
Architecture de réseau neuronal convolutif : ce que vous devez savoir ?
Publié: 2020-12-01Les réseaux de neurones convolutifs généralement appelés par des noms tels que ConvNets ou CNN sont l'une des architectures de réseau de neurones les plus couramment utilisées. Les CNN sont généralement utilisés pour les données basées sur des images. La reconnaissance d'images, la classification d'images, la détection d'objets, etc., sont quelques-uns des domaines où les CNN sont largement utilisés.
La branche de l'IA appliquée spécifiquement sur les données d'image est appelée vision par ordinateur. Il y a eu une croissance monumentale de la vision par ordinateur depuis l'introduction des CNN. La première partie de CNN extrait les caractéristiques des images en utilisant la fonction de convolution et d'activation pour la normalisation.
Le dernier bloc utilise ces fonctionnalités avec Neural Network pour résoudre tout problème spécifique, par exemple un problème de classification aura un nombre «n» de neurones de sortie en fonction du nombre de classes présentes pour la classification. Essayons de comprendre l'architecture et le fonctionnement d'un CNN.
Table des matières
Convolution
La convolution est une technique de traitement d'image qui utilise un noyau pondéré (matrice carrée) pour tourner sur l'image, multiplier et additionner les éléments du noyau avec les pixels de l'image. Cette méthode peut être facilement visualisée par l'image ci-dessous.
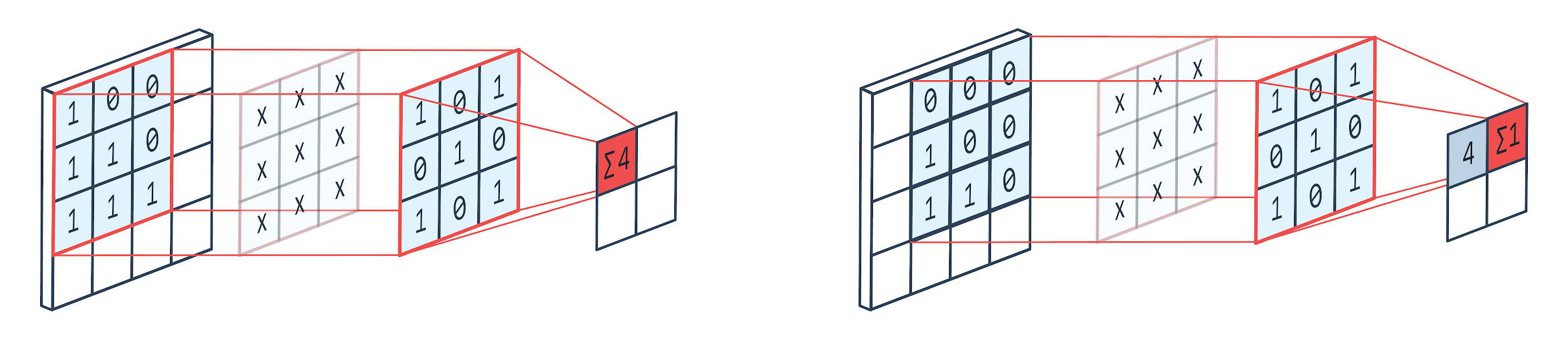
Image par: Peltarion
Filtre de convolution et sortie

Comme nous pouvons le voir lorsque nous utilisons un chenil de convolution 3 × 3, une partie 3 × 3 de l'image est exploitée et après multiplication et addition ultérieure, une valeur apparaît en sortie. Ainsi, sur une image 4 × 4, nous obtiendrons une sortie de matrice alambiquée 2 × 2 étant donné que la taille du noyau est de 3 × 3.
La sortie alambiquée peut varier en fonction de la taille du noyau utilisé pour la convolution. Il s'agit de la couche de départ typique d'un CNN. La sortie alambiquée est les caractéristiques trouvées à partir de l'image. Ceci est directement lié à la taille du noyau utilisé.
Si la caractéristique d'une image est telle que même de petites différences dans une image la feront tomber dans une catégorie de sortie différente, une petite taille de noyau est utilisée pour l'extraction des caractéristiques. Sinon, un noyau plus gros peut être utilisé. Les valeurs utilisées dans le noyau sont souvent appelées poids de convolution. Ceux-ci sont initialisés puis mis à jour lors de la rétropropagation à l'aide de la descente de gradient.
Lire : Tutoriel de détection d'objets TensorFlow pour les débutants
mise en commun
La couche de regroupement est placée entre les couches de convolution. Il est chargé d'effectuer des opérations de regroupement sur les cartes d'entités envoyées par une couche de convolution. L'opération de mise en commun réduit la taille spatiale des entités, également connue sous le nom de réduction de dimensionnalité.
L'une des principales raisons de la mise en commun est de réduire la puissance de calcul requise pour traiter les données. Bien qu'une couche de regroupement réduise la taille des images, elle préserve leurs caractéristiques importantes. Le fonctionnement est similaire à un filtre CNN. Le noyau passe en revue les fonctionnalités et agrège les valeurs couvertes par le filtre.
À partir de l'image, il est clairement visible qu'il peut y avoir diverses fonctions d'agrégation. La mise en commun moyenne et maximale sont les opérations de mise en commun les plus couramment utilisées. La mise en commun réduit les dimensions des fonctionnalités mais conserve les caractéristiques intactes.
En réduisant le nombre de paramètres, les calculs diminuent également dans le réseau. Cela réduit le surapprentissage et augmente l'efficacité du réseau. Le max-pool est principalement utilisé car les valeurs maximales sont repérées avec moins de précision dans la carte regroupée par rapport aux cartes de convolution.
C'est bon pour beaucoup de cas. Disons que si l'on veut reconnaître un chien, ses oreilles n'ont pas besoin d'être localisées le plus précisément possible, sachant qu'elles sont situées presque à côté de la tête suffit.
Max Pooling fonctionne également comme un suppresseur de bruit. Il supprime complètement les activations bruyantes et effectue également un débruitage ainsi qu'une réduction de la dimensionnalité. D'autre part, Average Pooling effectue simplement une réduction de la dimensionnalité en tant que mécanisme de suppression du bruit. Par conséquent, nous pouvons dire que Max Pooling est beaucoup plus performant que Average Pooling.
Fonction d'activation
ReLU (unités linéaires rectifiées) est la couche de fonction d'activation la plus couramment utilisée.
L'équation pour la même chose est : ReLU(x)=max(0,x)
Et la représentation graphique est donnée ci-dessous :
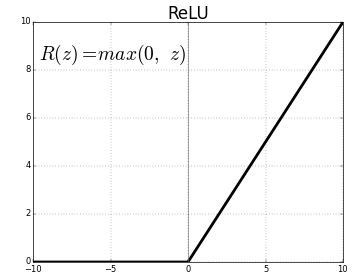
Source : Médium
Représentation ReLU
ReLU mappe les valeurs négatives sur zéro et conserve les valeurs positives telles quelles.
Couche entièrement connectée
Une couche entièrement connectée est généralement la dernière couche de tout réseau de neurones. Cette couche reçoit des vecteurs d'entrée et produit une nouvelle couche de sortie. Cette couche de sortie comporte n nombre de neurones où n est le nombre de classes dans la classification de l'image. Chaque élément du vecteur fournit la probabilité que l'image appartienne à une certaine classe. Par conséquent, la somme de tous les vecteurs de la couche de sortie est toujours 1.

Les calculs effectués dans la couche de sortie sont les suivants :
- Elément multiplié par le poids du neurone
- Appliquer la fonction d'activation sur la couche (logistique quand n=2, sigmoïde quand n>2)
La sortie sera maintenant la probabilité que l'image appartienne à une certaine classe. Les poids de la couche sont appris lors de l'apprentissage par rétropropagation du gradient.
Lisez également : Introduction au modèle de réseau neuronal
Couche de suppression
Les couches de suppression fonctionnent comme une couche de régularisation qui réduit le surajustement et améliore l'erreur de généralisation. Le surajustement est une préoccupation majeure lors de l'utilisation d'un réseau de neurones. L'abandon, comme son nom l'indique, supprime un certain pourcentage de neurones dans les couches après lesquelles il est utilisé.
La méthode de régularisation employée par le décrochage est qu'elle se rapproche de la formation d'un grand nombre de réseaux de neurones avec différentes architectures parallèles. Pendant la période d'apprentissage, certaines des sorties de couche sont abandonnées ou ignorées de manière aléatoire. Cela fait ressembler la couche à une couche avec différents nombres de nœuds et certains neurones sont désactivés. Par conséquent, la connectivité change également en fonction de la couche précédente.
Hyperparamètres
Certains paramètres peuvent être contrôlés en fonction des données d'image traitées. Chaque couche d'un CNN peut être paramétrée, qu'il s'agisse d'une couche de convolution ou d'une couche de regroupement. Les paramètres affectent la taille de la carte d'entités qui est la sortie pour cette couche spécifique.
Chaque image (entrée) ou carte d'entités (sorties ultérieures des couches) a les dimensions : L x H x P, où L x H est la largeur x la hauteur, c'est-à-dire la taille de la carte ou de l'image. D représente la dimension sur la base des segments de couleur. Les images monochromes auront D=1 et RVB, c'est-à-dire que les images colorées auront D=3.
Hyperparamètres de la couche de convolution
- Nombre de filtres (K)
- Taille du filtre (F) de la dimension FxFxD
- Strides : nombre de pas effectués par le noyau pour se déplacer sur l'image. S=1 signifie que le noyau se déplacera avec 1 pixel comme pas.
- Rembourrage zéro : le rembourrage zéro est effectué pour les images ayant une taille inférieure, car les couches de convolution et de pool max réduisent la taille de la carte des fonctionnalités à chaque itération.
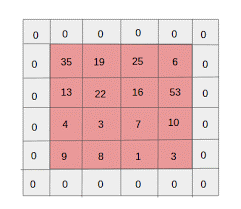
Source : XRDS
Le remplissage zéro a augmenté la taille de l'image d'entrée
Pour chaque image d'entrée de taille LxHxD, la couche de mutualisation renvoie une matrice de dimensions WcxHcxDc. Où
Wc= (L-V+2P)/S+1
Hc= (H-F+2P)/S+1
Dc=K
Résoudre les équations pour trouver la valeur de Padding(P)=F-1/2 et Stride(S)=1
En général, on choisit alors F=3,P=1,S=1 ou F=5,P=2,S=1
Regrouper les hyperparamètres de la couche
- Taille de cellule (F) : taille de cellule carrée dans laquelle la carte sera divisée pour le regroupement. FxF
- Taille de pas (S) : les cellules sont séparées par S pixels
Pour chaque image d'entrée de taille W×H×D, la couche de regroupement renvoie une matrice de dimensions Wp×Hp×Dp, où
Wp= (WF)/S+1
Hp= (HF)/S+1
Dp=D
Pour la couche de regroupement, F=2 et S=2 sont largement choisis. 75% des pixels d'entrée sont éliminés. On peut aussi choisir F=3 et S=2. Une taille de cellule plus grande entraînera une perte importante d'informations, et ne convient donc qu'aux images d'entrée de très grande taille.
Hyperparamètres généraux
- Taux d'apprentissage : des optimiseurs tels que SGD, AdaGrad ou RMSProp peuvent être choisis pour optimiser le taux d'apprentissage.
- Époques : le nombre d'époques doit être augmenté jusqu'à ce qu'un écart dans la formation et une erreur de validation apparaissent
- Taille du lot : 16 à 128 peuvent être sélectionnés. Dépend de la quantité de puissance de traitement dont on dispose.
- Fonction d'activation : introduit une non-linéarité dans le modèle. ReLu est généralement utilisé pour les Conv Nets. Les autres options sont : sigmoïde, tanh.
- Décrochage : une valeur de décrochage de 0,1 fait chuter 10 % des neurones. 0,5 est un bon point de départ. 0,25 est une bonne option finale.
- Initialisation de poids : de petits poids aléatoires peuvent être initialisés pour dévier la possibilité de neurones morts. Mais pas trop petit pour une descente en dégradé. Une distribution uniforme convient.
- Couches masquées : les couches masquées peuvent être augmentées jusqu'à ce que l'erreur de test diminue. L'augmentation des couches cachées augmentera le calcul et nécessitera une régularisation.
Conclusion
Nous avons les informations de base pour créer un CNN à partir de zéro. Bien qu'il s'agisse d'un article complet qui couvre tout à un niveau de base, chaque paramètre ou couche peut être approfondi. Les mathématiques derrière chaque concept sont également quelque chose qui peut être compris pour l'amélioration du modèle
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT- Statut B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.