
สถาปัตยกรรมโครงข่ายประสาทเทียม: สิ่งที่คุณต้องรู้?
เผยแพร่แล้ว: 2020-12-01Convolutional Neural Networks มักจะเรียกโดยใช้ชื่อเช่น ConvNets หรือ CNN เป็นหนึ่งในสถาปัตยกรรมเครือข่าย Neural ที่ใช้กันมากที่สุด โดยทั่วไปแล้ว CNN จะใช้สำหรับข้อมูลตามรูปภาพ การจดจำรูปภาพ การจัดประเภทรูปภาพ การตรวจจับวัตถุ ฯลฯ เป็นพื้นที่บางส่วนที่มีการใช้ CNN อย่างแพร่หลาย
สาขาของ Applied AI โดยเฉพาะเหนือข้อมูลภาพเรียกว่า Computer Vision Computer Vision เติบโตขึ้นอย่างมากนับตั้งแต่มีการนำ CNN เข้ามา ส่วนแรกของ CNN จะแยกคุณลักษณะจากรูปภาพโดยใช้ฟังก์ชันการบิดและเปิดใช้งานสำหรับการทำให้เป็นมาตรฐาน
บล็อกสุดท้ายใช้คุณลักษณะเหล่านี้ร่วมกับ Neural Network เพื่อแก้ปัญหาเฉพาะใดๆ ตัวอย่างเช่น ปัญหาการจำแนกประเภทจะมีจำนวนเซลล์ประสาทเอาต์พุต 'n' ขึ้นอยู่กับจำนวนคลาสที่มีอยู่สำหรับการจำแนกประเภท ให้เราพยายามทำความเข้าใจสถาปัตยกรรมและการทำงานของ CNN
สารบัญ
Convolution
Convolution เป็นเทคนิคการประมวลผลรูปภาพที่ใช้เคอร์เนลแบบถ่วงน้ำหนัก (เมทริกซ์สี่เหลี่ยมจัตุรัส) เพื่อหมุนรอบรูปภาพ คูณและเพิ่มองค์ประกอบเคอร์เนลด้วยพิกเซลของรูปภาพ วิธีนี้สามารถมองเห็นได้ง่ายด้วยภาพที่แสดงด้านล่าง
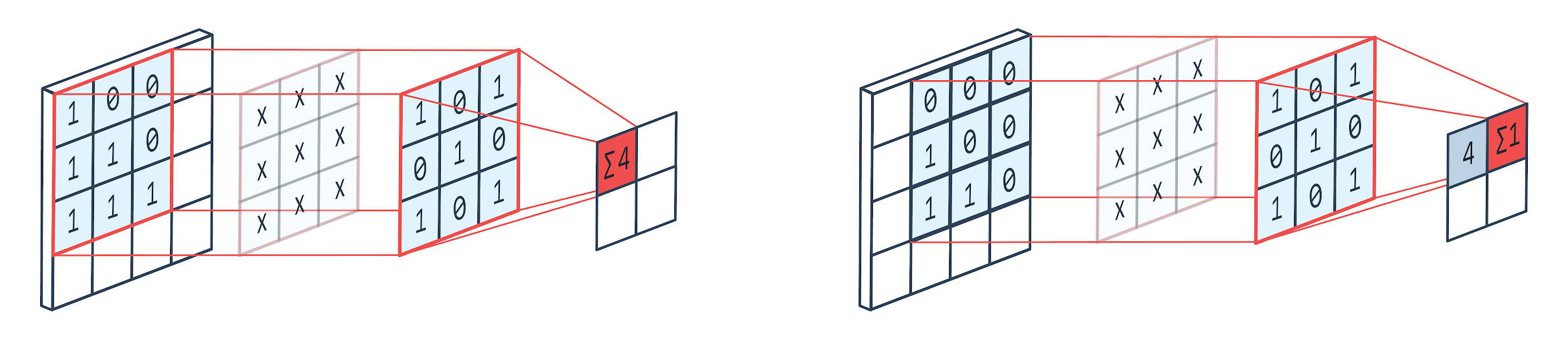
ภาพโดย: Peltarion
ตัวกรองคอนโวลูชั่นและเอาต์พุต

ดังที่เราเห็นได้เมื่อเราใช้คอนโวลูชั่นเค็นเนล 3×3 ส่วน 3×3 ของรูปภาพทำงานบนและหลังจากการคูณและการบวกที่ตามมา ค่าหนึ่งจะเป็นผลลัพธ์ ดังนั้นบนอิมเมจ 4×4 เราจะได้ผลลัพธ์เมทริกซ์ที่ซับซ้อน 2×2 เนื่องจากขนาดเคอร์เนลคือ 3×3
ผลลัพธ์ที่สลับซับซ้อนอาจแตกต่างกันไปตามขนาดของเคอร์เนลที่ใช้สำหรับการบิด นี่คือเลเยอร์เริ่มต้นทั่วไปของ CNN เอาต์พุตที่ซับซ้อนคือคุณลักษณะที่พบในรูปภาพ สิ่งนี้เกี่ยวข้องโดยตรงกับขนาดเคอร์เนลที่ใช้
หากลักษณะของรูปภาพนั้นมีความแตกต่างเพียงเล็กน้อยในรูปภาพจะทำให้รูปภาพอยู่ในหมวดหมู่เอาต์พุตที่ต่างกัน ก็จะใช้ขนาดเคอร์เนลที่เล็กสำหรับการแยกคุณลักษณะ มิฉะนั้นจะสามารถใช้เคอร์เนลที่ใหญ่กว่าได้ ค่าที่ใช้ในเคอร์เนลมักเรียกว่าน้ำหนักแบบคอนโวลูชัน สิ่งเหล่านี้เริ่มต้นและอัปเดตเมื่อ backpropagation โดยใช้การไล่ระดับสี
อ่าน: บทแนะนำการตรวจจับวัตถุ TensorFlow สำหรับผู้เริ่มต้น
การรวมกลุ่ม
เลเยอร์การรวมเข้าด้วยกันถูกวางไว้ระหว่างเลเยอร์การบิด มีหน้าที่รับผิดชอบในการดำเนินการรวมกลุ่มบนแผนที่คุณลักษณะที่ส่งโดยเลเยอร์การบิด การดำเนินการรวมกลุ่มจะลดขนาดเชิงพื้นที่ของจุดสนใจหรือที่เรียกว่าการลดมิติ
เหตุผลหลักประการหนึ่งในการรวมกลุ่มคือการลดกำลังในการประมวลผลที่จำเป็นในการประมวลผลข้อมูล แม้ว่าเลเยอร์การรวมจะลดขนาดของภาพที่รักษาคุณลักษณะที่สำคัญไว้ การทำงานคล้ายกับตัวกรองซีเอ็นเอ็น เคอร์เนลครอบคลุมคุณลักษณะต่างๆ และรวมค่าที่ครอบคลุมโดยตัวกรอง
จากภาพจะเห็นได้ชัดว่ามีฟังก์ชั่นการรวมต่างๆ การรวมเฉลี่ยและสูงสุดเป็นการดำเนินการรวมกลุ่มที่ใช้บ่อยที่สุด การรวมลดขนาดของคุณลักษณะแต่ยังคงคุณลักษณะเหมือนเดิม
ด้วยการลดจำนวนพารามิเตอร์ การคำนวณในเครือข่ายก็ลดลงด้วย ซึ่งจะช่วยลดการเรียนรู้มากเกินไปและเพิ่มประสิทธิภาพของเครือข่าย ส่วนใหญ่ใช้กลุ่มสูงสุดเนื่องจากค่าสูงสุดถูกตรวจพบในแผนที่รวมน้อยกว่าเมื่อเปรียบเทียบกับแผนที่จากการบิด
ซึ่งเป็นสิ่งที่ดีสำหรับหลายๆ กรณี สมมติว่าเราอยากรู้จักสุนัข ไม่จำเป็นต้องระบุตำแหน่งหูให้แม่นยำที่สุดเท่าที่จะเป็นไปได้ โดยรู้ว่าพวกมันอยู่ใกล้ๆ กับศีรษะก็เพียงพอแล้ว
Max Pooling ยังทำหน้าที่เป็นตัวป้องกันเสียงรบกวน มันละทิ้งการเปิดใช้งานที่มีเสียงดังทั้งหมดและยังทำการขจัดเสียงรบกวนพร้อมกับการลดขนาด ในทางกลับกัน Average Pooling จะทำการลดขนาดเป็นกลไกลดสัญญาณรบกวน ดังนั้น เราสามารถพูดได้ว่า Max Pooling ทำได้ดีกว่า Average Pooling มาก
ฟังก์ชั่นการเปิดใช้งาน
ReLU (Rectified Linear Units) เป็นเลเยอร์ฟังก์ชันการเปิดใช้งานที่ใช้บ่อยที่สุด
สมการเดียวกันคือ: ReLU(x)=max(0,x)
และการแสดงกราฟิกได้รับด้านล่าง:
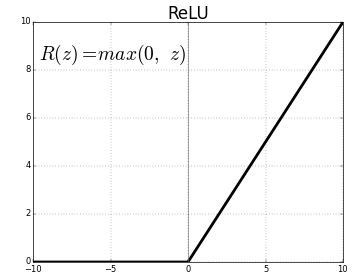
ที่มา: สื่อ
ตัวแทน ReLU
ReLU จับคู่ค่าลบเป็นศูนย์และเก็บค่าบวกไว้เหมือนเดิม
เชื่อมต่ออย่างสมบูรณ์ Layer
เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์มักจะเป็นเลเยอร์สุดท้ายของโครงข่ายประสาทเทียม เลเยอร์นี้รับเวกเตอร์อินพุตและสร้างเลเยอร์เอาต์พุตใหม่ เลเยอร์เอาต์พุตนี้มีจำนวนเซลล์ประสาท n จำนวน โดยที่ n คือจำนวนคลาสในการจำแนกประเภทของภาพ องค์ประกอบของเวกเตอร์แต่ละอย่างให้ความน่าจะเป็นของรูปภาพที่เป็นของคลาสใดคลาสหนึ่ง ดังนั้นผลรวมของเวกเตอร์ทั้งหมดในเลเยอร์เอาต์พุตจะเป็น 1 เสมอ

การคำนวณที่เกิดขึ้นในชั้นผลลัพธ์มีดังนี้:
- องค์ประกอบคูณด้วยน้ำหนักของเซลล์ประสาท
- ใช้ฟังก์ชันการเปิดใช้งานบนเลเยอร์ (โลจิสติกเมื่อ n=2, sigmoid เมื่อ n>2)
ผลลัพธ์จะเป็นความน่าจะเป็นของรูปภาพที่เป็นของคลาสใดคลาสหนึ่ง น้ำหนักของเลเยอร์จะเรียนรู้ระหว่างการฝึกโดย backpropagation ของการไล่ระดับสี
อ่านเพิ่มเติม: บทนำโมเดลโครงข่ายประสาทเทียม
Dropout Layer
เลเยอร์ Dropout ทำงานเป็นเลเยอร์การทำให้เป็นมาตรฐานซึ่งช่วยลดการจัดวางมากเกินไปและปรับปรุงข้อผิดพลาดทั่วไป Overfitting เป็นข้อกังวลหลักในขณะที่ใช้โครงข่ายประสาทเทียม การออกกลางคันตามชื่อจะดร็อปเซลล์ประสาทบางส่วนในเลเยอร์หลังจากนั้นจะใช้
วิธีการทำให้เป็นมาตรฐานที่ใช้โดยการออกกลางคันคือการประมาณการฝึกอบรมเครือข่ายประสาทเทียมจำนวนมากที่มีสถาปัตยกรรมคู่ขนานที่แตกต่างกัน ในช่วงระยะเวลาการฝึกอบรม ผลลัพธ์ของเลเยอร์บางส่วนจะถูกสุ่มทิ้งหรือถูกละเว้น สิ่งนี้ทำให้เลเยอร์ดูเหมือนเป็นเลเยอร์ที่มีจำนวนโหนดต่างกันและเซลล์ประสาทบางเซลล์ปิดอยู่ ดังนั้นการเชื่อมต่อจึงเปลี่ยนไปตามชั้นก่อนหน้า
ไฮเปอร์พารามิเตอร์
มีพารามิเตอร์บางอย่างที่สามารถควบคุมได้ตามข้อมูลภาพที่ได้รับการจัดการ แต่ละชั้นของ CNN สามารถกำหนดพารามิเตอร์ได้ ไม่ว่าจะเป็นชั้น Convolution หรือ Pooling Layer พารามิเตอร์ส่งผลต่อขนาดของแผนผังคุณลักษณะที่เป็นเอาต์พุตสำหรับเลเยอร์เฉพาะนั้น
รูปภาพแต่ละภาพ (อินพุต) หรือแผนที่คุณลักษณะ (ผลลัพธ์ที่ตามมาของเลเยอร์) มีขนาด: กว้าง x สูง x ลึก โดยที่ กว้าง x สูง คือ กว้าง x สูง กล่าวคือ ขนาดของแผนที่หรือรูปภาพ D แสดงถึงมิติบนพื้นฐานของกลุ่มสี ภาพขาวดำจะมี D=1 และ RGB เช่น ภาพสีจะมี D=3
พารามิเตอร์ไฮเปอร์พารามิเตอร์ของ Convolution Layer
- จำนวนตัวกรอง (K)
- ขนาดของตัวกรอง (F) ของมิติ FxFxD
- Strides: จำนวนขั้นตอนที่ดำเนินการเพื่อให้เคอร์เนลเลื่อนเหนือรูปภาพ S=1 หมายความว่าเคอร์เนลจะเคลื่อนที่ด้วย 1 พิกเซลเป็นขั้นตอน
- Zero padding: Zero padding เสร็จสิ้นสำหรับรูปภาพที่มีขนาดน้อยกว่า เนื่องจาก Convolution และ Max Pool Layers จะลดขนาดของแมปคุณลักษณะในการทำซ้ำทุกครั้ง
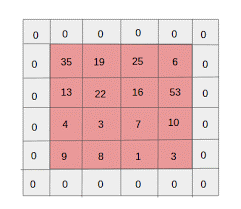
ที่มา: XRDS
Zero padding เพิ่มขนาดของภาพอินพุต
สำหรับแต่ละรูปภาพอินพุตที่มีขนาด W×H×D เลเยอร์การรวมจะส่งกลับเมทริกซ์ของมิติ Wc×Hc×Dc ที่ไหน
Wc= (W-F+2P)/S+1
Hc= (H-F+2P)/S+1
Dc= K
การแก้สมการเพื่อหาค่าของ Padding(P)=F-1 / 2 and Stride(S)=1
โดยทั่วไปแล้วเราเลือก F=3,P=1,S=1 หรือ F=5,P=2,S=1
การรวมไฮเปอร์พารามิเตอร์ของเลเยอร์
- ขนาดเซลล์ (F): ขนาดเซลล์สี่เหลี่ยมที่จะแบ่งแผนที่เพื่อรวมเข้าด้วยกัน FxF
- ขนาดขั้นตอน (S): เซลล์ถูกคั่นด้วย S พิกเซล
สำหรับแต่ละรูปภาพอินพุตที่มีขนาด W × H × D เลเยอร์การรวมส่งคืนเมทริกซ์ของขนาด Wp × Hp × Dp โดยที่
Wp= (WF)/S+1
แรงม้า= (HF)/S+1
Dp= D
สำหรับเลเยอร์การรวม F=2 และ S=2 ถูกเลือกอย่างกว้างขวาง 75% ของพิกเซลอินพุตถูกกำจัด สามารถเลือก F=3 และ S=2 ได้ ขนาดเซลล์ที่ใหญ่ขึ้นจะส่งผลให้สูญเสียข้อมูลจำนวนมาก จึงเหมาะสำหรับภาพที่ป้อนขนาดใหญ่มากเท่านั้น
ไฮเปอร์พารามิเตอร์ทั่วไป
- อัตราการเรียนรู้: สามารถเลือกเครื่องมือเพิ่มประสิทธิภาพ เช่น SGD, AdaGrad หรือ RMSProp เพื่อปรับอัตราการเรียนรู้ให้เหมาะสม
- ยุค: จำนวนยุคควรเพิ่มขึ้นจนกว่าช่องว่างในการฝึกอบรมและข้อผิดพลาดในการตรวจสอบจะปรากฏขึ้น
- ขนาดแบทช์: 16 ถึง 128 สามารถเลือกได้ ขึ้นอยู่กับจำนวนพลังการประมวลผลที่มี
- ฟังก์ชันการเปิดใช้งาน: แนะนำความไม่เป็นเชิงเส้นให้กับโมเดล โดยทั่วไปจะใช้ ReLu สำหรับ Conv Nets ตัวเลือกอื่นๆ ได้แก่ ซิกมอยด์ แทนห์
- Dropout: ค่า dropout ที่ 0.1 ลดลง 10% ของเซลล์ประสาท 0.5 เป็นจุดเริ่มต้นที่ดี 0.25 เป็นตัวเลือกสุดท้ายที่ดี
- การเริ่มต้นน้ำหนัก: สามารถกำหนดค่าน้ำหนักสุ่มขนาดเล็กเพื่อเบี่ยงเบนความเป็นไปได้ของเซลล์ประสาทที่ตายแล้ว แต่ไม่เล็กเกินไปสำหรับการไล่ระดับแบบไล่ระดับ การกระจายแบบสม่ำเสมอเหมาะ
- เลเยอร์ที่ซ่อนอยู่: สามารถเพิ่มเลเยอร์ที่ซ่อนอยู่ได้จนกว่าข้อผิดพลาดในการทดสอบจะลดลง การเพิ่มเลเยอร์ที่ซ่อนอยู่จะเพิ่มการคำนวณและต้องมีการปรับให้เป็นมาตรฐาน
บทสรุป
เรามีข้อมูลพื้นฐานในการสร้าง CNN ตั้งแต่เริ่มต้น แม้ว่าจะเป็นบทความที่ครอบคลุมทุกอย่างในระดับพื้นฐาน แต่พารามิเตอร์หรือเลเยอร์แต่ละรายการสามารถเจาะลึกลงไปได้ คณิตศาสตร์ที่อยู่เบื้องหลังทุกแนวคิดยังเป็นสิ่งที่สามารถเข้าใจได้เพื่อการพัฒนาแบบจำลองให้ดีขึ้น
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT- สถานะศิษย์เก่า B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ