
Tutorial de Apache Kafka: Introducción, conceptos, flujo de trabajo, herramientas, aplicaciones
Publicado: 2020-03-10Tabla de contenido
Introducción
Con la creciente popularidad de Kafka como sistema de mensajería, muchas empresas demandan profesionales con un sólido conocimiento de las habilidades de Kafka, y ahí es donde resulta útil un tutorial de Apache Kafka. Se utiliza una enorme cantidad de datos en el ámbito de Big Data que necesita un sistema de mensajería para la recopilación y el análisis de datos.
Kafka es un reemplazo eficiente del intermediario de mensajes convencional con rendimiento mejorado, partición y replicación inherentes y tolerancia a fallas incorporada, lo que lo hace adecuado para aplicaciones de procesamiento de mensajes a gran escala. Si ha estado buscando un tutorial de Apache Kafka , este es el artículo adecuado para usted.
Conclusiones clave de este tutorial de Apache Kafka
- Concepto de sistemas de mensajería.
- Una breve introducción a Apache Kafka
- Conceptos relacionados con el clúster de Kafka y la arquitectura de Kafka
- Breve descripción del flujo de trabajo de mensajería de Kafka
- Descripción general de las herramientas importantes de Kafka
- Casos de uso y aplicaciones de Apache Kafka
Obtenga también información sobre: Tutorial de Apache Spark Streaming para principiantes
Una breve descripción de los sistemas de mensajería
La función principal de un sistema de mensajería es permitir la transferencia de datos de una aplicación a otra; el sistema garantiza que las aplicaciones se centren únicamente en los datos sin estancarse durante el proceso de intercambio y transmisión de datos. Hay dos tipos de sistemas de mensajería:
1. Sistema de mensajería punto a punto
En este sistema, los productores de los mensajes se denominan emisores y los que consumen los mensajes son receptores. En este dominio, los mensajes se intercambian a través de un destino conocido como cola; los remitentes o los productores producen los mensajes a la cola, y los mensajes son consumidos por los receptores de la cola.

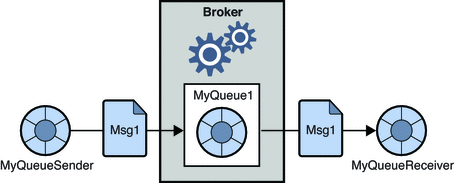
Fuente
2. Sistema de mensajería de publicación-suscripción
En este sistema, los productores de los mensajes se denominan editores y los que consumen los mensajes son suscriptores. Sin embargo, en este dominio, los mensajes se intercambian a través de un destino conocido como tema. Un editor produce los mensajes de un tema y, habiéndose suscrito a un tema, los suscriptores consumen los mensajes del tema. Este sistema permite la difusión de mensajes (tener más de un suscriptor y cada uno recibe una copia de los mensajes publicados sobre un tema en particular).
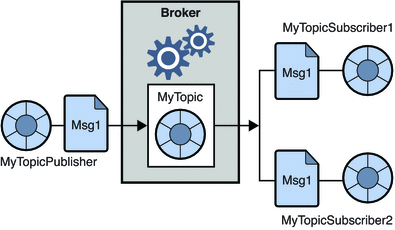
Fuente
Apache Kafka: una introducción
Apache Kafka se basa en un sistema de mensajería de publicación-suscripción (pub-sub). En el sistema de mensajería pub-sub, los editores son los productores de los mensajes y los suscriptores son los consumidores de los mensajes. En este sistema, los consumidores pueden consumir todos los mensajes de los temas suscritos. Este principio del sistema de mensajería pub-sub se emplea en Apache Kafka.
Además, Apache Kafka utiliza el concepto de mensajería distribuida, por lo que existe una cola no sincronizada de mensajes entre el sistema de mensajería y las aplicaciones. Con una cola robusta capaz de manejar un gran volumen de datos, Kafka le permite transmitir mensajes de un punto final a otro y es adecuado para el consumo de mensajes tanto en línea como fuera de línea. Al combinar confiabilidad, escalabilidad, durabilidad y rendimiento de alto rendimiento, Apache Kafka es ideal para la integración y comunicación entre unidades de sistemas de datos a gran escala en el mundo real.
Lea también: Ideas de proyectos de Big Data
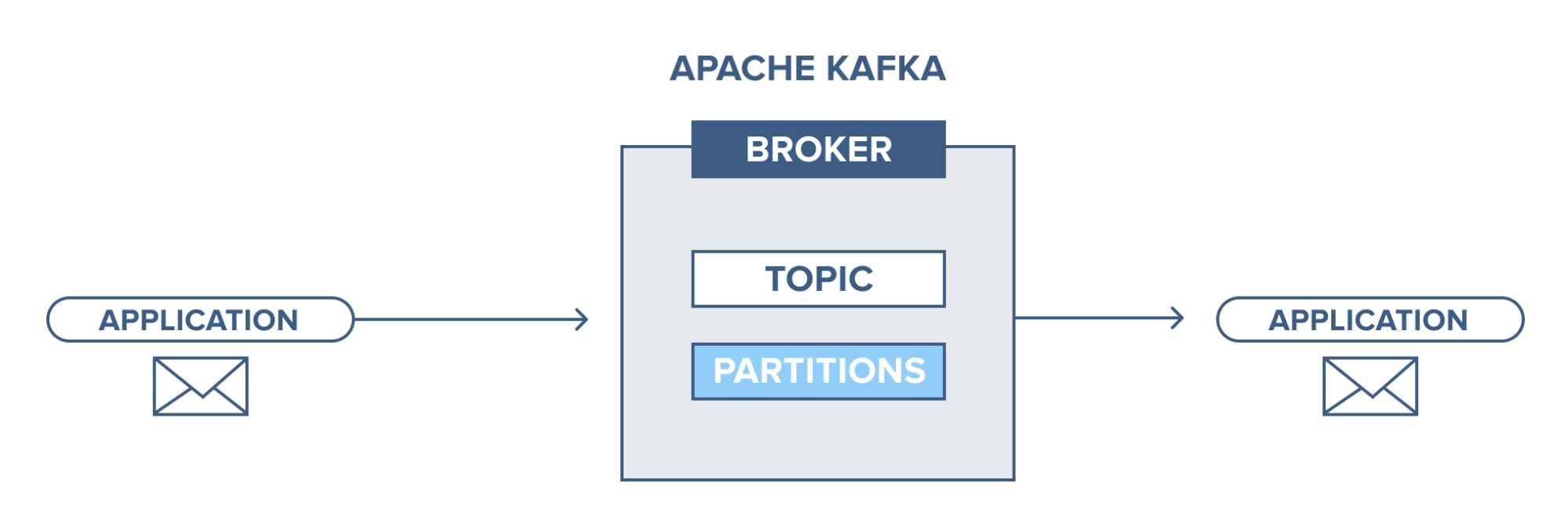
Fuente
Concepto de clústeres de Apache Kafka
Fuente
- Cuidador del zoológico de Kafka: los cuidadores del zoológico coordinan y administran a los intermediarios en un clúster. Zookeeper notifica a los productores y consumidores sobre la presencia de un nuevo corredor o la falla de un corredor en el sistema Kafka, así como también notifica a los consumidores sobre el valor de compensación. Productores y consumidores coordinan sus actividades con otro intermediario al recibir del cuidador del zoológico.
- Agente de Kafka: los agentes de Kafka son sistemas responsables de mantener los datos publicados en los clústeres de Kafka con la ayuda de los cuidadores del zoológico. Un corredor puede tener cero o más particiones para cada tema.
- Productor de Kafka: los mensajes sobre uno o más temas de Kafka son publicados por el productor y enviados a los intermediarios, sin esperar el reconocimiento del intermediario.
- Consumidor de Kafka: los consumidores extraen datos de los intermediarios y consumen mensajes ya publicados de uno o más temas, emiten una solicitud de extracción no síncrona al intermediario para tener un búfer de bytes listo para consumir y luego proporcionan un valor de compensación para rebobinar o saltar a cualquier punto de partición.
Conceptos fundamentales de la arquitectura Kafka
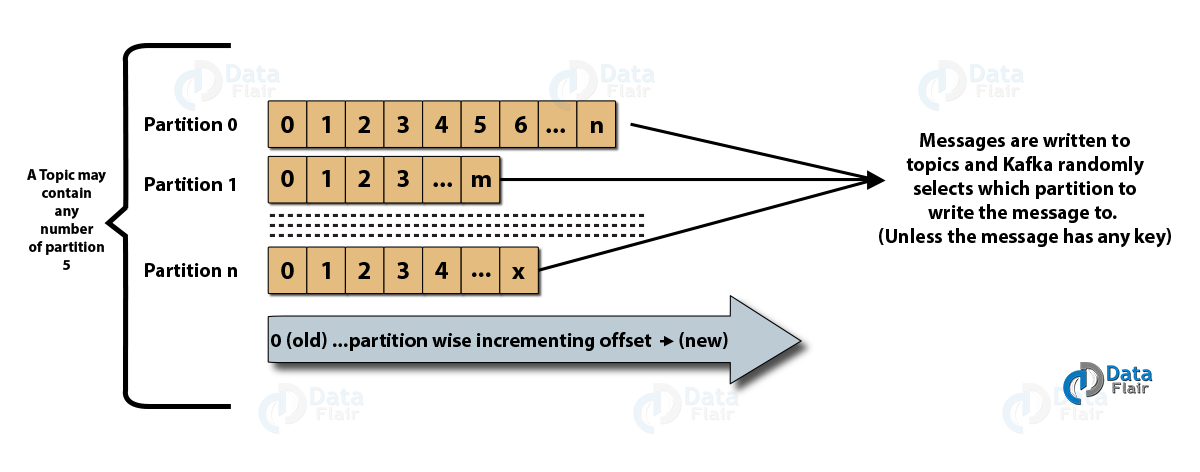
- Tópicos : Es un canal lógico por el cual los productores publican mensajes y desde el cual los consumidores reciben mensajes. Los temas se pueden replicar (copiar), así como particionar (dividir). Se publica un tipo particular de mensaje sobre un tema específico, y cada tema se identifica por su nombre único.
- Particiones de temas: en el clúster de Kafka, los temas se dividen en particiones y se replican entre intermediarios. Un productor puede agregar una clave a un mensaje publicado y los mensajes con la misma clave terminan en la misma partición. Se asigna un ID incremental llamado desplazamiento a cada mensaje en una partición, y estos ID solo son válidos dentro de la partición y no tienen valor entre las particiones de un tema.
- Líder y réplica: cada corredor de Kafka tiene algunas particiones con cada partición, ya sea un líder o una réplica (copia de seguridad) del tema. El líder es responsable no solo de leer y escribir sobre un tema, sino también de actualizar las réplicas con nuevos datos. Si, en cualquier caso, el líder falla, la réplica puede tomar el relevo como el nuevo líder.
Arquitectura de Apache Kafka
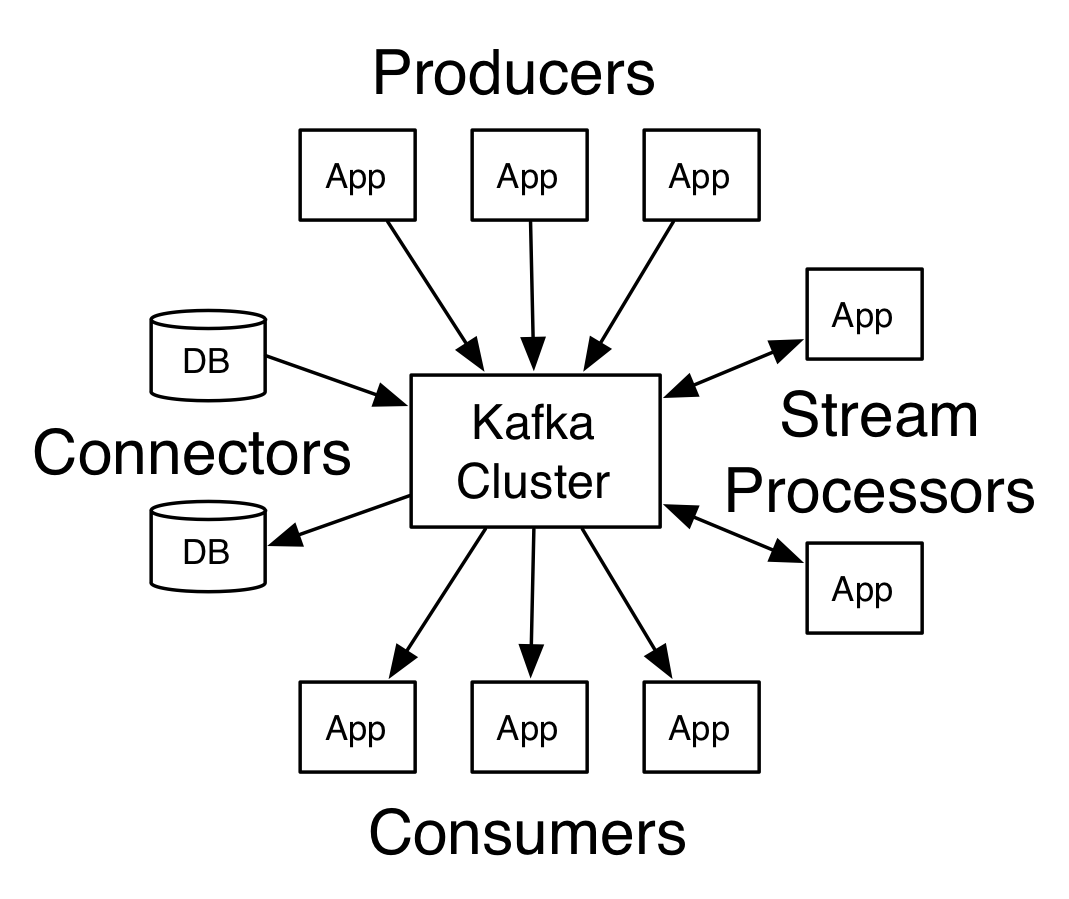
Fuente
Un Kafka que tiene más de un intermediario se denomina clúster de Kafka. Cuatro de las API principales se analizarán en este tutorial de Apache Kafka :
- API de productor: la API de productor de Kafka permite que una aplicación publique un flujo de registros en uno o varios temas de Kafka.
- Consumer API: La API de consumidor permite que una aplicación procese el flujo continuo de registros producidos para uno o más temas.
- API de flujos: la API de flujos permite que una aplicación consuma un flujo de entrada de uno o varios temas y genere un flujo de salida para uno o varios temas de salida, lo que permite que la aplicación actúe como un procesador de flujo. Esto modifica eficientemente los flujos de entrada a los flujos de salida.
- API del conector: la API del conector permite la creación y ejecución de productores y consumidores reutilizables, lo que permite una conexión entre los temas de Kafka y los sistemas o aplicaciones de datos existentes.
Flujo de trabajo del dominio de mensajería editor-suscriptor
- Los productores de Kafka envían mensajes a un tema a intervalos regulares.
- Los agentes de Kafka garantizan la distribución equitativa de los mensajes dentro de las particiones almacenándolos en las particiones configuradas para un tema en particular.
- Los consumidores de Kafka se suscriben a un tema específico. Una vez que el consumidor se ha suscrito a un tema, se le ofrece la compensación actual del tema y el tema se guarda en el conjunto zookeeper.
- El consumidor solicita a Kafka nuevos mensajes a intervalos regulares.
- Kafka reenvía los mensajes a los consumidores inmediatamente después de recibirlos de los productores.
- El consumidor recibe el mensaje y lo procesa.
- El agente de Kafka recibe un reconocimiento tan pronto como se procesa el mensaje.
- Al recibir el acuse de recibo, la compensación se actualiza al nuevo valor.
- El flujo se repite hasta que el consumidor detiene la solicitud.
- El consumidor puede omitir o rebobinar un desplazamiento en cualquier momento y leer los mensajes posteriores según le convenga.
Flujo de trabajo del sistema de mensajería en cola
En un sistema de mensajería en cola, varios consumidores con el mismo ID de grupo pueden suscribirse a un tema. Se consideran un solo grupo y comparten los mensajes. El flujo de trabajo del sistema es:

- Los productores de Kafka envían mensajes a un tema a intervalos regulares.
- Los agentes de Kafka garantizan la distribución equitativa de los mensajes dentro de las particiones almacenándolos en las particiones configuradas para un tema en particular.
- Un solo consumidor se suscribe a un tema específico.
- Hasta que un nuevo consumidor se suscriba al mismo tema, Kafka interactúa con el consumidor único.
- Con la llegada de los nuevos consumidores, los datos se comparten entre dos consumidores. El uso compartido se repite hasta que la cantidad de particiones configuradas para ese tema sea igual a la cantidad de consumidores.
- Un nuevo consumidor no recibirá más mensajes cuando el número de consumidores exceda el número de particiones configuradas. Esta situación surge debido a la condición de que cada consumidor tiene derecho a un mínimo de una partición, y si ninguna partición está en blanco, los nuevos consumidores deben esperar.
2 herramientas importantes en Apache Kafka
A continuación, en este tutorial de Apache Kafka , analizaremos las herramientas de Kafka empaquetadas en “org.apache.kafka.tools.*.
1. Herramientas de replicación
Es una herramienta de diseño de alto nivel que imparte mayor disponibilidad y mayor durabilidad.
- Herramienta Crear tema: esta herramienta se utiliza para crear un tema con un factor de replicación y un número predeterminado de particiones y utiliza el esquema predeterminado de Kafka para realizar una asignación de réplica.
- Herramienta de lista de temas: esta herramienta enumera la información de una lista determinada de temas. Esta herramienta muestra campos como la partición, el nombre del tema, el líder, las réplicas y el isr.
- Herramienta Agregar partición: esta herramienta puede agregar más particiones para un tema en particular. También realiza la asignación manual de réplicas de las particiones añadidas.
2. Herramientas del sistema
El script de clase de ejecución se puede usar para ejecutar herramientas del sistema en Kafka. La sintaxis es:
- Mirror Maker: el uso de esta herramienta es reflejar un clúster de Kafka en otro.
- Herramienta de migración de Kafka: esta herramienta ayuda a migrar un agente de Kafka de una versión a otra.
- Comprobador de compensación del consumidor: esta herramienta muestra el tema de Kafka, el tamaño del registro, la compensación, las particiones, el grupo de consumidores y el propietario para el conjunto particular de temas.
Lea también: Tutorial de Apache Pig

Los 4 mejores casos de uso de Apache Kafka
Analicemos algunos casos de uso importantes de Apache Kafka en este tutorial de Apache Kafka:
- Procesamiento de flujo: la característica de gran durabilidad de Kafka permite su uso en el campo del procesamiento de flujo. En este caso, los datos se leen de un tema, se procesan y luego los datos procesados se escriben en un nuevo tema para que estén disponibles para las aplicaciones y los usuarios.
- Métricas: Kafka se usa con frecuencia para el monitoreo operativo de datos. Las estadísticas se agregan desde aplicaciones distribuidas para crear una fuente centralizada de datos operativos.
- Seguimiento de la actividad del sitio web: los almacenes de datos como BigQuery y Google emplean Kafka para el seguimiento de las actividades en los sitios web. Las actividades del sitio, como búsquedas, vistas de páginas u otras acciones de los usuarios, se publican en temas centrales y se vuelven accesibles para procesamiento en tiempo real, análisis fuera de línea y paneles.
- Agregación de registros: con Kafka, los registros se pueden recopilar de muchos servicios y estar disponibles en un formato estandarizado para muchos consumidores.
Las 5 mejores aplicaciones de Apache Kafka
Algunas de las mejores aplicaciones industriales compatibles con Kafka incluyen:
- Uber: la aplicación de cabina necesita un inmenso procesamiento en tiempo real y maneja un gran volumen de datos. Los procesos importantes como la auditoría, los cálculos de ETA y la coincidencia de conductores y clientes se modelan en base a Kafka Streams.
- Netflix: la plataforma de transmisión por Internet a pedido Netflix utiliza métricas de Kafka para el procesamiento de eventos y el monitoreo en tiempo real.
- LinkedIn: LinkedIn gestiona 7 billones de mensajes cada día, con 100.000 temas, 7 millones de particiones y más de 4000 intermediarios. Apache Kafka se utiliza en LinkedIn para el seguimiento, la supervisión y el seguimiento de la actividad de los usuarios.
- Tinder: esta popular aplicación de citas utiliza Kafka Streams para varios procesos que incluyen moderación de contenido, recomendaciones, actualización de la zona horaria del usuario, notificaciones y activación del usuario, entre otros.
- Pinterest: con una búsqueda mensual de miles de millones de pines e ideas, Pinterest ha aprovechado Kafka para muchos procesos. Kafka Streams se utiliza para indexar contenidos, detectar spam, recomendaciones y calcular presupuestos de anuncios en tiempo real.
Conclusión
En este Tutorial de Apache Kafka , hemos discutido los conceptos fundamentales de Apache Kafka, la arquitectura y el clúster en Kafka, el flujo de trabajo de Kafka, las herramientas de Kafka y algunas aplicaciones de Kafka. Apache Kafka tiene algunas de las mejores características como durabilidad, escalabilidad, tolerancia a fallas, confiabilidad, extensibilidad, replicación y alto rendimiento que lo hacen accesible en algunas de las mejores aplicaciones industriales, como se ejemplifica en este tutorial de Apache Kafka .
Si está interesado en saber más sobre Big Data, consulte nuestro programa PG Diploma in Software Development Specialization in Big Data, que está diseñado para profesionales que trabajan y proporciona más de 7 estudios de casos y proyectos, cubre 14 lenguajes y herramientas de programación, prácticas talleres, más de 400 horas de aprendizaje riguroso y asistencia para la colocación laboral con las mejores empresas.
Aprenda cursos de desarrollo de software en línea de las mejores universidades del mundo. Obtenga Programas PG Ejecutivos, Programas de Certificado Avanzado o Programas de Maestría para acelerar su carrera.