
Convolutional Neural Network Architecture: Was Sie wissen müssen
Veröffentlicht: 2020-12-01Convolutional Neural Networks, die normalerweise mit Namen wie ConvNets oder CNN bezeichnet werden, sind eine der am häufigsten verwendeten neuronalen Netzwerkarchitekturen. CNNs werden im Allgemeinen für bildbasierte Daten verwendet. Bilderkennung, Bildklassifizierung, Objekterkennung usw. sind einige der Bereiche, in denen CNNs weit verbreitet sind.
Der Zweig der angewandten KI speziell über Bilddaten wird als Computer Vision bezeichnet. Seit der Einführung von CNNs hat Computer Vision ein enormes Wachstum erlebt. Der erste Teil von CNN extrahiert Merkmale aus Bildern unter Verwendung von Faltungs- und Aktivierungsfunktion zur Normalisierung.
Der letzte Block verwendet diese Funktionen mit einem neuronalen Netzwerk, um ein bestimmtes Problem zu lösen, beispielsweise hat ein Klassifizierungsproblem eine Anzahl von „n“ Ausgabeneuronen, abhängig von der Anzahl der Klassen, die für die Klassifizierung vorhanden sind. Lassen Sie uns versuchen, die Architektur und Funktionsweise eines CNN zu verstehen.
Inhaltsverzeichnis
Faltung
Faltung ist eine Bildverarbeitungstechnik, die einen gewichteten Kern (quadratische Matrix) verwendet, um sich über das Bild zu drehen, die Kernelemente zu multiplizieren und mit Bildpixeln zu addieren. Diese Methode kann leicht durch das unten gezeigte Bild visualisiert werden.
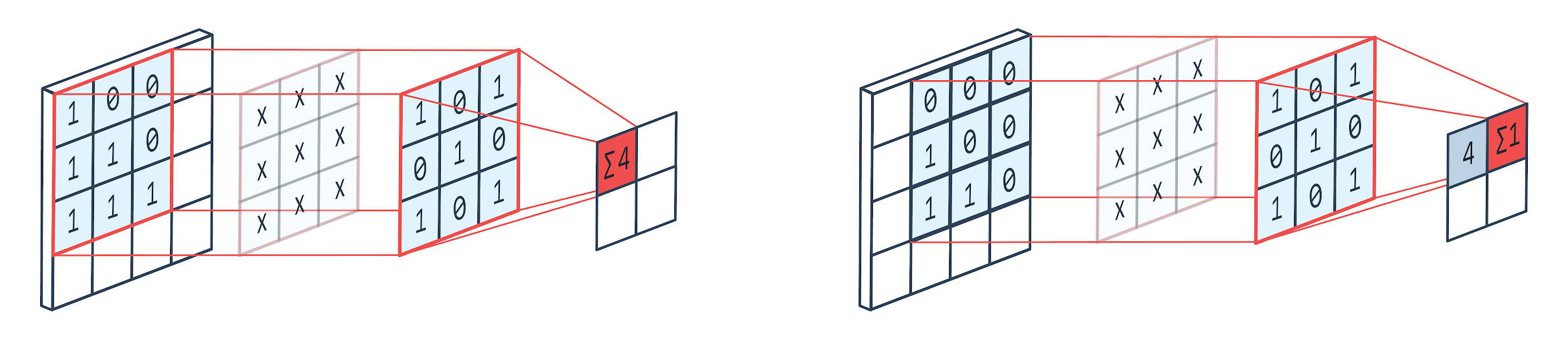
Bild von: Peltarion
Faltungsfilter und Ausgabe

Wie wir sehen können, wenn wir einen 3×3-Faltungszwinger verwenden, wird ein 3×3-Teil des Bildes bearbeitet und nach Multiplikation und anschließender Addition kommt ein Wert als Ausgabe. Auf einem 4 × 4-Bild erhalten wir also eine 2 × 2-Faltenmatrixausgabe, wenn die Kernelgröße 3 × 3 beträgt.
Die gefaltete Ausgabe kann je nach Größe des für die Faltung verwendeten Kernels variieren. Dies ist die typische Startschicht eines CNN. Die verschachtelte Ausgabe sind die Merkmale, die aus dem Bild gefunden wurden. Dies hängt direkt mit der verwendeten Kernelgröße zusammen.
Wenn die Eigenschaft eines Bildes so ist, dass selbst kleine Unterschiede in einem Bild dazu führen, dass es in eine andere Ausgabekategorie fällt, wird eine kleine Kernelgröße für die Merkmalsextraktion verwendet. Andernfalls kann ein größerer Kern verwendet werden. Die im Kernel verwendeten Werte werden oft als Faltungsgewichte bezeichnet. Diese werden initialisiert und dann bei Backpropagation unter Verwendung von Gradientenabstieg aktualisiert.
Lesen Sie: TensorFlow-Objekterkennungs-Tutorial für Anfänger
Zusammenlegen
Die Pooling-Schicht wird zwischen Faltungsschichten platziert. Es ist für die Durchführung von Pooling-Operationen an den von einer Faltungsschicht gesendeten Feature-Maps verantwortlich. Der Pooling-Vorgang reduziert die räumliche Größe der Features, was auch als Dimensionsreduktion bezeichnet wird.
Einer der Hauptgründe für das Pooling besteht darin, die erforderliche Rechenleistung zur Verarbeitung der Daten zu verringern. Obwohl eine Pooling-Schicht die Größe der Bilder reduziert, behält sie ihre wichtigen Eigenschaften bei. Die Funktionsweise ähnelt einem CNN-Filter. Der Kernel geht die Features durch und aggregiert die vom Filter abgedeckten Werte.
Aus dem Bild ist deutlich ersichtlich, dass es verschiedene Aggregationsfunktionen geben kann. Durchschnittliches und maximales Pooling sind die am häufigsten verwendeten Pooling-Operationen. Pooling reduziert die Dimensionen der Features, behält aber die Eigenschaften bei.
Durch die Reduzierung der Parameteranzahl reduzieren sich auch die Berechnungen im Netz. Dies reduziert Überlernen und erhöht die Effizienz des Netzwerks. Der Max-Pool wird meistens verwendet, da Max-Werte in der gepoolten Karte im Vergleich zu den Karten aus der Faltung weniger genau erkannt werden.
Das ist für viele Fälle gut. Sagen wir, wenn man einen Hund erkennen will, müssen seine Ohren nicht so genau wie möglich lokalisiert werden, es reicht zu wissen, dass sie sich fast neben dem Kopf befinden.
Max Pooling wirkt auch als Rauschunterdrücker. Es verwirft die verrauschten Aktivierungen insgesamt und führt auch eine Entrauschung zusammen mit einer Dimensionsreduktion durch. Auf der anderen Seite führt Average Pooling einfach eine Dimensionsreduktion als Rauschunterdrückungsmechanismus durch. Daher können wir sagen, dass Max Pooling viel besser abschneidet als Average Pooling.
Aktivierungsfunktion
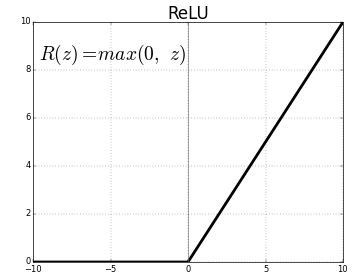
ReLU (Rectified Linear Units) ist die am häufigsten verwendete Aktivierungsfunktionsschicht.
Gleichung dafür ist: ReLU(x)=max(0,x)
Und die grafische Darstellung ist unten angegeben:
Quelle: Medium
ReLU-Vertretung
ReLU bildet die negativen Werte auf null ab und behält die positiven unverändert bei.
Vollständig verbundene Schicht
Eine vollständig verbundene Schicht ist normalerweise die letzte Schicht eines neuronalen Netzwerks. Diese Schicht empfängt Eingabevektoren und erzeugt eine neue Ausgabeschicht. Diese Ausgabeschicht hat n Neuronen, wobei n die Anzahl der Klassen in der Klassifizierung des Bildes ist. Jedes Element des Vektors liefert die Wahrscheinlichkeit, dass das Bild einer bestimmten Klasse angehört. Daher ist die Summe aller Vektoren in der Ausgabeschicht immer 1.

Die Berechnungen in der Ausgabeschicht sind wie folgt:
- Element multipliziert mit dem Gewicht des Neurons
- Aktivierungsfunktion auf die Schicht anwenden (Logistik bei n=2, Sigmoid bei n>2)
Die Ausgabe ist nun die Wahrscheinlichkeit, dass das Bild zu einer bestimmten Klasse gehört. Die Gewichte der Schicht werden während des Trainings durch Backpropagation des Gradienten gelernt.
Lesen Sie auch: Einführung in das neuronale Netzwerkmodell
Dropout-Schicht
Dropout-Schichten fungieren als Regularisierungsschicht, die eine Überanpassung reduziert und Generalisierungsfehler verbessert. Overfitting ist ein großes Problem bei der Verwendung eines neuronalen Netzwerks. Dropout lässt, wie der Name schon sagt, einen gewissen Prozentsatz des Neurons in den Schichten aus, nach denen es verwendet wird.
Das von Dropout verwendete Regularisierungsverfahren besteht darin, dass es das Training einer großen Anzahl von neuronalen Netzen mit unterschiedlichen parallelen Architekturen annähert. Während des Trainingszeitraums werden einige der Layer-Ausgaben nach dem Zufallsprinzip gelöscht oder ignoriert. Dadurch sieht die Schicht wie eine Schicht mit einer unterschiedlichen Anzahl von Knoten aus, und einige Neuronen sind ausgeschaltet. Daher ändert sich auch die Konnektivität entsprechend der vorherigen Schicht.
Hyperparameter
Es gibt bestimmte Parameter, die entsprechend den verarbeiteten Bilddaten gesteuert werden können. Jede Schicht eines CNN kann parametrisiert werden, sei es Convolution Layer oder Pooling Layer. Parameter wirken sich auf die Größe der Feature-Map aus, die die Ausgabe für diesen bestimmten Layer darstellt.
Jedes Bild (Eingabe) oder Merkmalskarte (nachfolgende Ausgaben von Schichten) hat folgende Abmessungen: B x H x T, wobei B x H Breite x Höhe ist, dh die Größe der Karte oder des Bildes. D repräsentiert die Dimension auf der Basis von Farbsegmenten. Monochrome Bilder haben D=1 und RGB, dh farbige Bilder haben D=3.
Hyperparameter der Faltungsschicht
- Anzahl Filter (K)
- Größe des Filters (F) der Abmessung FxFxD
- Strides: Anzahl der Schritte, die der Kernel benötigt, um sich über das Bild zu bewegen. S = 1 bedeutet, dass sich der Kernel mit 1 Pixel als Schritt bewegt.
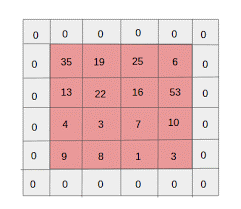
- Zero Padding: Zero Padding wird für Bilder mit geringerer Größe durchgeführt, da Convolution und Max Pool Layers die Größe der Feature-Map bei jeder Iteration reduzieren.
Quelle: XRDS
Das Auffüllen mit Nullen hat die Größe des Eingabebilds erhöht
Für jedes Eingabebild der Größe B×H×T gibt die Pooling-Schicht eine Matrix der Abmessungen Wc×Hc×Dc zurück. Woher
Wc= (W-F+2P)/S+1
Hc = (H-F+2P)/S+1
DC = K
Lösen der Gleichungen, um den Wert von Padding(P)=F-1/2 und Stride(S)=1 zu finden
Im Allgemeinen wählen wir dann F=3,P=1,S=1 oder F=5,P=2,S=1
Pooling-Layer-Hyperparameter
- Zellengröße (F): Die quadratische Zellengröße, in die die Karte für das Pooling aufgeteilt wird. FxF
- Schrittgröße (S): Zellen werden durch S Pixel getrennt
Für jedes Eingabebild der Größe B×H×T gibt die Pooling-Schicht eine Matrix der Abmessungen Wp×Hp×Dp zurück, wobei gilt:
Wp= (WF)/S+1
Hp= (HF)/S+1
Dp = D
Für die Pooling-Schicht wird häufig F = 2 und S = 2 gewählt. 75 % der Eingabepixel werden eliminiert. Man kann auch F=3 und S=2 wählen. Eine größere Zellengröße führt zu einem großen Informationsverlust und ist daher nur für sehr große Eingabebilder geeignet.
Allgemeine Hyperparameter
- Lernrate: Optimierer wie SGD, AdaGrad oder RMSProp können ausgewählt werden, um die Lernrate zu optimieren.
- Epochen: Die Anzahl der Epochen sollte erhöht werden, bis eine Lücke im Training und ein Validierungsfehler auftaucht
- Stapelgröße: 16 bis 128 wählbar. Hängt von der Menge an Rechenleistung ab, die man hat.
- Aktivierungsfunktion: Fügt Nichtlinearität in das Modell ein. ReLu wird typischerweise für Conv Nets verwendet. Andere Optionen sind: Sigmoid, Tanh.
- Dropout: Ein Dropout-Wert von 0,1 lässt 10 % der Neuronen fallen. 0,5 ist ein guter Ausgangspunkt. 0,25 ist eine gute endgültige Option.
- Gewichtungsinitialisierung: Kleine zufällige Gewichtungen können initialisiert werden, um die Möglichkeit von toten Neuronen abzulenken. Aber nicht zu klein für Steigungsabfahrten. Eine gleichmäßige Verteilung ist geeignet.
- Verdeckte Schichten: Verdeckte Schichten können erhöht werden, bis der Testfehler abnimmt. Die Erhöhung der verborgenen Schichten erhöht die Berechnung und erfordert eine Regularisierung.
Fazit
Wir haben die grundlegenden Informationen, um ein CNN von Grund auf neu zu erstellen. Obwohl es sich um einen umfassenden Artikel handelt, der alles auf einer grundlegenden Ebene abdeckt, kann jeder Parameter oder jede Ebene tiefer eingetaucht werden. Die Mathematik hinter jedem Konzept ist auch etwas, das zur Verbesserung des Modells verstanden werden kann
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.