
Apache Kafka Tutorial: Einführung, Konzepte, Workflow, Tools, Anwendungen
Veröffentlicht: 2020-03-10Inhaltsverzeichnis
Einführung
Mit der zunehmenden Popularität von Kafka als Messaging-System verlangen viele Unternehmen Fachleute mit fundierten Kafka-Kenntnissen, und hier ist ein Apache Kafka-Tutorial hilfreich. Im Bereich Big Data werden enorme Datenmengen verwendet, die ein Messaging-System zur Datenerfassung und -analyse benötigen.
Kafka ist ein effizienter Ersatz für den herkömmlichen Message Broker mit verbessertem Durchsatz, inhärenter Partitionierung und Replikation sowie integrierter Fehlertoleranz, wodurch es für Anwendungen zur Nachrichtenverarbeitung in großem Maßstab geeignet ist. Wenn Sie nach einem Apache Kafka-Tutorial gesucht haben , ist dies der richtige Artikel für Sie.
Wichtige Erkenntnisse aus diesem Apache Kafka-Tutorial
- Konzept von Messaging-Systemen
- Eine kurze Einführung in Apache Kafka
- Konzepte in Bezug auf Kafka-Cluster und Kafka-Architektur
- Kurze Beschreibung des Messaging-Workflows von Kafka
- Überblick über wichtige Kafka-Werkzeuge
- Anwendungsfälle und Anwendungen von Apache Kafka
Erfahren Sie auch mehr über: Apache Spark Streaming Tutorial For Beginners
Ein kurzer Überblick über Messaging-Systeme
Die Hauptfunktion eines Messaging-Systems besteht darin, die Datenübertragung von einer Anwendung zu einer anderen zu ermöglichen; Das System stellt sicher, dass sich die Anwendungen nur auf die Daten konzentrieren, ohne während des Prozesses der gemeinsamen Nutzung und Übertragung von Daten ins Stocken zu geraten. Es gibt zwei Arten von Nachrichtensystemen:
1. Point-to-Point-Messaging-System
In diesem System werden die Erzeuger der Nachrichten als Sender und diejenigen, die die Nachrichten konsumieren, als Empfänger bezeichnet. In dieser Domäne werden die Nachrichten über ein als Queue bezeichnetes Ziel ausgetauscht; die Sender oder Produzenten produzieren die Nachrichten für die Warteschlange, und die Nachrichten werden von den Empfängern aus der Warteschlange konsumiert.

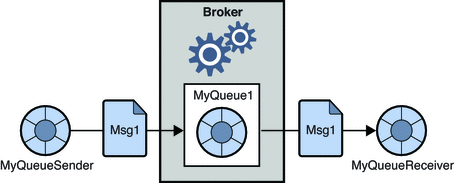
Quelle
2. Publish-Subscribe-Messaging-System
In diesem System werden die Produzenten der Nachrichten Herausgeber genannt und diejenigen, die die Nachrichten konsumieren, Abonnenten. In dieser Domäne werden die Nachrichten jedoch über ein als Thema bekanntes Ziel ausgetauscht. Ein Herausgeber erzeugt die Nachrichten zu einem Thema, und nachdem er ein Thema abonniert hat, konsumieren die Abonnenten die Nachrichten von dem Thema. Dieses System ermöglicht das Rundsenden von Nachrichten (mit mehr als einem Abonnenten und jeder erhält eine Kopie der zu einem bestimmten Thema veröffentlichten Nachrichten).
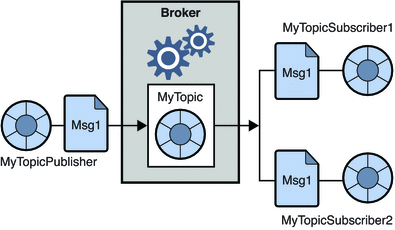
Quelle
Apache Kafka – eine Einführung
Apache Kafka basiert auf einem Publish-Subscribe (Pub-Sub) Messaging-System. Im Pub-Sub-Messaging-System sind Herausgeber die Produzenten der Nachrichten und Abonnenten die Konsumenten der Nachrichten. In diesem System können die Verbraucher alle Nachrichten der abonnierten Themen konsumieren. Dieses Prinzip des Pub-Sub-Nachrichtensystems wird in Apache Kafka verwendet.
Darüber hinaus verwendet Apache Kafka das Konzept des verteilten Messaging, bei dem Nachrichten zwischen dem Messaging-System und den Anwendungen nicht synchron in die Warteschlange gestellt werden. Mit einer robusten Warteschlange, die große Datenmengen verarbeiten kann, ermöglicht Ihnen Kafka die Übertragung von Nachrichten von einem Endpunkt zum anderen und eignet sich sowohl für den Online- als auch für den Offline-Verbrauch von Nachrichten. Durch die Kombination von Zuverlässigkeit, Skalierbarkeit, Langlebigkeit und hoher Durchsatzleistung ist Apache Kafka ideal für die Integration und Kommunikation zwischen Einheiten großer Datensysteme in der realen Welt.
Lesen Sie auch: Big-Data-Projektideen
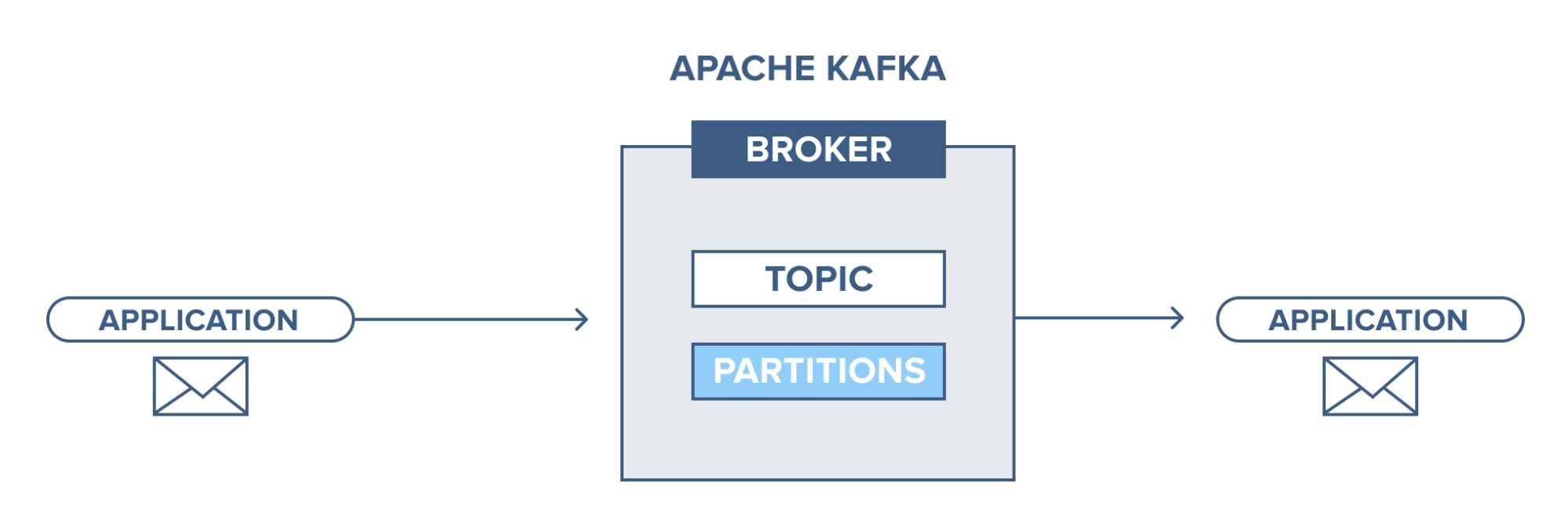
Quelle
Konzept von Apache Kafka-Clustern
Quelle
- Kafka Tierpfleger : Die Makler in einem Cluster werden von Tierpflegern koordiniert und verwaltet. Zookeeper benachrichtigt Produzenten und Verbraucher über das Vorhandensein eines neuen Maklers oder den Ausfall eines Maklers im Kafka-System sowie über den Ausgleichswert. Erzeuger und Verbraucher koordinieren ihre Aktivitäten mit einem anderen Makler, wenn sie vom Tierpfleger empfangen werden.
- Kafka-Broker: Kafka-Broker sind Systeme, die für die Pflege der veröffentlichten Daten in Kafka-Clustern mit Hilfe von Tierpflegern verantwortlich sind. Ein Broker kann null oder mehr Partitionen für jedes Thema haben.
- Kafka-Produzent: Die Nachrichten zu einem oder mehreren Kafka-Themen werden vom Produzenten veröffentlicht und an Broker weitergeleitet, ohne auf die Bestätigung des Brokers zu warten.
- Kafka-Verbraucher: Verbraucher extrahieren Daten von den Brokern und verbrauchen bereits veröffentlichte Nachrichten von einem oder mehreren Themen, senden eine nicht synchrone Pull-Anfrage an den Broker, um einen verbrauchsbereiten Byte-Puffer zu haben, und liefern dann einen Offset-Wert zum Zurückspulen oder Springen irgendein Partitionspunkt.
Grundbegriffe der Kafka-Architektur
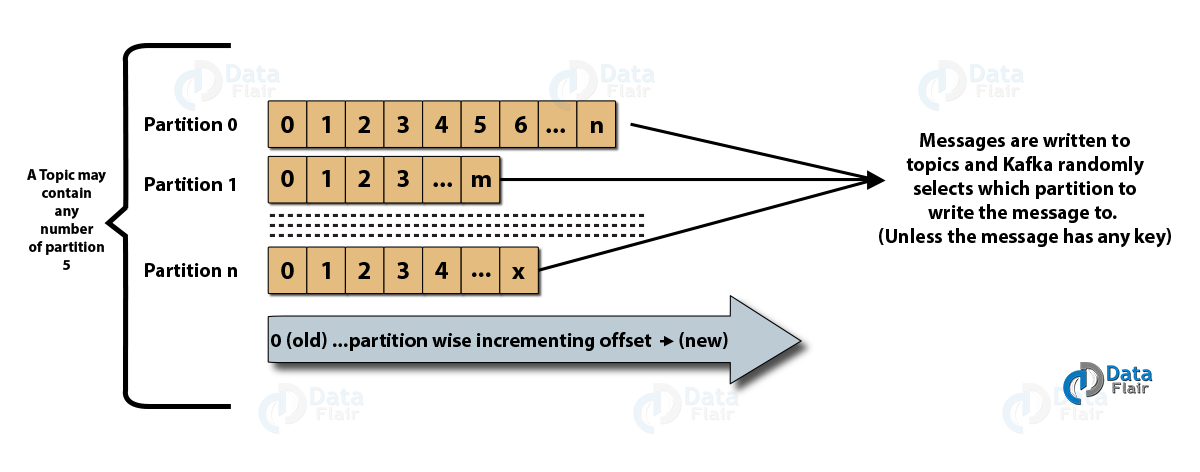
- Themen : Es ist ein logischer Kanal, auf dem Nachrichten von Erzeugern veröffentlicht werden und von dem Nachrichten von Verbrauchern empfangen werden. Themen können sowohl repliziert (kopiert) als auch partitioniert (geteilt) werden. Eine bestimmte Art von Nachricht wird zu einem bestimmten Thema veröffentlicht, wobei jedes Thema durch seinen eindeutigen Namen identifizierbar ist.
- Themenpartitionen: Im Kafka-Cluster werden Themen in Partitionen unterteilt und über Broker hinweg repliziert. Ein Erzeuger kann einer veröffentlichten Nachricht einen Schlüssel hinzufügen, und Nachrichten mit demselben Schlüssel landen in derselben Partition. Jeder Nachricht in einer Partition wird eine inkrementelle ID namens Offset zugewiesen, und diese IDs sind nur innerhalb der Partition gültig und haben keinen Wert über Partitionen in einem Thema hinweg.
- Leader und Replica: Jeder Kafka-Broker hat einige Partitionen, wobei jede Partition entweder ein Leader oder eine Replica (Backup) des Themas ist. Der Leiter ist nicht nur dafür verantwortlich, ein Thema zu lesen und zu schreiben, sondern auch die Replikate mit neuen Daten zu aktualisieren. Wenn der Leader in jedem Fall ausfällt, kann das Replikat den neuen Leader übernehmen.
Architektur von Apache Kafka
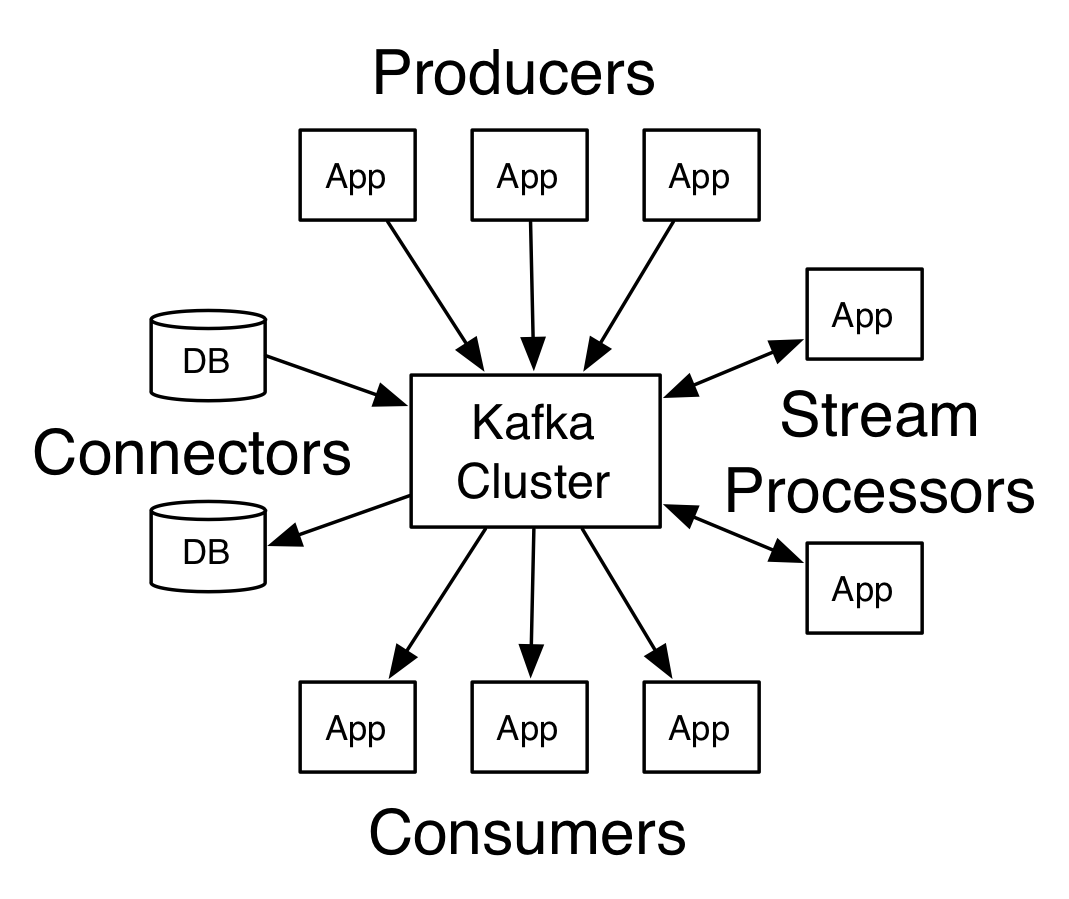
Quelle
Ein Kafka mit mehr als einem Broker wird als Kafka-Cluster bezeichnet. Vier der Kern-APIs werden in diesem Apache Kafka-Tutorial besprochen :
- Producer-API: Die Kafka-Producer-API ermöglicht die Veröffentlichung eines Streams von Datensätzen durch eine Anwendung zu einem oder mehreren Kafka-Themen.
- Verbraucher-API: Die Verbraucher-API ermöglicht es einer Anwendung, den kontinuierlichen Strom von Datensätzen zu verarbeiten, die zu einem oder mehreren Themen erstellt wurden.
- Streams-API: Die Streams-API ermöglicht es einer Anwendung, einen Eingabestream von einem oder mehreren Themen zu konsumieren und einen Ausgabestream zu einem oder mehreren Ausgabethemen zu generieren, wodurch es der Anwendung ermöglicht wird, als Stream-Prozessor zu fungieren. Dies modifiziert die Eingabeströme effizient in die Ausgabeströme.
- Konnektor-API: Die Konnektor-API ermöglicht das Erstellen und Ausführen von wiederverwendbaren Produzenten und Konsumenten und ermöglicht so eine Verbindung zwischen Kafka-Themen und bestehenden Datensystemen oder Anwendungen.
Workflow der Publisher-Subscriber-Messaging-Domäne
- Kafka-Produzenten senden in regelmäßigen Abständen Nachrichten zu einem Thema.
- Kafka-Broker stellen eine gleichmäßige Verteilung von Nachrichten innerhalb der Partitionen sicher, indem sie sie in den für ein bestimmtes Thema konfigurierten Partitionen speichern.
- Das Abonnieren eines bestimmten Themas erfolgt durch Kafka-Konsumenten. Sobald der Verbraucher ein Thema abonniert hat, wird dem Verbraucher der aktuelle Versatz des Themas angeboten, und das Thema wird in dem Tierpfleger-Ensemble gespeichert.
- Der Konsument fordert Kafka in regelmäßigen Abständen nach neuen Nachrichten an.
- Kafka leitet die Nachrichten sofort nach Erhalt von den Produzenten an die Verbraucher weiter.
- Der Consumer empfängt die Nachricht und verarbeitet sie.
- Der Kafka-Broker erhält eine Bestätigung, sobald die Nachricht verarbeitet wurde.
- Beim Empfang der Quittung wird der Offset auf den neuen Wert hochgestuft.
- Der Ablauf wiederholt sich, bis der Verbraucher die Anforderung stoppt.
- Der Verbraucher kann jederzeit einen Versatz überspringen oder zurückspulen und nachfolgende Nachrichten nach Belieben lesen.
Workflow des Warteschlangen-Messaging-Systems
In einem Queue-Messaging-System können mehrere Verbraucher mit derselben Gruppen-ID ein Thema abonnieren. Sie werden als eine einzige Gruppe betrachtet und teilen die Nachrichten. Der Workflow des Systems ist:

- Kafka-Produzenten senden in regelmäßigen Abständen Nachrichten zu einem Thema.
- Kafka-Broker stellen eine gleichmäßige Verteilung von Nachrichten innerhalb der Partitionen sicher, indem sie sie in den für ein bestimmtes Thema konfigurierten Partitionen speichern.
- Ein einzelner Verbraucher abonniert ein bestimmtes Thema.
- Bis ein neuer Verbraucher dasselbe Thema abonniert, interagiert Kafka mit dem einzelnen Verbraucher.
- Mit der Ankunft der neuen Verbraucher werden die Daten zwischen zwei Verbrauchern geteilt. Die gemeinsame Nutzung wird wiederholt, bis die Anzahl der konfigurierten Partitionen für dieses Thema gleich der Anzahl der Verbraucher ist.
- Ein neuer Verbraucher erhält keine weiteren Nachrichten, wenn die Anzahl der Verbraucher die Anzahl der konfigurierten Partitionen überschreitet. Diese Situation ergibt sich aufgrund der Bedingung, dass jeder Verbraucher Anspruch auf mindestens eine Partition hat, und wenn keine Partition leer ist, müssen die neuen Verbraucher warten.
2 wichtige Tools in Apache Kafka
Als Nächstes werden wir in diesem Apache Kafka-Tutorial Kafka-Tools besprechen, die unter „org.apache.kafka.tools.*“ verpackt sind.
1. Replikationstools
Es ist ein High-Level-Design-Tool, das eine höhere Verfügbarkeit und mehr Haltbarkeit verleiht.
- Tool zum Erstellen von Themen: Dieses Tool wird verwendet, um ein Thema mit einem Replikationsfaktor und einer Standardanzahl von Partitionen zu erstellen, und verwendet das Standardschema von Kafka, um eine Replikatzuweisung durchzuführen.
- Listen-Themen-Tool: Die Informationen für eine gegebene Liste von Themen werden von diesem Tool aufgelistet. Felder wie Partition, Themenname, Leader, Replicas und ISR werden von diesem Tool angezeigt.
- Tool „Partition hinzufügen“: Mit diesem Tool können weitere Partitionen für ein bestimmtes Thema hinzugefügt werden. Es führt auch eine manuelle Zuweisung von Reproduktionen der hinzugefügten Partitionen durch.
2. Systemwerkzeuge
Das Klassenskript run kann verwendet werden, um Systemtools in Kafka auszuführen. Die Syntax lautet:
- Mirror Maker: Die Verwendung dieses Tools besteht darin, einen Kafka-Cluster auf einen anderen zu spiegeln.
- Kafka-Migrationstool: Dieses Tool hilft bei der Migration eines Kafka-Brokers von einer Version zu einer anderen.
- Consumer Offset Checker: Dieses Tool zeigt Kafka-Thema, Protokollgröße, Offset, Partitionen, Verbrauchergruppe und Eigentümer für die jeweilige Themengruppe an.
Lesen Sie auch: Apache Pig Tutorial

Die 4 wichtigsten Anwendungsfälle von Apache Kafka
Lassen Sie uns in diesem Apache Kafka-Tutorial einige wichtige Anwendungsfälle von Apache Kafka besprechen:
- Stream-Verarbeitung: Das Merkmal der starken Haltbarkeit von Kafka ermöglicht den Einsatz im Bereich der Stream-Verarbeitung. Dabei werden Daten aus einem Topic gelesen, verarbeitet und die verarbeiteten Daten anschließend in ein neues Topic geschrieben, um es Anwendungen und Benutzern zur Verfügung zu stellen.
- Metriken: Kafka wird häufig für die operative Überwachung von Daten verwendet. Statistiken werden aus verteilten Anwendungen aggregiert, um einen zentralisierten Feed mit Betriebsdaten zu erstellen.
- Verfolgung von Website-Aktivitäten: Data Warehouses wie BigQuery und Google verwenden Kafka zur Verfolgung von Aktivitäten auf Websites. Site-Aktivitäten wie Suchen, Seitenaufrufe oder andere Benutzeraktionen werden zu zentralen Themen veröffentlicht und für Echtzeitverarbeitung, Offline-Analyse und Dashboards zugänglich gemacht.
- Protokollaggregation: Mit Kafka können Protokolle von vielen Diensten gesammelt und vielen Verbrauchern in einem standardisierten Format zur Verfügung gestellt werden.
Top 5 Anwendungen von Apache Kafka
Einige der besten von Kafka unterstützten industriellen Anwendungen sind:
- Uber: Die Taxi-App benötigt eine immense Echtzeitverarbeitung und verarbeitet ein riesiges Datenvolumen. Wichtige Prozesse wie Auditing, ETA-Berechnungen und Fahrer- und Kundenabgleich werden auf Basis von Kafka Streams modelliert.
- Netflix: Die On-Demand-Internet-Streaming-Plattform Netflix verwendet Kafka-Metriken für die Verarbeitung von Ereignissen und die Echtzeitüberwachung.
- LinkedIn: LinkedIn verwaltet täglich 7 Billionen Nachrichten mit 100.000 Themen, 7 Millionen Partitionen und über 4000 Brokern. Apache Kafka wird in LinkedIn für die Verfolgung, Überwachung und Nachverfolgung von Benutzeraktivitäten verwendet.
- Tinder: Diese beliebte Dating-App verwendet Kafka Streams für verschiedene Prozesse, darunter unter anderem Inhaltsmoderation, Empfehlungen, Aktualisierung der Benutzerzeitzone, Benachrichtigungen und Benutzeraktivierung.
- Pinterest: Mit einer monatlichen Suche nach Milliarden von Pins und Ideen hat Pinterest Kafka für viele Prozesse genutzt. Kafka Streams werden zur Indizierung von Inhalten, Erkennung von Spam, Empfehlungen und zur Berechnung von Budgets für Echtzeit-Anzeigen verwendet.
Fazit
In diesem Apache Kafka-Tutorial haben wir die grundlegenden Konzepte von Apache Kafka, Architektur und Cluster in Kafka, Kafka-Workflow, Kafka-Tools und einige Anwendungen von Kafka besprochen. Apache Kafka verfügt über einige der besten Funktionen wie Haltbarkeit, Skalierbarkeit, Fehlertoleranz, Zuverlässigkeit, Erweiterbarkeit, Replikation und hohen Durchsatz, die es für einige der besten industriellen Anwendungen zugänglich machen, wie in diesem Apache Kafka-Tutorial veranschaulicht .
Wenn Sie mehr über Big Data erfahren möchten, schauen Sie sich unser PG Diploma in Software Development Specialization in Big Data-Programm an, das für Berufstätige konzipiert ist und mehr als 7 Fallstudien und Projekte bietet, 14 Programmiersprachen und Tools abdeckt und praktische praktische Übungen enthält Workshops, mehr als 400 Stunden gründliches Lernen und Unterstützung bei der Stellenvermittlung bei Top-Unternehmen.
Lernen Sie Softwareentwicklungskurse online von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.