
Apache Kafkaチュートリアル:はじめに、概念、ワークフロー、ツール、アプリケーション
公開: 2020-03-10目次
序章
メッセージングシステムとしてのKafkaの人気が高まるにつれ、多くの企業がKafkaスキルの十分な知識を持つ専門家を求めています。そこで、 ApacheKafkaチュートリアルが役立ちます。 ビッグデータの領域では、データの収集と分析にメッセージングシステムを必要とする膨大な量のデータが使用されています。
Kafkaは、スループットの向上、固有のパーティショニングとレプリケーション、および組み込みのフォールトトレランスを備えた従来のメッセージブローカーの効率的な代替品であり、大規模なメッセージ処理アプリケーションに適しています。 Apache Kafkaチュートリアルを探しているなら、これはあなたにぴったりの記事です。
このApacheKafkaチュートリアルの重要なポイント
- メッセージングシステムの概念
- ApacheKafkaの簡単な紹介
- KafkaクラスターとKafkaアーキテクチャに関連する概念
- Kafkaメッセージングワークフローの簡単な説明
- 重要なKafkaツールの概要
- ApacheKafkaのユースケースとアプリケーション
初心者向けのApacheSparkストリーミングチュートリアルもご覧ください。
メッセージングシステムの概要
メッセージングシステムの主な機能は、あるアプリケーションから別のアプリケーションへのデータ転送を可能にすることです。 システムは、アプリケーションがデータの共有と送信のプロセス中に停止することなく、データのみに集中することを保証します。 メッセージングシステムには次の2種類があります。
1.ポイントツーポイントメッセージングシステム
このシステムでは、メッセージのプロデューサーは送信者と呼ばれ、メッセージを消費するのは受信者です。 このドメインでは、メッセージはキューと呼ばれる宛先を介して交換されます。 送信者またはプロデューサーはキューへのメッセージを生成し、メッセージはキューからの受信者によって消費されます。

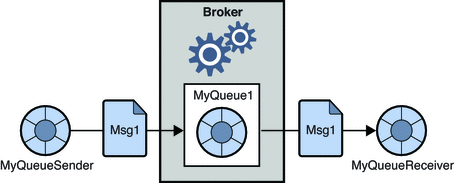
ソース
2.パブリッシュ/サブスクライブメッセージングシステム
このシステムでは、メッセージのプロデューサーはパブリッシャーと呼ばれ、メッセージを消費するのはサブスクライバーです。 ただし、このドメインでは、メッセージはトピックと呼ばれる宛先を介して交換されます。 パブリッシャーはトピックへのメッセージを作成し、トピックをサブスクライブすると、サブスクライバーはトピックからのメッセージを消費します。 このシステムでは、メッセージのブロードキャストが可能です(複数のサブスクライバーがいて、それぞれが特定のトピックに公開されたメッセージのコピーを取得します)。
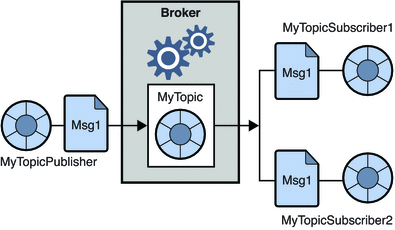
ソース
Apache Kafka –はじめに
Apache Kafkaは、パブリッシュ/サブスクライブ(pub-sub)メッセージングシステムに基づいています。 pub-subメッセージングシステムでは、パブリッシャーはメッセージのプロデューサーであり、サブスクライバーはメッセージのコンシューマーです。 このシステムでは、コンシューマーはサブスクライブされたトピックのすべてのメッセージを消費できます。pub-subメッセージングシステムのこの原則は、ApacheKafkaで採用されています。
さらに、Apache Kafkaは分散メッセージングの概念を使用します。これにより、メッセージングシステムとアプリケーションの間でメッセージの非同期キューイングが行われます。 大量のデータを処理できる堅牢なキューを備えたKafkaを使用すると、あるエンドポイントから別のエンドポイントにメッセージを送信でき、メッセージのオンラインとオフラインの両方の消費に適しています。 Apache Kafkaは、信頼性、スケーラビリティ、耐久性、および高スループットパフォーマンスを組み合わせることで、実世界の大規模データシステムのユニット間の統合と通信に理想的です。
また読む:ビッグデータプロジェクトのアイデア
ソース
ApacheKafkaクラスターの概念
ソース
- Kafka動物園の飼育係:クラスター内のブローカーは、飼育係によって調整および管理されます。 Zookeeperは、Kafkaシステムでの新しいブローカーの存在またはブローカーの障害についてプロデューサーとコンシューマーに通知し、オフセット値についてコンシューマーに通知します。 生産者と消費者は、動物園の飼育係から受け取る際に、別のブローカーと活動を調整します。
- Kafkaブローカー: Kafkaブローカーは、動物園の飼育係の助けを借りて、Kafkaクラスターで公開されたデータを維持する責任があるシステムです。 ブローカーは、トピックごとに0個以上のパーティションを持つ場合があります。
- Kafkaプロデューサー: 1つまたは複数のKafkaトピックに関するメッセージは、ブローカーの承認を待たずに、プロデューサーによって公開され、ブローカーにプッシュされます。
- Kafkaコンシューマー:コンシューマーはブローカーからデータを抽出し、1つ以上のトピックから既に公開されたメッセージを消費し、ブローカーに非同期プルリクエストを発行してバイトのバッファーを消費できるようにし、オフセット値を提供して巻き戻しまたはスキップします任意のパーティションポイント。
Kafkaアーキテクチャの基本的な概念
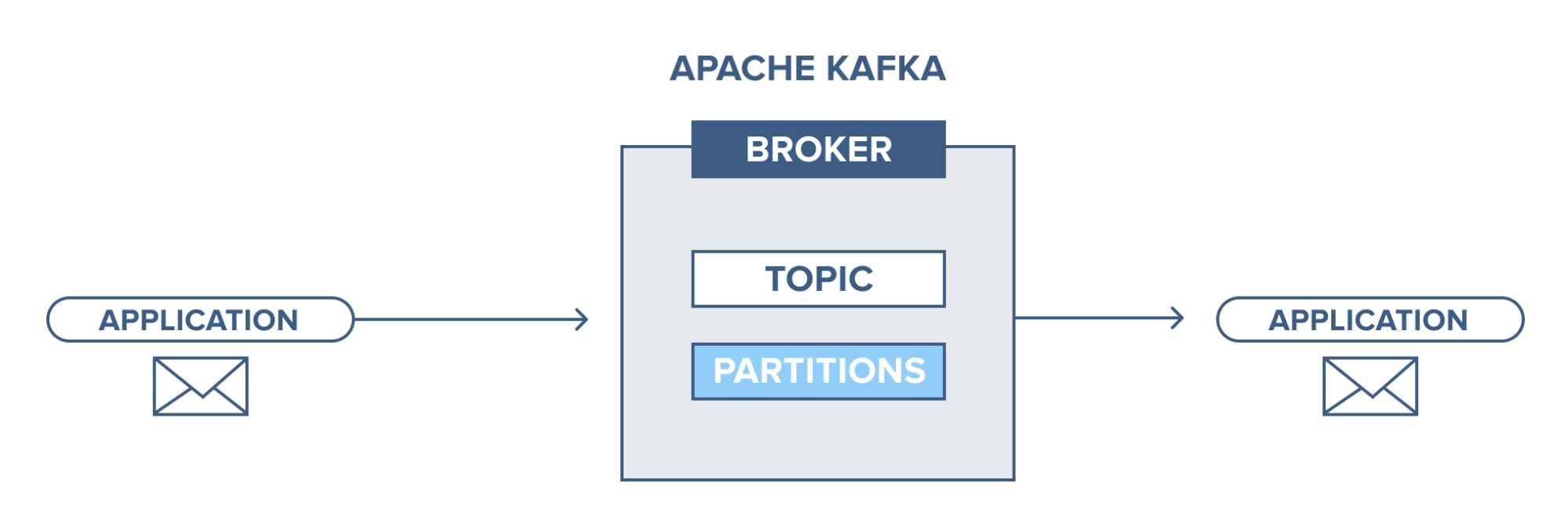
- トピック:これは、メッセージがプロデューサーによって公開され、そこからメッセージがコンシューマーによって受信される論理チャネルです。 トピックは、複製(コピー)およびパーティション化(分割)できます。 特定の種類のメッセージが特定のトピックで公開され、各トピックは一意の名前で識別できます。
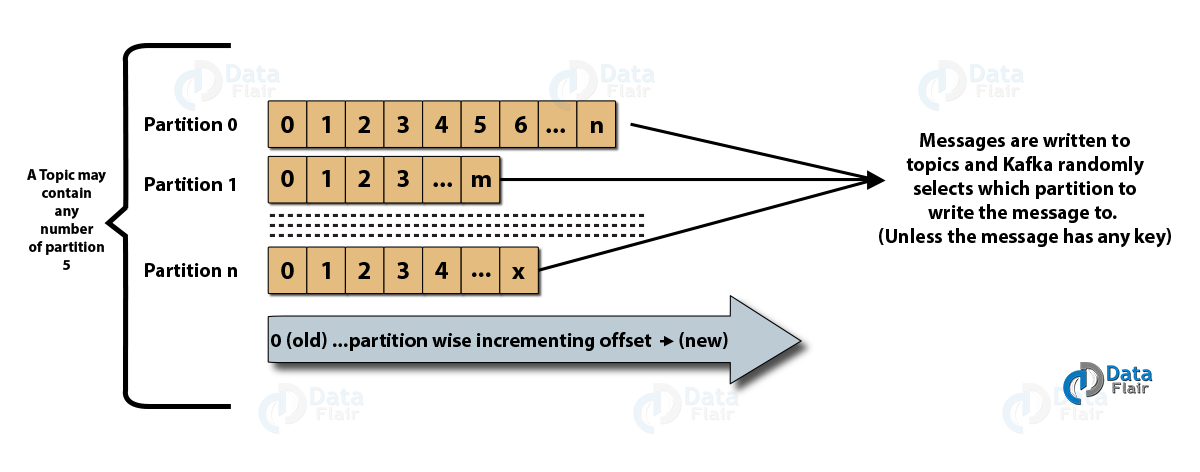
- トピックパーティション: Kafkaクラスターでは、トピックはパーティションに分割されるだけでなく、ブローカー間で複製されます。 プロデューサーは公開されたメッセージにキーを追加でき、同じキーを持つメッセージは同じパーティションに配置されます。 オフセットと呼ばれる増分IDがパーティション内の各メッセージに割り当てられ、これらのIDはパーティション内でのみ有効であり、トピック内のパーティション間で値を持ちません。
- リーダーとレプリカ:すべてのKafkaブローカーには、トピックのリーダーまたはレプリカ(バックアップ)のいずれかである、各パーティションを持ついくつかのパーティションがあります。 リーダーは、トピックの読み取りと書き込みだけでなく、レプリカを新しいデータで更新する責任があります。 いずれにせよ、リーダーが失敗した場合、レプリカが新しいリーダーとして引き継ぐことができます。
ApacheKafkaのアーキテクチャ
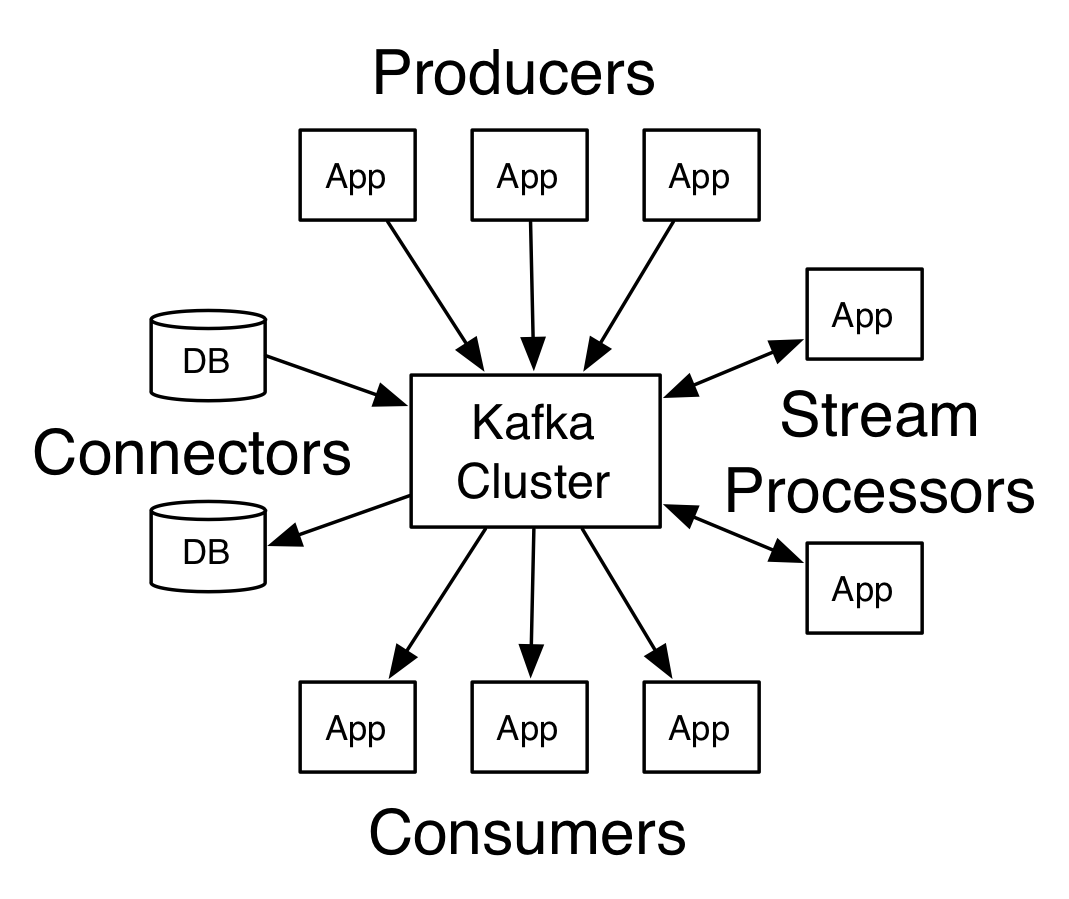
ソース

複数のブローカーを持つKafkaは、Kafkaクラスターと呼ばれます。 このApacheKafkaチュートリアルでは、4つのコアAPIについて説明します。
- プロデューサーAPI: KafkaプロデューサーAPIを使用すると、アプリケーションによって1つまたは複数のKafkaトピックにレコードのストリームを公開できます。
- コンシューマーAPI:コンシューマーAPIを使用すると、アプリケーションは1つ以上のトピックに対して生成されたレコードの継続的なフローを処理できます。
- Streams API:Streams APIを使用すると、アプリケーションは1つまたは複数のトピックからの入力ストリームを消費し、1つまたは複数の出力トピックへの出力ストリームを生成できます。これにより、アプリケーションはストリームプロセッサとして機能できます。 これにより、入力ストリームが出力ストリームに効率的に変更されます。
- コネクタAPI:コネクタAPIを使用すると、再利用可能なプロデューサーとコンシューマーを作成して実行できるため、Kafkaトピックと既存のデータシステムまたはアプリケーション間の接続が可能になります。
パブリッシャー/サブスクライバーメッセージングドメインのワークフロー
- Kafkaプロデューサーは、定期的にトピックにメッセージを送信します。
- Kafkaブローカーは、特定のトピック用に構成されたパーティションにメッセージを格納することにより、パーティション内でメッセージが均等に分散されるようにします。
- 特定のトピックのサブスクライブは、Kafkaの消費者によって行われます。 コンシューマーがトピックをサブスクライブすると、トピックの現在のオフセットがコンシューマーに提供され、トピックはzookeeperアンサンブルに保存されます。
- 消費者は、定期的に新しいメッセージをKafkaに要求します。
- Kafkaは、プロデューサーからの受信後すぐにメッセージを消費者に転送します。
- コンシューマーはメッセージを受信して処理します。
- Kafkaブローカーは、メッセージが処理されるとすぐに確認応答を受け取ります。
- 確認応答を受信すると、オフセットは新しい値にアップグレードされます。
- コンシューマーが要求を停止するまで、フローが繰り返されます。
- 消費者はいつでもオフセットをスキップまたは巻き戻し、都合に合わせて後続のメッセージを読むことができます。
キューメッセージングシステムのワークフロー
キューメッセージングシステムでは、同じグループIDを持つ複数のコンシューマーがトピックをサブスクライブできます。 それらは単一のグループと見なされ、メッセージを共有します。 システムのワークフローは次のとおりです。
- Kafkaプロデューサーは、定期的にトピックにメッセージを送信します。
- Kafkaブローカーは、特定のトピック用に構成されたパーティションにメッセージを格納することにより、パーティション内でメッセージが均等に分散されるようにします。
- 単一の消費者が特定のトピックにサブスクライブします。
- 新しい消費者が同じトピックをサブスクライブするまで、Kafkaは単一の消費者と対話します。
- 新しい消費者の到着とともに、データは2人の消費者間で共有されます。 そのトピックに構成されたパーティションの数がコンシューマーの数と等しくなるまで、共有が繰り返されます。
- コンシューマーの数が構成済みのパーティションの数を超えると、新しいコンシューマーはそれ以上メッセージを受信しません。 この状況は、各コンシューマーに少なくとも1つのパーティションの資格があるという条件が原因で発生し、ブランクのパーティションがない場合、新しいコンシューマーは待機する必要があります。
ApacheKafkaの2つの重要なツール
次に、このApache Kafkaチュートリアルでは、 「org.apache.kafka.tools。*」にパッケージ化されているKafkaツールについて説明します。
1.レプリケーションツール
これは、より高い可用性とより高い耐久性を与える高レベルの設計ツールです。
- トピックの作成ツール:このツールは、レプリケーションファクターとデフォルトのパーティション数でトピックを作成するために使用され、Kafkaのデフォルトのスキームを使用してレプリカの割り当てを実行します。
- リストトピックツール:特定のトピックリストの情報は、このツールによって一覧表示されます。 このツールでは、パーティション、トピック名、リーダー、レプリカ、isrなどのフィールドが表示されます。
- パーティションの追加ツール:このツールを使用すると、特定のトピックのパーティションをさらに追加できます。 また、追加されたパーティションのレプリカの手動割り当ても実行します。
2.システムツール
run classスクリプトを使用して、Kafkaでシステムツールを実行できます。 構文は次のとおりです。
- ミラーメーカー:このツールの使用は、あるKafkaクラスターを別のクラスターにミラーリングすることです。
- Kafka移行ツール:このツールは、Kafkaブローカーをあるバージョンから別のバージョンに移行するのに役立ちます。
- コンシューマーオフセットチェッカー:このツールは、特定のトピックセットのKafkaトピック、ログサイズ、オフセット、パーティション、コンシューマーグループ、および所有者を表示します。
また読む: ApachePigチュートリアル

ApacheKafkaのトップ4のユースケース
このApacheKafkaチュートリアルでは、ApacheKafkaのいくつかの重要なユースケースについて説明します。
- ストリーム処理: Kafkaの強力な耐久性の特徴により、ストリーム処理の分野で使用できます。 この場合、データはトピックから読み取られて処理され、処理されたデータは新しいトピックに書き込まれて、アプリケーションとユーザーが利用できるようになります。
- 指標: Kafkaは、データの運用監視に頻繁に使用されます。 統計は分散アプリケーションから集約され、運用データの集中フィードを作成します。
- ウェブサイトのアクティビティの追跡: BigQueryやGoogleなどのデータウェアハウスは、ウェブサイトのアクティビティの追跡にKafkaを採用しています。 検索、ページビュー、その他のユーザーアクションなどのサイトアクティビティは、中央のトピックに公開され、リアルタイム処理、オフライン分析、ダッシュボードにアクセスできるようになります。
- ログの集約: Kafkaを使用すると、ログを多くのサービスから収集し、標準化された形式で多くの消費者が利用できるようにすることができます。
ApacheKafkaのトップ5アプリケーション
Kafkaがサポートする最高の産業用アプリケーションには次のものがあります。
- Uber: cabアプリは、膨大なリアルタイム処理を必要とし、膨大なデータ量を処理します。 監査、ETA計算、ドライバーと顧客のマッチングなどの重要なプロセスは、KafkaStreamsに基づいてモデル化されています。
- Netflix:オンデマンドインターネットストリーミングプラットフォームNetflixは、イベントの処理とリアルタイムの監視にKafkaメトリックを使用します。
- LinkedIn: LinkedInは、毎日7兆のメッセージを管理しており、10万のトピック、700万のパーティション、4000を超えるブローカーがあります。 Apache Kafkaは、LinkedInでユーザーアクティビティの追跡、監視、追跡に使用されます。
- Tinder:この人気のある出会い系アプリは、コンテンツのモデレーション、推奨事項、ユーザーのタイムゾーンの更新、通知、ユーザーのアクティブ化など、いくつかのプロセスにKafkaStreamsを使用します。
- Pinterest:毎月数十億のピンやアイデアを検索し、Pinterestは多くのプロセスでKafkaを活用してきました。 Kafka Streamsは、コンテンツのインデックス作成、スパムの検出、推奨、およびリアルタイム広告の予算の計算に使用されます。
結論
このApacheKafkaチュートリアルでは、Apache Kafkaの基本概念、Kafkaのアーキテクチャとクラスター、Kafkaワークフロー、Kafkaツール、およびKafkaのいくつかのアプリケーションについて説明しました。 Apache Kafkaには、耐久性、スケーラビリティ、フォールトトレランス、信頼性、拡張性、レプリケーション、高スループットなどの最高の機能がいくつかあり、このApache Kafkaチュートリアルに例示されているように、いくつかの最高の産業用アプリケーションからアクセスできます。
ビッグデータについて詳しく知りたい場合は、ビッグデータプログラムのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。このプログラムは、働く専門家向けに設計されており、7つ以上のケーススタディとプロジェクトを提供し、14のプログラミング言語とツール、実践的なハンズオンをカバーしています。ワークショップ、トップ企業との400時間以上の厳格な学習と就職支援。
世界のトップ大学からオンラインでソフトウェア開発コースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。