
Arquitectura de red neuronal convolucional: ¿Qué necesita saber?
Publicado: 2020-12-01Las redes neuronales convolucionales, generalmente denominadas con nombres como ConvNets o CNN, son una de las arquitecturas de redes neuronales más utilizadas. Las CNN se utilizan generalmente para datos basados en imágenes. El reconocimiento de imágenes, la clasificación de imágenes, la detección de objetos, etc., son algunas de las áreas en las que las CNN se utilizan ampliamente.
La rama de la IA aplicada específicamente sobre datos de imágenes se denomina Visión por computadora. Ha habido un crecimiento monumental en Computer Vision desde la introducción de las CNN. La primera parte de CNN extrae características de las imágenes utilizando la convolución y la función de activación para la normalización.
El último bloque utiliza estas características con Neural Network para resolver cualquier problema específico, por ejemplo, un problema de clasificación tendrá 'n' número de neuronas de salida dependiendo del número de clases presentes para la clasificación. Tratemos de entender la arquitectura y el funcionamiento de una CNN.
Tabla de contenido
Circunvolución
La convolución es una técnica de procesamiento de imágenes que utiliza un núcleo ponderado (matriz cuadrada) para girar sobre la imagen, multiplicar y agregar los elementos del núcleo con píxeles de imagen. Este método se puede visualizar fácilmente en la imagen que se muestra a continuación.
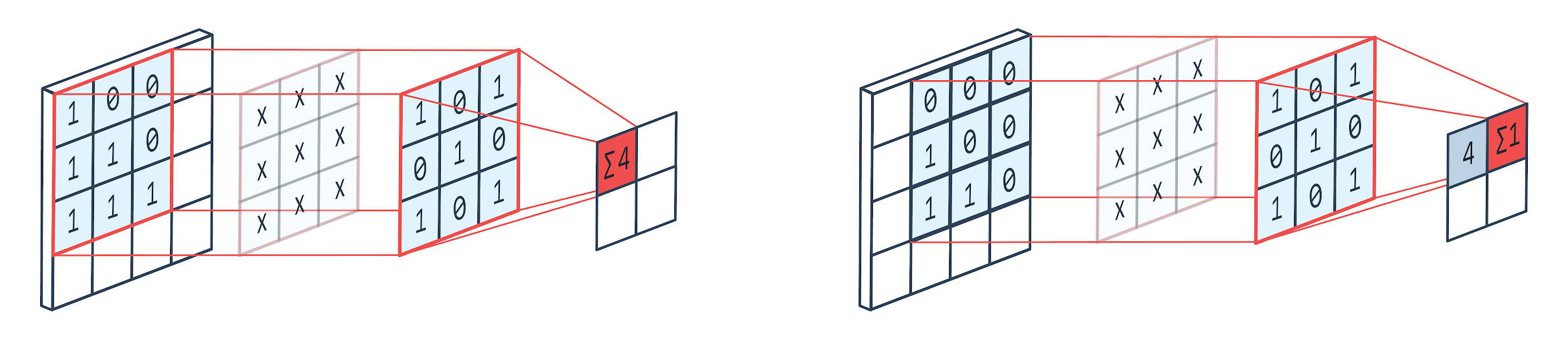
Imagen por: Peltarion
Filtro de convolución y salida

Como podemos ver, cuando usamos una perrera de convolución de 3×3, se opera una parte de la imagen de 3×3 y, después de la multiplicación y la suma posterior, se obtiene un valor como salida. Entonces, en una imagen de 4 × 4 obtendremos una salida de matriz contorneada de 2 × 2 dado que el tamaño del núcleo es 3 × 3.
La salida complicada puede variar según el tamaño del núcleo utilizado para la convolución. Esta es la capa inicial típica de una CNN. La salida complicada son las características que se encuentran en la imagen. Esto está directamente relacionado con el tamaño del núcleo que se utiliza.
Si la característica de una imagen es tal que incluso las pequeñas diferencias en una imagen la harán caer en una categoría de salida diferente, entonces se utiliza un tamaño de núcleo pequeño para la extracción de características. De lo contrario, se puede usar un kernel más grande. Los valores utilizados en el kernel a menudo se denominan pesos convolucionales. Estos se inicializan y luego se actualizan con la retropropagación mediante el descenso de gradiente.
Leer: Tutorial de detección de objetos de TensorFlow para principiantes
puesta en común
La capa de agrupación se coloca entre las capas de convolución. Es responsable de realizar operaciones de agrupación en los mapas de características enviados por una capa de convolución. La operación de agrupación reduce el tamaño espacial de las características, también conocida como reducción de dimensionalidad.
Una de las razones principales para la agrupación es disminuir la potencia computacional requerida para procesar los datos. Aunque una capa de agrupación reduce el tamaño de las imágenes, conserva sus características importantes. El funcionamiento es similar a un filtro CNN. El kernel revisa las características y agrega los valores cubiertos por el filtro.
De la imagen es claramente visible que puede haber varias funciones de agregación. La agrupación media y máxima son las operaciones de agrupación más utilizadas. La agrupación reduce las dimensiones de las características pero mantiene las características intactas.
Al reducir el número de parámetros, los cálculos también se reducen en la red. Esto reduce el sobreaprendizaje y aumenta la eficiencia de la red. El grupo máximo se usa principalmente porque los valores máximos se detectan con menos precisión en el mapa combinado en comparación con los mapas de convolución.
Esto es bueno para muchos casos. Digamos que si se quiere reconocer a un perro no es necesario ubicar sus orejas con la mayor precisión posible, basta con saber que están ubicadas casi al lado de la cabeza.
Max Pooling también funciona como supresor de ruido. Descarta por completo las activaciones ruidosas y también elimina el ruido junto con la reducción de la dimensionalidad. Por otro lado, Average Pooling simplemente realiza una reducción de dimensionalidad como un mecanismo de supresión de ruido. Por lo tanto, podemos decir que Max Pooling funciona mucho mejor que Average Pooling.
Función de activación
ReLU (Unidades lineales rectificadas) es la capa de función de activación más utilizada.
La ecuación para el mismo es: ReLU(x)=max(0,x)
Y la representación gráfica se da a continuación:
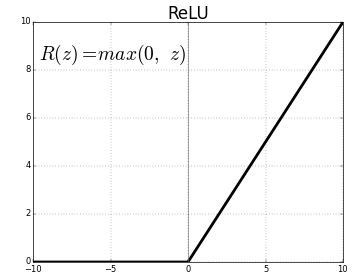
Fuente: Medio
Representación ReLU
ReLU mapea los valores negativos a cero y mantiene los positivos como están.
Capa completamente conectada
Una capa totalmente conectada suele ser la última capa de cualquier red neuronal. Esta capa recibe vectores de entrada y produce una nueva capa de salida. Esta capa de salida tiene n número de neuronas donde n es el número de clases en la clasificación de la imagen. Cada elemento del vector proporciona la probabilidad de que la imagen sea de cierta clase. Por lo tanto, la suma de todos los vectores en la capa de salida siempre es 1.

Los cálculos que se realizan en la capa de salida son los siguientes:
- Elemento multiplicado por el peso de la neurona
- Aplicar la función de activación en la capa (logística cuando n=2, sigmoide cuando n>2)
La salida ahora será la probabilidad de que la imagen pertenezca a una determinada clase. Los pesos de la capa se aprenden durante el entrenamiento mediante la retropropagación del gradiente.
Lea también: Introducción al modelo de red neuronal
Capa de abandono
Las capas de exclusión funcionan como una capa de regularización que reduce el sobreajuste y mejora el error de generalización. El sobreajuste es una preocupación importante al usar una red neuronal. La deserción, como sugiere el nombre, elimina un porcentaje de neuronas en las capas después de las cuales se usa.
El método de regularización empleado por dropout es que se aproxima al entrenamiento de un gran número de redes neuronales con diferentes arquitecturas paralelas. Durante el período de entrenamiento, algunas de las salidas de la capa se descartan o ignoran aleatoriamente. Esto hace que la capa parezca una capa con diferentes números de nodos y algunas neuronas están apagadas. De ahí que la conectividad también cambie según la capa anterior.
Hiperparámetros
Hay ciertos parámetros que se pueden controlar de acuerdo con los datos de imagen que se están tratando. Cada capa de una CNN se puede parametrizar, ya sea capa de convolución o capa de agrupación. Los parámetros afectan el tamaño del mapa de características que es la salida para esa capa específica.
Cada imagen (entrada) o mapa de funciones (salidas subsiguientes de capas) tienen las dimensiones: ancho x alto x profundidad, donde ancho x alto es ancho x alto, es decir, el tamaño del mapa o la imagen. D representa la dimensión sobre la base de segmentos de color. Las imágenes monocromáticas tendrán D=1 y RGB, es decir, las imágenes en color tendrán D=3.
Hiperparámetros de capa de convolución
- Número de filtros (K)
- Tamaño del filtro (F) de la dimensión FxFxD
- Strides: número de pasos que toma el kernel para desplazarse sobre la imagen. S=1 significa que el núcleo se moverá con 1 píxel como paso.
- Relleno cero: el relleno cero se realiza para imágenes que tienen menos tamaño, porque las capas de convolución y grupo máximo reducen el tamaño del mapa de características en cada iteración.
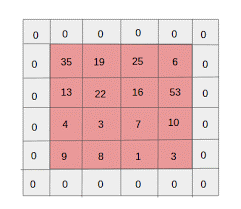
Fuente: XRDS
El relleno cero aumentó el tamaño de la imagen de entrada
Para cada imagen de entrada de tamaño W×HxD, la capa de agrupación devuelve una matriz de dimensiones Wc×Hc×Dc. Donde
Wc= (W-F+2P)/S+1
Hc= (H-F+2P)/S+1
CC = K
Resolviendo las ecuaciones para encontrar el valor de Padding(P)=F-1/2 y Stride(S)=1
En general, elegimos F=3,P=1,S=1 o F=5,P=2,S=1
Hiperparámetros de la capa de agrupación
- Tamaño de celda (F): el tamaño de celda cuadrada en el que se dividirá el mapa para la agrupación. FxF
- Tamaño de paso (S): las celdas están separadas por S píxeles
Para cada imagen de entrada de tamaño W×H×D, la capa de agrupación devuelve una matriz de dimensiones Wp×Hp×Dp, donde
Wp= (WF)/S+1
CV= (HF)/S+1
Dp = D
Para la capa de agrupación, se elige ampliamente F=2 y S=2. Se elimina el 75% de los píxeles de entrada. También se puede elegir F=3 y S=2. El tamaño de celda más grande dará como resultado una gran pérdida de información, por lo que solo es adecuado para imágenes de entrada de tamaño muy grande.
Hiperparámetros generales
- Tasa de aprendizaje: se pueden elegir optimizadores como SGD, AdaGrad o RMSProp para optimizar la tasa de aprendizaje.
- Épocas: el número de épocas debe aumentarse hasta que aparezca una brecha en el entrenamiento y un error de validación.
- Tamaño del lote: se pueden seleccionar de 16 a 128. Depende de la cantidad de poder de procesamiento que uno tenga.
- Función de activación: introduce la no linealidad en el modelo. ReLu se usa típicamente para Conv Nets. Otras opciones son: sigmoide, tanh.
- Dropout: un valor de abandono de 0,1 elimina el 10% de las neuronas. 0,5 es un buen punto de partida. 0,25 es una buena opción final.
- Inicialización de peso: se pueden inicializar pequeños pesos aleatorios para desviar la posibilidad de neuronas muertas. Pero no demasiado pequeño para el descenso de gradiente. La distribución uniforme es adecuada.
- Capas ocultas: las capas ocultas se pueden aumentar hasta que el error de prueba disminuya. El aumento de las capas ocultas aumentará la computación y requerirá regularización.
Conclusión
Tenemos la información básica para crear una CNN desde cero. Aunque es un artículo completo que cubre todo en un nivel básico, se puede profundizar en cada parámetro o capa. Las matemáticas detrás de cada concepto también son algo que se puede entender para mejorar el modelo.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT- B Estado de exalumno, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.