
Arsitektur Jaringan Neural Convolutional: Apa yang Perlu Anda Ketahui?
Diterbitkan: 2020-12-01Convolutional Neural Network yang biasa disebut dengan nama ConvNets atau CNN merupakan salah satu Arsitektur Neural Network yang paling umum digunakan. CNN umumnya digunakan untuk data berbasis gambar. Pengenalan gambar, klasifikasi gambar, deteksi objek, dll., adalah beberapa area di mana CNN banyak digunakan.
Cabang AI Terapan khusus atas data gambar disebut sebagai Computer Vision. Telah ada pertumbuhan monumental dalam Computer Vision sejak diperkenalkannya CNN. Bagian pertama CNN mengekstrak fitur dari gambar menggunakan fungsi konvolusi dan aktivasi untuk normalisasi.
Blok terakhir menggunakan fitur ini dengan Neural Network untuk memecahkan masalah tertentu, misalnya masalah klasifikasi akan memiliki 'n' jumlah neuron keluaran tergantung pada jumlah kelas yang ada untuk klasifikasi. Mari kita coba memahami arsitektur dan cara kerja CNN.
Daftar isi
Lilitan
Konvolusi adalah teknik pemrosesan gambar yang menggunakan kernel berbobot (matriks persegi) untuk berputar di atas gambar, mengalikan dan menambahkan elemen kernel dengan piksel gambar. Metode ini dapat dengan mudah divisualisasikan dengan gambar yang ditunjukkan di bawah ini.
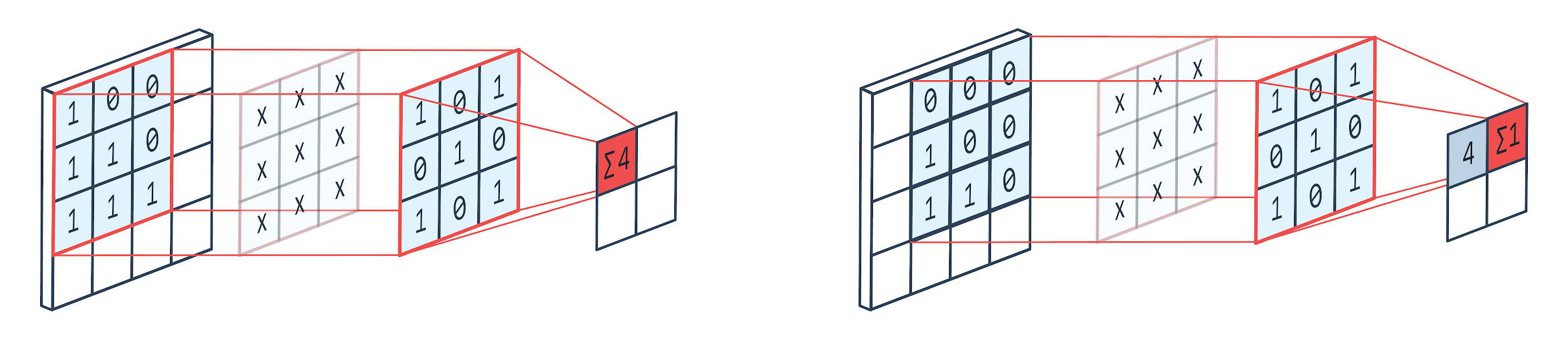
Gambar oleh: Peltarion
Filter dan keluaran konvolusi

Seperti yang dapat kita lihat ketika kita menggunakan kennel konvolusi 3x3, bagian 3x3 dari gambar dioperasikan dan setelah perkalian dan penambahan berikutnya, satu nilai muncul sebagai output. Jadi pada gambar 4x4 kita akan mendapatkan output matriks berbelit-belit 2x2 mengingat ukuran kernel adalah 3x3.
Output yang berbelit-belit dapat bervariasi berdasarkan ukuran kernel yang digunakan untuk konvolusi. Ini adalah lapisan awal khas CNN. Output berbelit-belit adalah fitur yang ditemukan dari gambar. Ini berhubungan langsung dengan ukuran kernel yang digunakan.
Jika karakteristik suatu gambar sedemikian rupa sehingga perbedaan kecil dalam suatu gambar akan membuatnya masuk dalam kategori keluaran yang berbeda, maka ukuran kernel yang kecil digunakan untuk ekstraksi fitur. Jika tidak, kernel yang lebih besar dapat digunakan. Nilai yang digunakan dalam kernel sering disebut sebagai bobot konvolusi. Ini diinisialisasi dan kemudian diperbarui pada backpropagation menggunakan penurunan gradien.
Baca: Tutorial Deteksi Objek TensorFlow Untuk Pemula
kolam renang
Lapisan pooling ditempatkan di antara lapisan konvolusi. Ini bertanggung jawab untuk melakukan operasi penyatuan pada peta fitur yang dikirim oleh lapisan konvolusi. Operasi pooling mengurangi ukuran spasial fitur yang juga dikenal sebagai pengurangan dimensi.
Salah satu alasan utama penyatuan adalah untuk mengurangi daya komputasi yang diperlukan untuk memproses data. Meskipun, lapisan penyatuan mengurangi ukuran gambar yang mempertahankan karakteristik penting mereka. Cara kerjanya mirip dengan filter CNN. Kernel membahas fitur-fitur dan menggabungkan nilai-nilai yang dicakup oleh filter.
Dari gambar terlihat jelas bahwa ada berbagai fungsi agregasi. Pengumpulan rata-rata dan maksimum adalah operasi penyatuan yang paling umum digunakan. Pooling mengurangi dimensi fitur tetapi menjaga karakteristik tetap utuh.
Dengan mengurangi jumlah parameter, perhitungan juga berkurang di jaringan. Ini mengurangi pembelajaran berlebihan dan meningkatkan efisiensi jaringan. Kumpulan maks banyak digunakan karena nilai maks terlihat kurang akurat di peta kumpulan dibandingkan dengan peta dari konvolusi.
Ini bagus untuk banyak kasus. Katakanlah jika seseorang ingin mengenali seekor anjing, telinganya tidak perlu ditempatkan setepat mungkin, mengetahui bahwa mereka terletak hampir di sebelah kepala sudah cukup.
Max Pooling juga berfungsi sebagai Peredam Kebisingan. Ini membuang aktivasi bising sama sekali dan juga melakukan de-noising bersama dengan pengurangan dimensi. Di sisi lain, Average Pooling hanya melakukan pengurangan dimensi sebagai mekanisme peredam bising. Oleh karena itu, kita dapat mengatakan bahwa Max Pooling berkinerja jauh lebih baik daripada Average Pooling.
Fungsi Aktivasi
ReLU (Rectified Linear Units) adalah lapisan fungsi aktivasi yang paling umum digunakan.
Persamaan untuk hal yang sama adalah: ReLU(x)=max(0,x)
Dan representasi grafis diberikan di bawah ini:
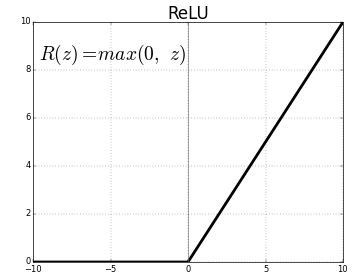
Sumber: Media
ReLU representasi
ReLU memetakan nilai negatif ke nol dan mempertahankan nilai positif apa adanya.
Lapisan Terhubung Sepenuhnya
Lapisan yang terhubung penuh biasanya merupakan lapisan terakhir dari setiap jaringan saraf. Lapisan ini menerima vektor masukan dan menghasilkan lapisan keluaran baru. Lapisan keluaran ini memiliki n jumlah neuron dimana n adalah jumlah kelas dalam klasifikasi citra. Setiap elemen dari vektor memberikan probabilitas gambar menjadi kelas tertentu. Oleh karena itu jumlah semua vektor pada lapisan keluaran selalu 1.

Perhitungan yang terjadi pada output layer adalah sebagai berikut:
- Elemen dikalikan dengan berat neuron
- Terapkan fungsi aktivasi pada layer (logistik saat n=2, sigmoid saat n>2)
Outputnya sekarang akan menjadi probabilitas gambar milik kelas tertentu. Bobot lapisan dipelajari selama pelatihan dengan backpropagation dari gradien.
Baca Juga: Pengenalan Model Neural Network
Lapisan putus sekolah
Lapisan dropout bekerja sebagai lapisan regularisasi yang mengurangi overfitting dan meningkatkan kesalahan generalisasi. Overfitting adalah perhatian utama saat menggunakan Neural Network. Dropout seperti namanya menjatuhkan beberapa persentase neuron di lapisan setelah itu digunakan.
Metode regularisasi yang digunakan oleh dropout adalah bahwa ia mendekati pelatihan sejumlah besar jaringan saraf dengan arsitektur paralel yang berbeda. Selama periode pelatihan, beberapa keluaran lapisan secara acak dijatuhkan atau diabaikan. Ini membuat layer terlihat seperti layer dengan jumlah node yang berbeda dan beberapa neuron dimatikan. Oleh karena itu konektivitas juga berubah sesuai dengan lapisan sebelumnya.
Hyperparameter
Ada parameter tertentu yang dapat dikontrol sesuai dengan data gambar yang ditangani. Setiap lapisan CNN dapat diparameterisasi, baik itu lapisan konvolusi atau lapisan pooling. Parameter mempengaruhi ukuran peta fitur yang merupakan output untuk lapisan tertentu.
Setiap gambar (input) atau peta fitur (output lapisan berikutnya) memiliki dimensi: L x T x D di mana L x H adalah lebar x tinggi yaitu ukuran peta atau gambar. D mewakili dimensi berdasarkan segmen warna. Gambar monokrom akan memiliki D=1 dan RGB yaitu gambar berwarna akan memiliki D=3.
Hyperparameter Lapisan Konvolusi
- Jumlah filter (K)
- Ukuran filter (F) dari dimensi FxFxD
- Strides: Jumlah langkah yang diambil kernel untuk menggeser image. S=1 berarti kernel akan bergerak dengan 1 piksel sebagai langkah.
- Zero padding: zero padding dilakukan untuk gambar yang memiliki ukuran lebih kecil, karena convolution dan max pool layer mengurangi ukuran peta fitur pada setiap iterasi.
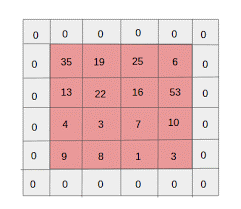
Sumber: XRDS
Nol padding meningkatkan ukuran gambar input
Untuk setiap citra masukan dengan ukuran W×H×D, pooling layer mengembalikan matriks berdimensi Wc×Hc×Dc. Di mana
Wc= (W-F+2P)/S+1
Hc= (H-F+2P)/S+1
Dc = K
Memecahkan persamaan untuk mencari nilai Padding(P)=F-1/2 dan Stride(S)=1
Secara umum, kita kemudian memilih F=3,P=1,S=1 atau F=5,P=2,S=1
Hyperparameter Pooling Layer
- Ukuran sel (F): Ukuran sel persegi di mana peta akan dibagi untuk pengumpulan. FxF
- Ukuran langkah (S): Sel dipisahkan oleh piksel S
Untuk setiap citra masukan berukuran W×H×D, pooling layer mengembalikan matriks berdimensi Wp×Hp×Dp, di mana
Wp= (WF)/S+1
Hp= (HF)/S+1
Dp= D
Untuk pooling layer, F=2 dan S=2 banyak dipilih. 75% dari piksel masukan dihilangkan. Seseorang juga dapat memilih F=3 dan S=2. Ukuran sel yang lebih besar akan mengakibatkan hilangnya informasi yang besar, sehingga hanya cocok untuk gambar masukan berukuran sangat besar.
Hiperparameter umum
- Tingkat pembelajaran: Pengoptimal seperti SGD, AdaGrad atau RMSProp dapat dipilih untuk mengoptimalkan kecepatan pembelajaran.
- Epochs: Jumlah Epochs harus ditingkatkan sampai celah dalam pelatihan dan kesalahan validasi muncul
- Ukuran batch: 16 hingga 128 dapat dipilih. Tergantung pada jumlah kekuatan pemrosesan yang dimiliki seseorang.
- Fungsi Aktivasi: Memperkenalkan non-linearitas ke model. ReLu biasanya digunakan untuk Conv Nets. Pilihan lainnya adalah: sigmoid, tanh.
- Dropout: nilai dropout 0,1 menjatuhkan 10% dari neuron. 0,5 adalah titik awal yang baik. 0,25 adalah pilihan terakhir yang bagus.
- Inisialisasi Bobot: Bobot acak kecil dapat diinisialisasi untuk membelokkan kemungkinan neuron mati. Tapi tidak terlalu kecil untuk gradient descent. Distribusi seragam cocok.
- Lapisan tersembunyi: Lapisan tersembunyi dapat ditingkatkan hingga kesalahan pengujian berkurang. Meningkatkan lapisan tersembunyi akan meningkatkan komputasi dan membutuhkan regularisasi.
Kesimpulan
Kami memiliki informasi dasar untuk membuat CNN dari awal. Meskipun ini adalah artikel komprehensif yang mencakup semuanya pada tingkat dasar, setiap parameter atau lapisan dapat digali lebih dalam. Matematika di balik setiap konsep juga merupakan sesuatu yang dapat dipahami untuk perbaikan model
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.