
Apache Kafka 教程:簡介、概念、工作流程、工具、應用程序
已發表: 2020-03-10目錄
介紹
隨著 Kafka 作為消息傳遞系統的日益普及,許多公司需要具備 Kafka 技能知識的專業人員,這就是Apache Kafka 教程派上用場的地方。 大數據領域中使用了大量數據,需要一個消息系統來進行數據收集和分析。
Kafka 是傳統消息代理的有效替代品,具有更高的吞吐量、固有的分區和復制以及內置的容錯能力,使其適用於大規模的消息處理應用程序。 如果您一直在尋找Apache Kafka 教程,那麼這是適合您的文章。
本Apache Kafka 教程的主要內容
- 消息系統的概念
- Apache Kafka 簡介
- Kafka集群和Kafka架構相關概念
- Kafka消息傳遞工作流程的簡要描述
- Kafka 重要工具概述
- Apache Kafka的用例和應用
另請了解:面向初學者的 Apache Spark 流式處理教程
消息系統的簡要概述
消息系統的主要功能是允許數據從一個應用程序傳輸到另一個應用程序; 系統確保應用程序只關注數據,在數據共享和傳輸過程中不會卡頓。 有兩種消息傳遞系統:
1.點對點消息系統
在這個系統中,消息的生產者被稱為發送者,而消費消息的人被稱為接收者。 在該域中,消息通過稱為隊列的目的地進行交換; 發送者或生產者將消息生成到隊列中,消息由隊列中的接收者消費。

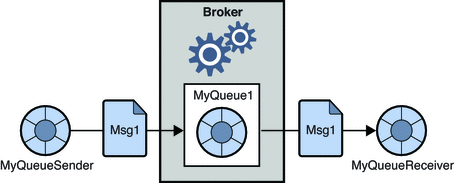
資源
2.發布訂閱消息系統
在這個系統中,消息的生產者稱為發布者,而消費消息的人稱為訂閱者。 但是,在此域中,消息通過稱為主題的目的地進行交換。 發布者向某個主題生成消息,並且訂閱了一個主題,訂閱者使用來自該主題的消息。 該系統允許廣播消息(擁有多個訂閱者,並且每個訂閱者都獲得發佈到特定主題的消息的副本)。
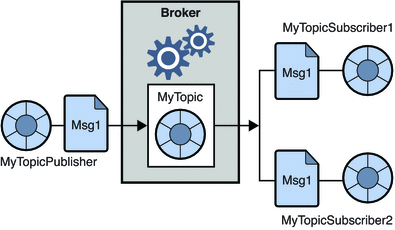
資源
阿帕奇卡夫卡——介紹
Apache Kafka 基於發布-訂閱 (pub-sub) 消息傳遞系統。 在發布-訂閱消息系統中,發布者是消息的生產者,訂閱者是消息的消費者。 在這個系統中,消費者可以消費訂閱主題的所有消息。這個發布-訂閱消息系統的原理在 Apache Kafka 中得到了應用。
此外,Apache Kafka 使用分佈式消息傳遞的概念,因此,在消息傳遞系統和應用程序之間存在非同步的消息排隊。 憑藉能夠處理大量數據的強大隊列,Kafka 允許您將消息從一個端點傳輸到另一個端點,並且適用於消息的在線和離線消費。 Apache Kafka 結合了可靠性、可擴展性、持久性和高吞吐量性能,是現實世界中大規模數據系統單元之間集成和通信的理想選擇。
另請閱讀:大數據項目理念
資源
Apache Kafka 集群的概念
資源
- Kafka zookeeper :集群中的brokers由zookeepers協調和管理。 Zookeeper 通知生產者和消費者有關 Kafka 系統中存在新代理或代理失敗的信息,並通知消費者有關偏移值的信息。 生產者和消費者在收到來自動物園管理員的信息後,與另一個經紀人協調他們的活動。
- Kafka 代理: Kafka 代理是負責在動物園管理員的幫助下維護 Kafka 集群中已發布數據的系統。 對於每個主題,代理可能有零個或多個分區。
- Kafka生產者:一個或多個Kafka主題的消息由生產者發布並推送給broker,無需等待broker確認。
- Kafka 消費者:消費者從代理中提取數據並使用來自一個或多個主題的已發布消息,向代理髮出非同步拉取請求以準備好使用字節緩衝區,然後提供偏移值以回退或跳到任何分區點。
Kafka 架構的基本概念
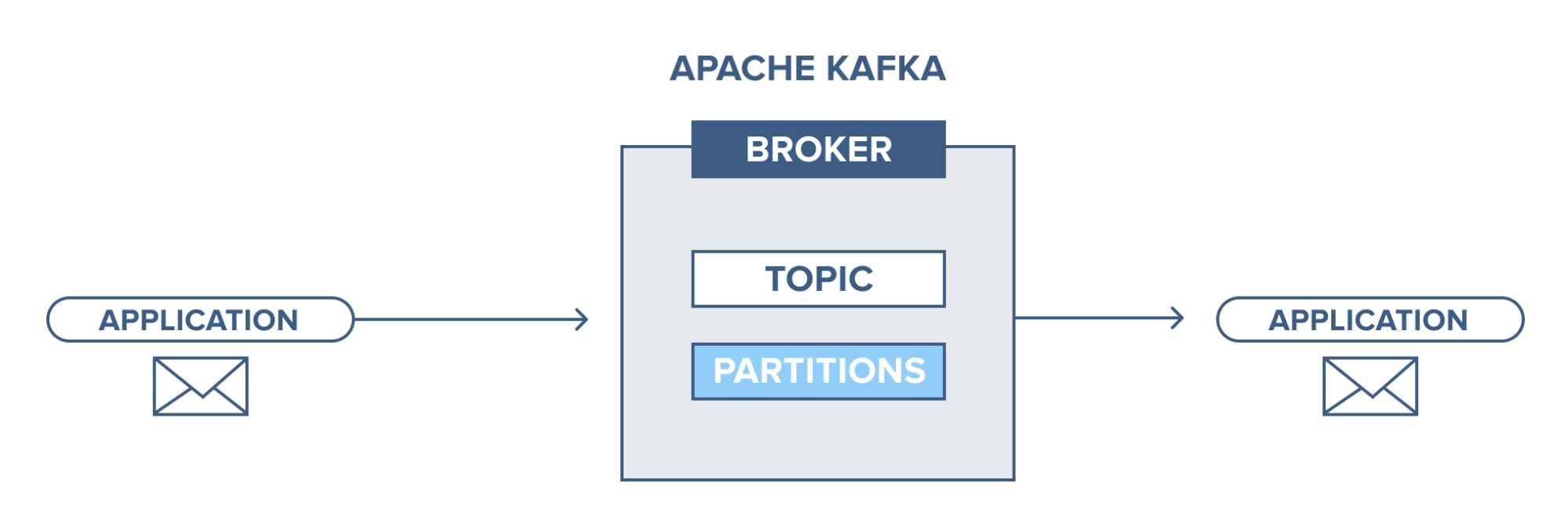
- 主題:它是一個邏輯通道,生產者向其發布消息,消費者從中接收消息。 主題可以復制(複製)以及分區(劃分)。 特定類型的消息發佈在特定主題上,每個主題都可以通過其唯一名稱來識別。
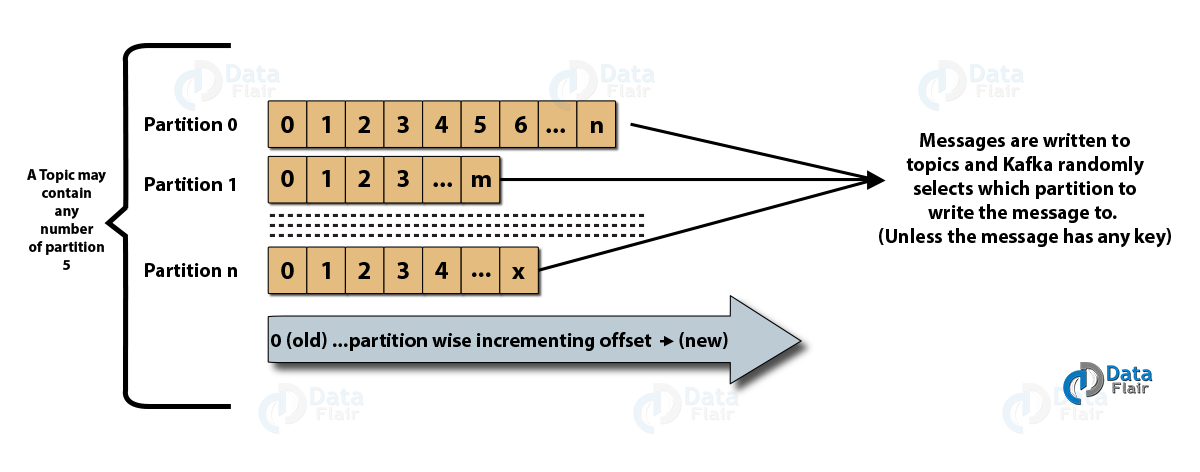
- 主題分區:在 Kafka 集群中,主題被劃分為多個分區以及跨代理複製。 生產者可以為發布的消息添加一個密鑰,具有相同密鑰的消息最終會在同一個分區中。 一個名為 offset 的增量 ID 被分配給一個分區中的每條消息,這些 ID 只在分區內有效,並且在主題中的分區之間沒有任何值。
- 領導者和副本:每個 Kafka 代理都有幾個分區,每個分區可以是領導者或主題的副本(備份)。 領導者不僅負責讀取和寫入主題,還負責使用新數據更新副本。 在任何情況下,如果領導者失敗,副本可以接管作為新領導者。
阿帕奇卡夫卡的架構
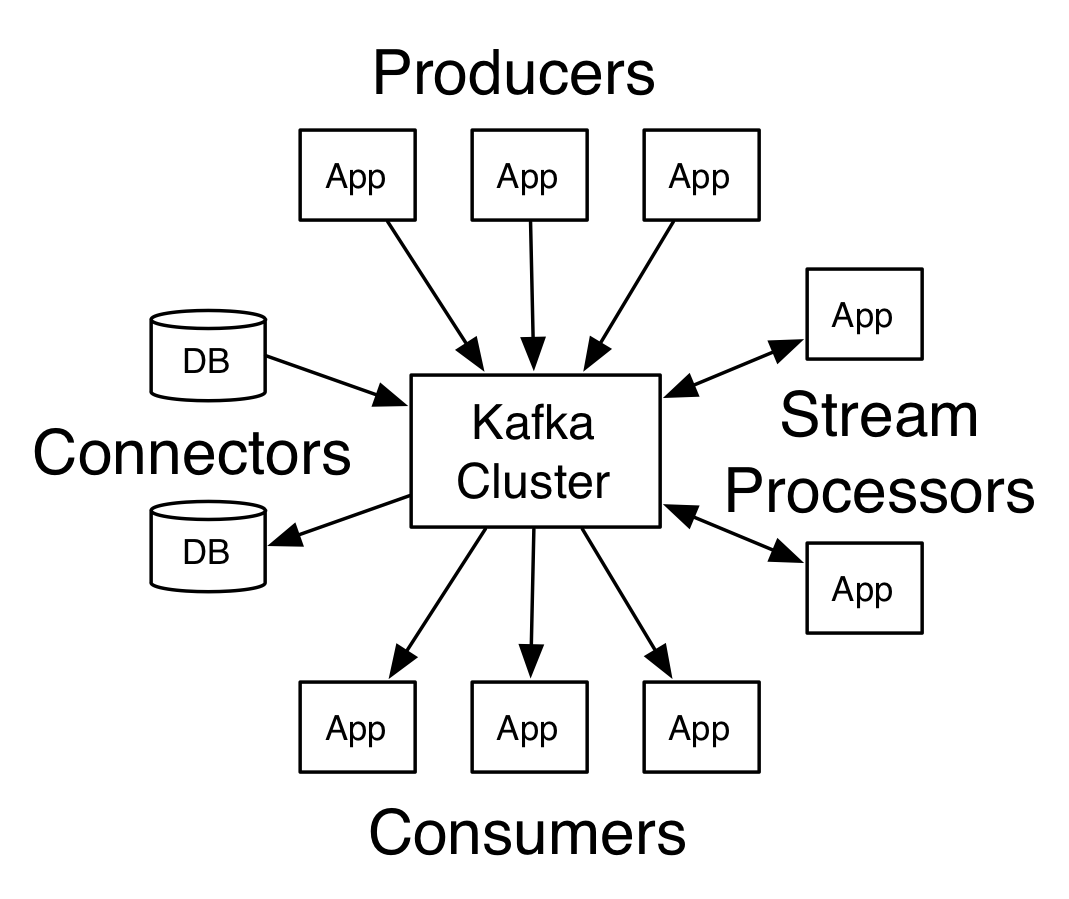
資源

擁有多個代理的 Kafka 稱為 Kafka 集群。 本Apache Kafka 教程將討論四個核心 API :
- 生產者 API: Kafka 生產者 API 允許應用程序將記錄流發佈到一個或多個 Kafka 主題。
- 消費者 API:消費者 API 允許應用程序處理生成到一個或多個主題的連續記錄流。
- Streams API:流 API 允許應用程序使用來自一個或多個主題的輸入流並生成一個或多個輸出主題的輸出流,從而允許應用程序充當流處理器。 這有效地將輸入流修改為輸出流。
- 連接器 API:連接器 API 允許創建和運行可重用的生產者和消費者,從而實現 Kafka 主題與現有數據系統或應用程序之間的連接。
發布者-訂閱者消息傳遞域的工作流程
- Kafka 生產者定期向主題發送消息。
- Kafka 代理通過將消息存儲在為特定主題配置的分區中來確保消息在分區內的平等分佈。
- 訂閱特定主題由 Kafka 消費者完成。 一旦消費者訂閱了一個主題,該主題的當前偏移量就會提供給消費者,並且該主題將保存在 zookeeper ensemble 中。
- 消費者定期向 Kafka 請求新消息。
- Kafka 在收到生產者的消息後立即將消息轉發給消費者。
- 消費者接收消息並處理它。
- 處理完消息後,Kafka 代理會立即獲得確認。
- 收到確認後,偏移量將升級為新值。
- 流程重複,直到消費者停止請求。
- 消費者可以隨時跳過或回退偏移量,並根據方便閱讀後續消息。
隊列消息系統的工作流程
在隊列消息系統中,具有相同組 ID 的多個消費者可以訂閱一個主題。 他們被視為一個組並共享消息。 系統的工作流程是:
- Kafka 生產者定期向主題發送消息。
- Kafka 代理通過將消息存儲在為特定主題配置的分區中來確保消息在分區內的平等分佈。
- 單個消費者訂閱特定主題。
- 在新的消費者訂閱同一個主題之前,Kafka 會與單個消費者進行交互。
- 隨著新消費者的到來,數據在兩個消費者之間共享。 重複共享,直到為該主題配置的分區數等於消費者數。
- 當消費者數量超過配置的分區數量時,新消費者將不會收到更多消息。 出現這種情況是因為每個消費者至少有權獲得一個分區,如果沒有分區是空白的,新的消費者必須等待。
Apache Kafka 中的 2 個重要工具
接下來,在本Apache Kafka 教程中,我們將討論打包在“org.apache.kafka.tools.*”下的 Kafka 工具。
1. 複製工具
它是一種高級設計工具,可提供更高的可用性和更高的耐用性。
- Create Topic 工具:該工具用於創建具有復制因子和默認分區數的主題,並使用 Kafka 的默認方案進行副本分配。
- 列出主題工具:此工具列出給定主題列表的信息。 此工具顯示分區、主題名稱、領導者、副本和 isr 等字段。
- 添加分區工具:此工具可以為特定主題添加更多分區。 它還執行添加分區的副本的手動分配。
2.系統工具
運行類腳本可用於在 Kafka 中運行系統工具。 語法是:
- Mirror Maker:這個工具的用途是將一個Kafka集群鏡像到另一個。
- Kafka 遷移工具:此工具有助於將 Kafka 代理從一個版本遷移到另一個版本。
- Consumer Offset Checker:此工具顯示特定主題集的 Kafka 主題、日誌大小、偏移量、分區、消費者組和所有者。
另請閱讀: Apache Pig 教程

Apache Kafka 的 4 大用例
讓我們在這個 Apache Kafka 教程中討論 Apache Kafka 的一些重要用例:
- 流處理: Kafka 強大的持久性特性使其可以應用於流處理領域。 在這種情況下,從主題中讀取數據並進行處理,然後將處理後的數據寫入新主題以使其可供應用程序和用戶使用。
- 指標: Kafka 經常用於數據的操作監控。 統計數據從分佈式應用程序匯總,以集中提供運營數據。
- 跟踪網站活動: BigQuery 和 Google 等數據倉庫使用 Kafka 來跟踪網站上的活動。 搜索、頁面查看或其他用戶操作等站點活動被發佈到中心主題,並可用於實時處理、離線分析和儀表板。
- 日誌聚合:使用 Kafka,可以從許多服務中收集日誌,並以標準化格式提供給許多消費者。
Apache Kafka 的 5 大應用
Kafka 支持的一些最佳工業應用包括:
- Uber:出租車應用程序需要大量的實時處理並處理大量數據。 審計、ETA 計算以及驅動程序和客戶匹配等重要流程都是基於 Kafka Streams 建模的。
- Netflix:點播互聯網流媒體平台 Netflix 使用 Kafka 指標來處理事件和實時監控。
- LinkedIn: LinkedIn 每天管理 7 萬億條消息,包含 100,000 個主題、700 萬個分區和 4000 多個經紀人。 Apache Kafka 在 LinkedIn 中用於用戶活動跟踪、監控和跟踪。
- Tinder:這款流行的約會應用程序將 Kafka Streams 用於多個流程,包括內容審核、推薦、更新用戶時區、通知和用戶激活等。
- Pinterest:每月搜索數十億個圖釘和想法,Pinterest 已將 Kafka 用於許多流程。 Kafka Streams 用於索引內容、檢測垃圾郵件、推薦和計算實時廣告的預算。
結論
在本Apache Kafka 教程中,我們討論了 Apache Kafka 的基本概念、Kafka 中的架構和集群、Kafka 工作流程、Kafka 工具以及 Kafka 的一些應用。 Apache Kafka 具有一些最好的特性,如持久性、可擴展性、容錯性、可靠性、可擴展性、複製和高吞吐量,使其可以在一些最好的工業應用程序中訪問,如本Apache Kafka 教程所示。
如果您有興趣了解有關大數據的更多信息,請查看我們的 PG 大數據軟件開發專業文憑課程,該課程專為在職專業人士設計,提供 7 多個案例研究和項目,涵蓋 14 種編程語言和工具,實用的動手操作研討會,超過 400 小時的嚴格學習和頂級公司的就業幫助。
從世界頂級大學在線學習軟件開發課程。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。