続のレイヤーの出力)の次元は次のとおりです。Wx H x Dここで、W x Hは幅x高さ、つまりマップまたは画像のサイズです。 Dは、カラーセグメントに基づく寸法を表します。 モノクロ画像はD=1、RGB、つまりカラー画像はD=3になります。
畳み込み層のハイパーパラメータ
- フィルタの数(K)
- 寸法FxFxDのフィルター(F)のサイズ
- ストライド:カーネルがイメージ上をシフトするために実行したステップ数。 S = 1は、カーネルが1ピクセルをステップとして移動することを意味します。
- ゼロパディング:畳み込みと最大プールレイヤーにより、反復ごとに特徴マップのサイズが減少するため、サイズの小さい画像に対してゼロパディングが実行されます。
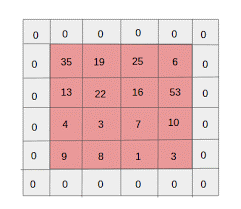
出典: XRDS
ゼロパディングにより、入力画像のサイズが大きくなりました
サイズW×H×Dの入力画像ごとに、プーリング層は次元Wc×Hc×Dcの行列を返します。 どこ
Wc =(W-F + 2P)/ S + 1
Hc =(H-F + 2P)/ S + 1
Dc = K
方程式を解いて、Padding(P)= F-1 / 2およびStride(S)=1の値を見つけます
一般に、次にF = 3、P = 1、S=1またはF=5、P = 2、S=1を選択します
プーリングレイヤーのハイパーパラメータ
- セルサイズ(F):プールのためにマップが分割される正方形のセルサイズ。 FxF
- ステップサイズ(S):セルはSピクセルで区切られます
サイズW×H×Dの入力画像ごとに、プーリングレイヤーは次元Wp×Hp×Dpの行列を返します。
Wp =(WF)/ S + 1
Hp =(HF)/ S + 1
Dp = D
プーリング層には、F=2およびS=2が広く選択されています。 入力ピクセルの75%が削除されます。 F=3およびS=2を選択することもできます。 セルサイズを大きくすると、情報が大幅に失われるため、非常に大きなサイズの入力画像にのみ適しています。
一般的なハイパーパラメータ
- 学習率:SGD、AdaGrad、RMSPropなどのオプティマイザーを選択して学習率を最適化できます。
- エポック:トレーニングと検証のエラーのギャップが現れるまで、エポックの数を増やす必要があります
- バッチサイズ:16〜128を選択できます。 持っている処理能力の量に依存します。
- 活性化関数:モデルに非線形性を導入します。 ReLuは通常、コンバージョンネットに使用されます。 その他のオプションは次のとおりです。sigmoid、tanh。
- ドロップアウト:ドロップアウト値0.1は、ニューロンの10%をドロップします。 0.5が出発点として適しています。 0.25は良い最終オプションです。
- 重みの初期化:小さなランダムな重みを初期化して、ニューロンが死んでいる可能性をそらすことができます。 しかし、最急降下法には小さすぎません。 一様分布が適しています。
- 非表示レイヤー:テストエラーが減少するまで、非表示レイヤーを増やすことができます。 隠れ層を増やすと、計算が増え、正則化が必要になります。
結論
CNNを最初から作成するための基本的な情報があります。 これは基本的なレベルですべてをカバーする包括的な記事ですが、各パラメーターまたはレイヤーをさらに深く掘り下げることができます。 すべての概念の背後にある数学も、モデルの改善のために理解できるものです。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのPGディプロマをご覧ください。これは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIIT-を提供します。 B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。