
Arquitetura de rede neural convolucional: o que você precisa saber?
Publicados: 2020-12-01As redes neurais convolucionais geralmente chamadas pelos nomes como ConvNets ou CNN são uma das arquiteturas de rede neural mais usadas. CNNs são geralmente usadas para dados baseados em imagem. Reconhecimento de imagens, classificação de imagens, detecção de objetos, etc., são algumas das áreas onde as CNNs são amplamente utilizadas.
O ramo da IA aplicada especificamente sobre dados de imagem é denominado como Visão Computacional. Houve um crescimento monumental em Visão Computacional desde a introdução das CNNs. A primeira parte da CNN extrai recursos de imagens usando a função de convolução e ativação para normalização.
O último bloco usa esses recursos com Rede Neural para resolver qualquer problema específico, por exemplo, um problema de classificação terá 'n' número de neurônios de saída dependendo do número de classes presentes para classificação. Vamos tentar entender a arquitetura e o funcionamento de uma CNN.
Índice
Convolução
Convolução é uma técnica de processamento de imagem que usa um kernel ponderado (matriz quadrada) para girar sobre a imagem, multiplicar e adicionar os elementos do kernel com pixels de imagem. Este método pode ser facilmente visualizado pela imagem mostrada abaixo.
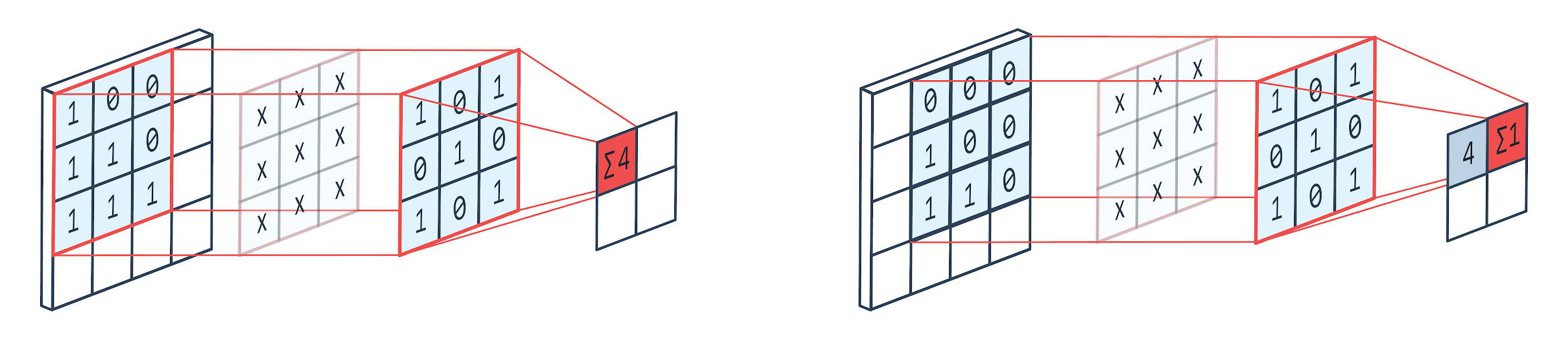
Imagem por: Peltarion
Filtro de convolução e saída

Como podemos ver quando usamos um canil de convolução 3×3, 3×3 parte da imagem é operada e após a multiplicação e posterior adição, um valor vem como saída. Então, em uma imagem 4×4, obteremos uma saída de matriz complicada 2×2, dado que o tamanho do kernel é 3×3.
A saída complicada pode variar de acordo com o tamanho do kernel usado para convolução. Esta é a camada inicial típica de uma CNN. A saída complicada são os recursos encontrados na imagem. Isso está diretamente relacionado ao tamanho do kernel que está sendo usado.
Se a característica de uma imagem for tal que até mesmo pequenas diferenças em uma imagem farão com que ela caia em uma categoria de saída diferente, um tamanho de kernel pequeno será usado para extração de recursos. Caso contrário, um kernel maior pode ser usado. Os valores usados no kernel são frequentemente denominados como pesos convolucionais. Estes são inicializados e atualizados após retropropagação usando gradiente descendente.
Leia: Tutorial de detecção de objetos do TensorFlow para iniciantes
Agrupamento
A camada de pooling é colocada entre as camadas de convolução. Ele é responsável por realizar operações de pooling nos mapas de recursos enviados por uma camada de convolução. A operação de pooling reduz o tamanho espacial dos recursos, também conhecido como redução de dimensionalidade.
Uma das principais razões para o agrupamento é diminuir o poder computacional necessário para processar os dados. Embora uma camada de pooling reduza o tamanho das imagens, preserva suas características importantes. O funcionamento é semelhante a um filtro CNN. O kernel percorre os recursos e agrega os valores cobertos pelo filtro.
A partir da imagem é claramente visível que podem existir várias funções de agregação. O pooling médio e máximo são as operações de pooling mais usadas. O agrupamento reduz as dimensões dos recursos, mas mantém as características intactas.
Ao reduzir o número de parâmetros, os cálculos também reduzem na rede. Isso reduz o aprendizado excessivo e aumenta a eficiência da rede. O max-pool é usado principalmente porque os valores máximos são localizados com menos precisão no mapa agrupado em comparação com os mapas da convolução.
Isso é bom para muitos casos. Digamos que se alguém quiser reconhecer um cão, suas orelhas não precisam ser localizadas com a maior precisão possível, basta saber que elas estão localizadas quase ao lado da cabeça.
Max Pooling também funciona como um supressor de ruído. Ele descarta completamente as ativações ruidosas e também realiza de-noising juntamente com redução de dimensionalidade. Por outro lado, o Average Pooling simplesmente realiza a redução de dimensionalidade como um mecanismo de supressão de ruído. Portanto, podemos dizer que o Max Pooling tem um desempenho muito melhor do que o Average Pooling.
Função de ativação
ReLU (Rectified Linear Units) é a camada de função de ativação mais comumente usada.
A equação para o mesmo é: ReLU(x)=max(0,x)
E a representação gráfica é dada abaixo:
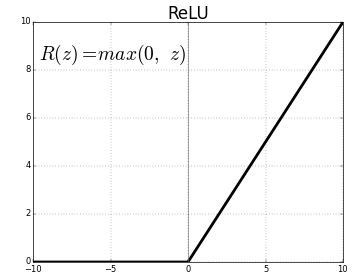
Fonte: Médio
Representação ReLU
ReLU mapeia os valores negativos para zero e mantém os positivos como estão.
Camada totalmente conectada
Uma camada totalmente conectada é geralmente a última camada de qualquer rede neural. Esta camada recebe vetores de entrada e produz uma nova camada de saída. Esta camada de saída possui n número de neurônios onde n é o número de classes na classificação da imagem. Cada elemento do vetor fornece a probabilidade da imagem ser de uma determinada classe. Portanto, a soma de todos os vetores na camada de saída é sempre 1.

Os cálculos que acontecem na camada de saída são os seguintes:
- Elemento multiplicado pelo peso do neurônio
- Aplicar função de ativação na camada (logística quando n=2, sigmóide quando n>2)
A saída agora será a probabilidade da imagem pertencer a uma determinada classe. Os pesos da camada são aprendidos durante o treinamento por retropropagação do gradiente.
Leia também: Introdução ao modelo de rede neural
Camada de descarte
As camadas de dropout funcionam como uma camada de regularização que reduz o overfitting e melhora o erro de generalização. O overfitting é uma grande preocupação ao usar uma rede neural. Dropout, como o nome sugere, elimina alguma porcentagem de neurônio nas camadas após as quais é usado.
O método de regularização empregado pelo dropout é que aproxima o treinamento de um grande número de redes neurais com diferentes arquiteturas paralelas. Durante o período de treinamento, algumas das saídas da camada são descartadas ou ignoradas aleatoriamente. Isso faz com que a camada pareça uma camada com diferentes números de nós e alguns neurônios sejam desligados. Portanto, a conectividade também muda de acordo com a camada anterior.
Hiperparâmetros
Existem certos parâmetros que podem ser controlados de acordo com os dados de imagem que estão sendo tratados. Cada camada de uma CNN pode ser parametrizada, seja camada de convolução ou camada de pooling. Os parâmetros afetam o tamanho do mapa de feição que é a saída para aquela camada específica.
Cada imagem (entrada) ou mapa de recursos (saídas subsequentes de camadas) são das dimensões: W x H x D onde W x H é largura x altura, ou seja, o tamanho do mapa ou imagem. D representa a dimensão com base em segmentos de cor. Imagens monocromáticas terão D=1 e RGB, ou seja, imagens coloridas terão D=3.
Hiperparâmetros da camada de convolução
- Número de filtros (K)
- Tamanho do filtro (F) da dimensão FxFxD
- Strides: Número de passos dados para que o kernel se desloque sobre a imagem. S=1 significa que o kernel se moverá com 1 pixel como passo.
- Zero padding: zero padding é feito para imagens com tamanho menor, porque as camadas de convolução e pool máximo reduzem o tamanho do mapa de recursos em cada iteração.
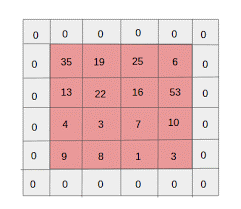
Fonte: XRDS
O preenchimento zero aumentou o tamanho da imagem de entrada
Para cada imagem de entrada de tamanho W×H×D, a camada de agrupamento retorna uma matriz de dimensões Wc×Hc×Dc. Onde
Wc= (W-F+2P)/S+1
Hc= (H-F+2P)/S+1
Dc = K
Resolvendo as equações para encontrar o valor de Padding(P)=F-1/2 e Stride(S)=1
Em geral, escolhemos F=3,P=1,S=1 ou F=5,P=2,S=1
Hiperparâmetros da camada de pool
- Tamanho da célula (F): O tamanho da célula quadrada em que o mapa será dividido para agrupamento. FxF
- Tamanho da etapa (S): as células são separadas por S pixels
Para cada imagem de entrada de tamanho W×H×D, a camada de agrupamento retorna uma matriz de dimensões Wp×Hp×Dp, onde
Wp= (WF)/S+1
Hp= (HF)/S+1
Dp=D
Para a camada de agrupamento, F=2 e S=2 são amplamente escolhidos. 75% dos pixels de entrada são eliminados. Pode-se também escolher F=3 e S=2. Um tamanho de célula maior resultará em grande perda de informações, portanto, adequado apenas para imagens de entrada de tamanho muito grande.
Hiperparâmetros gerais
- Taxa de aprendizado: Otimizadores como SGD, AdaGrad ou RMSProp podem ser escolhidos para otimizar a taxa de aprendizado.
- Epochs: O número de Epochs deve ser aumentado até que apareça uma lacuna no erro de treinamento e validação
- Tamanho do lote: 16 a 128 podem ser selecionados. Depende da quantidade de poder de processamento que se tem.
- Função de ativação: Introduz não linearidade no modelo. ReLu é normalmente usado para Conv Nets. Outras opções são: sigmoid, tanh.
- Dropout: um valor de dropout de 0,1 derruba 10% dos neurônios. 0,5 é um bom ponto de partida. 0,25 é uma boa opção final.
- Inicialização de peso: Pequenos pesos aleatórios podem ser inicializados para desviar a possibilidade de neurônios mortos. Mas não muito pequeno para descida de gradiente. A distribuição uniforme é adequada.
- Camadas ocultas: As camadas ocultas podem ser aumentadas até que o erro de teste diminua. Aumentar as camadas ocultas aumentará a computação e exigirá regularização.
Conclusão
Temos as informações básicas para criar uma CNN do zero. Embora seja um artigo abrangente que cobre tudo em um nível básico, cada parâmetro ou camada pode ser aprofundado. A matemática por trás de cada conceito também é algo que pode ser entendido para a melhoria do modelo
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.