
Architektura splotowych sieci neuronowych: co musisz wiedzieć?
Opublikowany: 2020-12-01Splotowe sieci neuronowe zwykle nazywane takimi nazwami jak ConvNets lub CNN są jedną z najczęściej używanych architektury sieci neuronowych. Sieci CNN są zwykle używane do danych opartych na obrazach. Rozpoznawanie obrazu, klasyfikacja obrazu, wykrywanie obiektów itp. to tylko niektóre z obszarów, w których szeroko stosowane są sieci CNN.
Gałąź Applied AI, w szczególności danych obrazu, określana jest jako Computer Vision. Od czasu wprowadzenia CNN nastąpił ogromny wzrost w dziedzinie wizji komputerowej. Pierwsza część CNN wyodrębnia cechy z obrazów przy użyciu funkcji splotu i aktywacji w celu normalizacji.
Ostatni blok wykorzystuje te funkcje z siecią neuronową do rozwiązania dowolnego konkretnego problemu, na przykład problem klasyfikacji będzie miał 'n' liczbę neuronów wyjściowych w zależności od liczby klas obecnych do klasyfikacji. Spróbujmy zrozumieć architekturę i działanie CNN.
Spis treści
Skręt
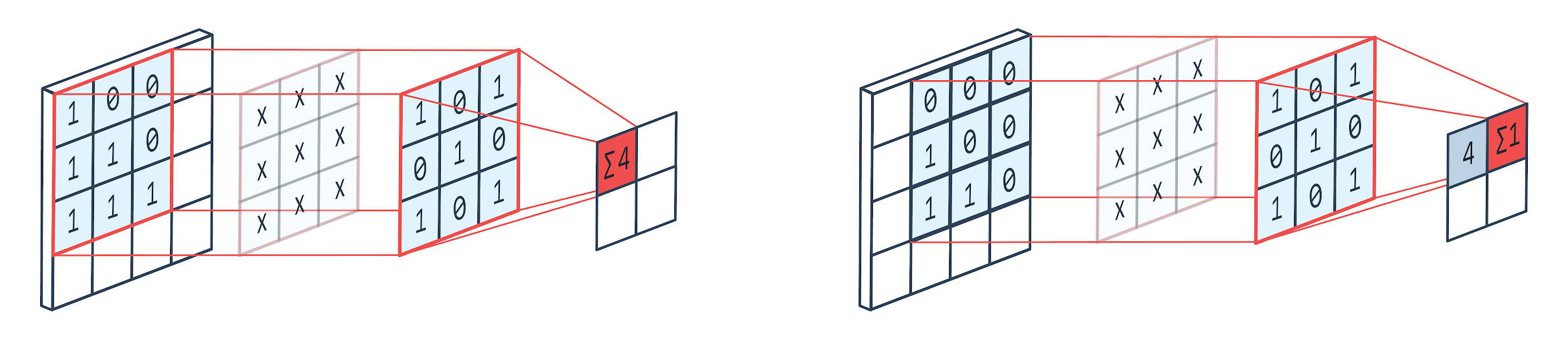
Konwolucja to technika przetwarzania obrazu, która wykorzystuje ważone jądro (macierz kwadratowy) do obracania się nad obrazem, mnożenia i dodawania elementów jądra z pikselami obrazu. Sposób ten można łatwo zwizualizować na poniższym obrazku.
Zdjęcie: Peltarion
Filtr konwolucji i wyjście

Jak widać, gdy używamy hodowli konwolucji 3×3, operowana jest część obrazu 3×3, a po mnożeniu, a następnie dodaniu, jako wynik otrzymujemy jedną wartość. Tak więc na obrazie 4×4 otrzymamy wynikową macierz zawiłą 2×2, biorąc pod uwagę rozmiar jądra 3×3.
Zawinięte dane wyjściowe mogą się różnić w zależności od rozmiaru jądra użytego do splotu. To jest typowa początkowa warstwa CNN. Zawiłe wyjście to cechy znalezione na obrazie. Jest to bezpośrednio związane z używanym rozmiarem jądra.
Jeśli charakterystyka obrazu jest taka, że nawet niewielkie różnice w obrazie sprawią, że będzie on zaliczany do innej kategorii wyjściowej, do wyodrębnienia cech używany jest mały rozmiar jądra. W przeciwnym razie można użyć większego jądra. Wartości używane w jądrze są często określane jako wagi splotowe. Są one inicjowane, a następnie aktualizowane po wstecznej propagacji za pomocą gradientu.
Przeczytaj: Samouczek wykrywania obiektów TensorFlow dla początkujących
Łączenie
Warstwa puli jest umieszczona pomiędzy warstwami konwolucji. Odpowiada za wykonywanie operacji łączenia na mapach obiektów przesłanych przez warstwę konwolucji. Operacja łączenia w pulę zmniejsza rozmiar przestrzenny funkcji, znany również jako redukcja wymiarowości.
Jednym z głównych powodów łączenia danych jest zmniejszenie mocy obliczeniowej wymaganej do przetwarzania danych. Chociaż warstwa zbiorcza zmniejsza rozmiar obrazów, zachowuje ich ważne cechy. Działanie jest podobne do filtra CNN. Jądro sprawdza cechy i agreguje wartości objęte filtrem.
Z obrazu wyraźnie widać, że mogą istnieć różne funkcje agregacji. Pule średnie i maksymalne są najczęściej używanymi operacjami łączenia. Łączenie zmniejsza wymiary cech, ale zachowuje nienaruszone cechy.
Zmniejszając liczbę parametrów, zmniejszają się również obliczenia w sieci. Zmniejsza to nadmierne uczenie się i zwiększa wydajność sieci. Maksymalna pula jest najczęściej używana, ponieważ maksymalne wartości są mniej dokładnie wykrywane na mapie połączonej w porównaniu z mapami z konwolucji.
To jest dobre w wielu przypadkach. Powiedzmy, że jeśli chcemy rozpoznać psa, jego uszy nie muszą być zlokalizowane jak najdokładniej, wystarczy wiedzieć, że znajdują się prawie obok głowy.
Max Pooling działa również jako tłumik hałasu. Całkowicie odrzuca zaszumione aktywacje, a także wykonuje usuwanie szumów wraz z redukcją wymiarowości. Z drugiej strony, łączenie średnie po prostu wykonuje redukcję wymiarowości jako mechanizm tłumienia szumów. Dlatego możemy powiedzieć, że Max Pooling działa o wiele lepiej niż Average Pooling.
Funkcja aktywacji
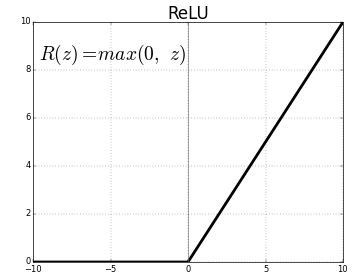
ReLU (Rectified Linear Units) jest najczęściej stosowaną warstwą funkcji aktywacji.
Równanie na to samo to: ReLU(x)=max(0,x)
A graficzna reprezentacja jest podana poniżej:
Źródło: Średni
Reprezentacja ReLU
ReLU odwzorowuje wartości ujemne na zero i zachowuje wartości dodatnie bez zmian.
W pełni połączona warstwa
W pełni połączona warstwa jest zwykle ostatnią warstwą dowolnej sieci neuronowej. Ta warstwa odbiera wektory wejściowe i tworzy nową warstwę wyjściową. Ta warstwa wyjściowa ma n liczbę neuronów, gdzie n to liczba klas w klasyfikacji obrazu. Każdy element wektora określa prawdopodobieństwo, że obraz należy do określonej klasy. Stąd suma wszystkich wektorów w warstwie wyjściowej wynosi zawsze 1.

Obliczenia zachodzące w warstwie wyjściowej są następujące:
- Element pomnożony przez wagę neuronu
- Zastosuj funkcję aktywacji na warstwie (logistyka, gdy n=2, sigmoid, gdy n>2)
Wynikiem będzie teraz prawdopodobieństwo, że obraz należy do określonej klasy. Wagi warstwy są poznawane podczas treningu poprzez wsteczną propagację gradientu.
Przeczytaj także: Wprowadzenie do modelu sieci neuronowej
Warstwa odrzucania
Warstwy usuwane działają jako warstwa regularyzacji, która zmniejsza nadmierne dopasowanie i poprawia błąd uogólniania. Nadmierne dopasowanie jest głównym problemem podczas korzystania z sieci neuronowej. Dropout, jak sama nazwa wskazuje, odrzuca pewien procent neuronów w warstwach, po których jest używany.
Metoda regularyzacji stosowana przez dropout polega na tym, że przybliża trenowanie dużej liczby sieci neuronowych o różnych architekturach równoległych. W okresie uczenia niektóre dane wyjściowe warstwy są losowo pomijane lub ignorowane. To sprawia, że warstwa wygląda jak warstwa z różną liczbą węzłów, a niektóre neurony są wyłączone. Stąd łączność zmienia się również zgodnie z poprzednią warstwą.
Hiperparametry
Istnieją pewne parametry, którymi można sterować w zależności od przetwarzanych danych obrazu. Każdą warstwę CNN można sparametryzować, czy to warstwę konwolucji, czy warstwę puli. Parametry wpływają na rozmiar mapy obiektów będącej wynikiem dla tej konkretnej warstwy.
Każdy obraz (wejście) lub mapa cech (kolejne wyjścia warstw) mają wymiary: szer. x wys. x gł. gdzie szer. x wys. to szerokość x wysokość, czyli rozmiar mapy lub obrazu. D reprezentuje wymiar na podstawie segmentów kolorów. Obrazy monochromatyczne będą miały D=1 i RGB, tj. kolorowe obrazy będą miały D=3.
Hiperparametry warstwy konwolucji
- Liczba filtrów (K)
- Rozmiar filtra (F) o wymiarze FxFxD
- Kroki: liczba kroków, które jądro przemieściło nad obrazem. S=1 oznacza, że jądro przesunie się z krokiem 1 piksela.
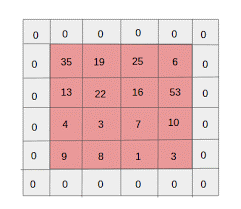
- Zero padding: zero padding jest wykonywane dla obrazów o mniejszym rozmiarze, ponieważ warstwy konwolucji i maksymalnej puli zmniejszają rozmiar mapy cech w każdej iteracji.
Źródło: XRDS
Zerowe dopełnienie zwiększyło rozmiar obrazu wejściowego
Dla każdego obrazu wejściowego o rozmiarze W×H×D, warstwa zbiorcza zwraca macierz o wymiarach Wc×Hc×Dc. Gdzie
Wc= (W-F+2P)/S+1
Hc= (H-F+2P)/S+1
Dc= K
Rozwiązywanie równań, aby znaleźć wartość Padding(P)=F-1/2 i Stride(S)=1
Ogólnie wybieramy wtedy F=3,P=1,S=1 lub F=5,P=2,S=1
Hiperparametry warstwy puli
- Rozmiar komórki (F): Kwadratowy rozmiar komórki, w którym mapa zostanie podzielona do puli. FxF
- Rozmiar kroku (S): Komórki są oddzielone S pikselami
Dla każdego obrazu wejściowego o rozmiarze W×Hp×D, warstwa puli zwraca macierz o wymiarach Wp×Hp×Dp, gdzie
Wp= (WF)/S+1
Hp= (HF)/S+1
Dp= D
W przypadku warstwy puli, F=2 i S=2 są szeroko wybierane. 75% pikseli wejściowych jest eliminowanych. Można również wybrać F=3 i S=2. Większy rozmiar komórki spowoduje dużą utratę informacji, dlatego nadaje się tylko do bardzo dużych obrazów wejściowych.
Ogólne hiperparametry
- Szybkość uczenia się: Optymalizatory, takie jak SGD, AdaGrad lub RMSProp, można wybrać w celu optymalizacji szybkości uczenia się.
- Epoki: Liczba epok powinna być zwiększana, aż pojawi się luka w szkoleniu i błędach walidacji
- Wielkość partii: można wybrać od 16 do 128. Zależy od posiadanej mocy obliczeniowej.
- Funkcja aktywacji: Wprowadza do modelu nieliniowość. ReLu jest zwykle używany dla Conv Nets. Inne opcje to: sigmoid, tanh.
- Dropout: wartość dropout 0,1 spada 10% neuronów. 0,5 to dobry punkt wyjścia. 0,25 to dobra ostateczna opcja.
- Inicjalizacja wagi: można zainicjować małe losowe wagi, aby odwrócić możliwość martwych neuronów. Ale nie za mały na zjazd w dół. Odpowiednia jest równomierna dystrybucja.
- Ukryte warstwy: Ukryte warstwy można zwiększać, aż błąd testu się zmniejszy. Zwiększenie ukrytych warstw zwiększy obliczenia i będzie wymagało uregulowania.
Wniosek
Mamy podstawowe informacje, aby stworzyć CNN od podstaw. Chociaż jest to obszerny artykuł, który obejmuje wszystko na podstawowym poziomie, każdy parametr lub warstwę można głębiej zagłębić. Matematyka stojąca za każdą koncepcją jest również czymś, co można zrozumieć w celu ulepszenia modelu
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, IIIT- Status absolwenta B, ponad 5 praktycznych, praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.