
Apache Kafka 教程:简介、概念、工作流程、工具、应用程序
已发表: 2020-03-10目录
介绍
随着 Kafka 作为消息传递系统的日益普及,许多公司需要具备 Kafka 技能知识的专业人员,这就是Apache Kafka 教程派上用场的地方。 大数据领域中使用了大量数据,需要一个消息系统来进行数据收集和分析。
Kafka 是传统消息代理的有效替代品,具有更高的吞吐量、固有的分区和复制以及内置的容错能力,使其适用于大规模的消息处理应用程序。 如果您一直在寻找Apache Kafka 教程,那么这是适合您的文章。
本Apache Kafka 教程的主要内容
- 消息系统的概念
- Apache Kafka 简介
- Kafka集群和Kafka架构相关概念
- Kafka消息传递工作流程的简要描述
- Kafka 重要工具概述
- Apache Kafka的用例和应用
另请了解:面向初学者的 Apache Spark 流式处理教程
消息系统的简要概述
消息系统的主要功能是允许数据从一个应用程序传输到另一个应用程序; 系统确保应用程序只关注数据,在数据共享和传输过程中不会卡顿。 有两种消息传递系统:
1.点对点消息系统
在这个系统中,消息的生产者被称为发送者,而消费消息的人被称为接收者。 在该域中,消息通过称为队列的目的地进行交换; 发送者或生产者将消息生成到队列中,消息由队列中的接收者消费。

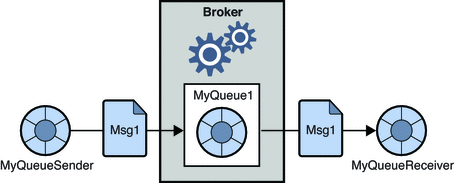
资源
2.发布订阅消息系统
在这个系统中,消息的生产者称为发布者,而消费消息的人称为订阅者。 但是,在此域中,消息通过称为主题的目的地进行交换。 发布者向某个主题生成消息,并且订阅了一个主题,订阅者使用来自该主题的消息。 该系统允许广播消息(拥有多个订阅者,并且每个订阅者都获得发布到特定主题的消息的副本)。
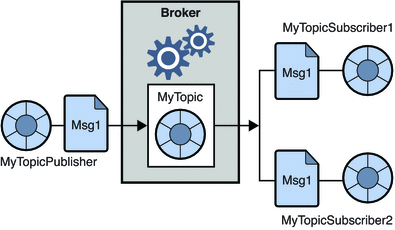
资源
阿帕奇卡夫卡——介绍
Apache Kafka 基于发布-订阅 (pub-sub) 消息传递系统。 在发布-订阅消息系统中,发布者是消息的生产者,订阅者是消息的消费者。 在这个系统中,消费者可以消费订阅主题的所有消息。这个发布-订阅消息系统的原理在 Apache Kafka 中得到了应用。
此外,Apache Kafka 使用分布式消息传递的概念,因此,在消息传递系统和应用程序之间存在非同步的消息排队。 凭借能够处理大量数据的强大队列,Kafka 允许您将消息从一个端点传输到另一个端点,并且适用于消息的在线和离线消费。 Apache Kafka 结合了可靠性、可扩展性、持久性和高吞吐量性能,是现实世界中大规模数据系统单元之间集成和通信的理想选择。
另请阅读:大数据项目理念
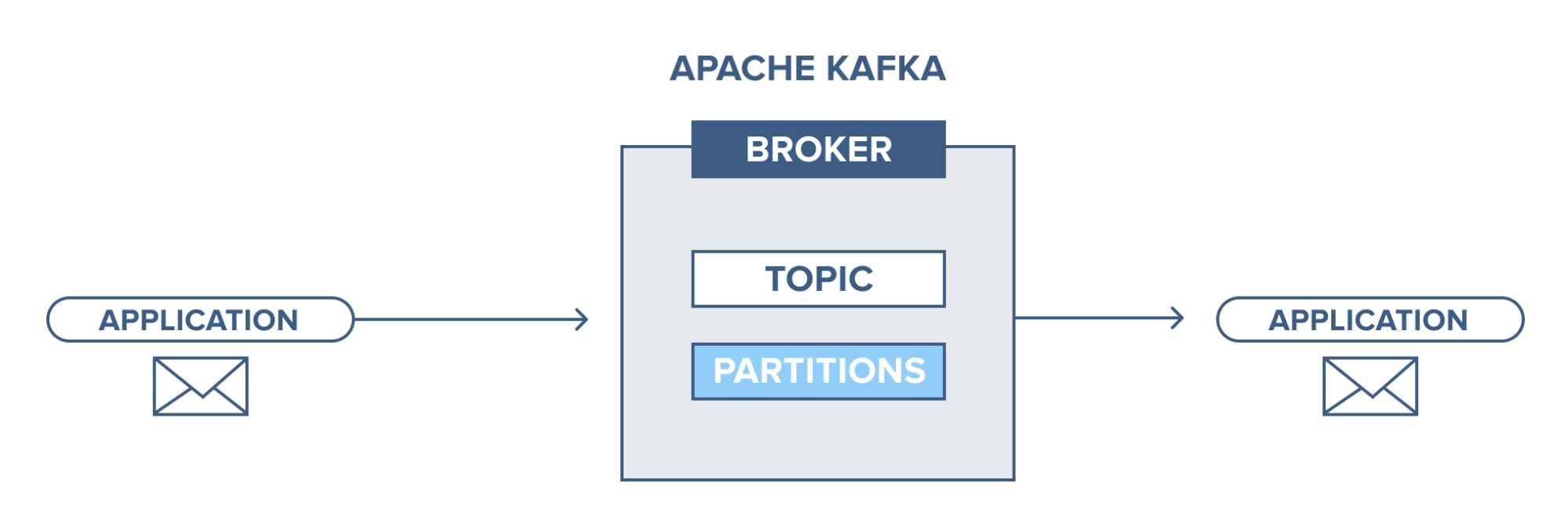
资源
Apache Kafka 集群的概念
资源
- Kafka zookeeper :集群中的brokers由zookeepers协调和管理。 Zookeeper 通知生产者和消费者有关 Kafka 系统中存在新代理或代理失败的信息,并通知消费者有关偏移值的信息。 生产者和消费者在收到来自动物园管理员的信息后,与另一个经纪人协调他们的活动。
- Kafka 代理: Kafka 代理是负责在动物园管理员的帮助下维护 Kafka 集群中已发布数据的系统。 对于每个主题,代理可能有零个或多个分区。
- Kafka生产者:一个或多个Kafka主题的消息由生产者发布并推送给broker,无需等待broker确认。
- Kafka 消费者:消费者从代理中提取数据并使用来自一个或多个主题的已发布消息,向代理发出非同步拉取请求以准备好使用字节缓冲区,然后提供偏移值以回退或跳到任何分区点。
Kafka 架构的基本概念
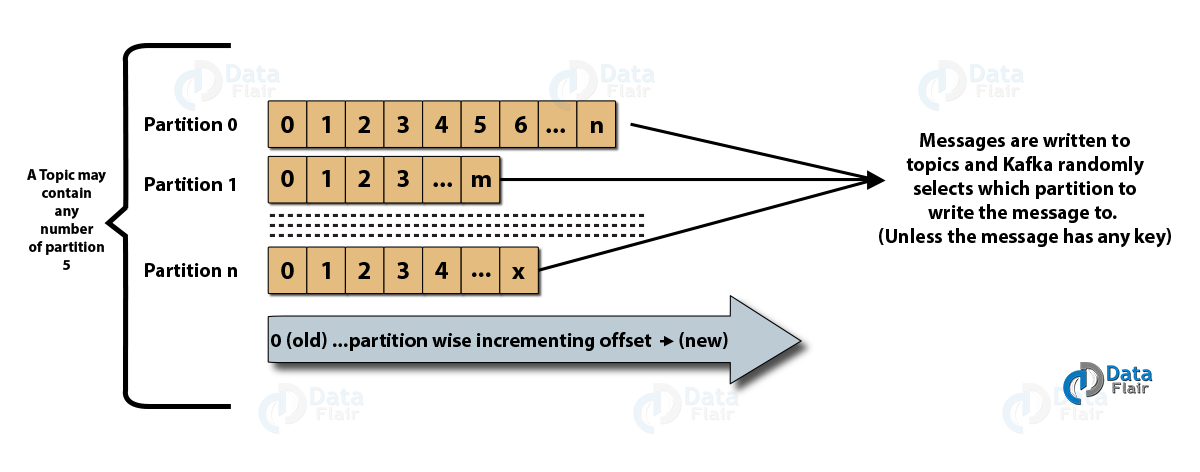
- 主题:它是一个逻辑通道,生产者向其发布消息,消费者从中接收消息。 主题可以复制(复制)以及分区(划分)。 特定类型的消息发布在特定主题上,每个主题都可以通过其唯一名称来识别。
- 主题分区:在 Kafka 集群中,主题被划分为多个分区以及跨代理复制。 生产者可以为发布的消息添加一个密钥,具有相同密钥的消息最终会在同一个分区中。 一个名为 offset 的增量 ID 被分配给一个分区中的每条消息,这些 ID 只在分区内有效,并且在主题中的分区之间没有任何值。
- 领导者和副本:每个 Kafka 代理都有几个分区,每个分区可以是领导者或主题的副本(备份)。 领导者不仅负责读取和写入主题,还负责使用新数据更新副本。 在任何情况下,如果领导者失败,副本可以接管作为新领导者。
阿帕奇卡夫卡的架构
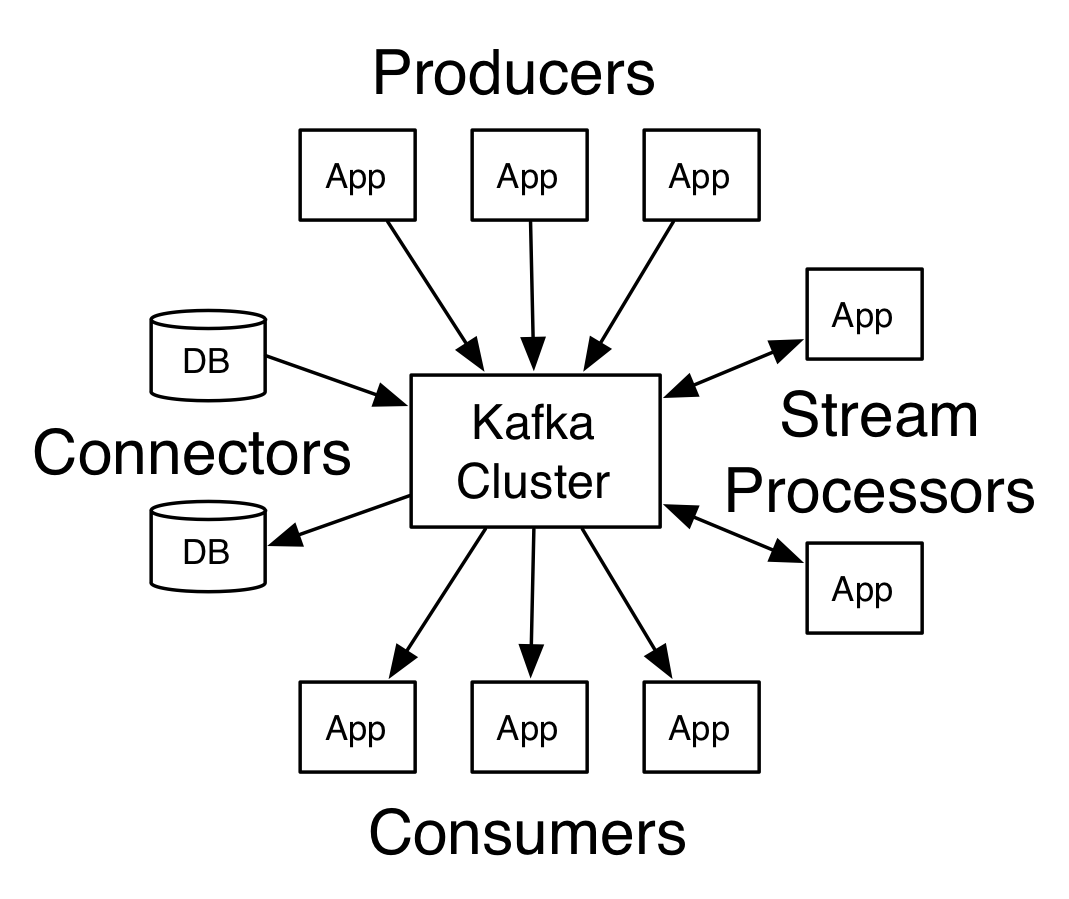
资源

拥有多个代理的 Kafka 称为 Kafka 集群。 本Apache Kafka 教程将讨论四个核心 API :
- 生产者 API: Kafka 生产者 API 允许应用程序将记录流发布到一个或多个 Kafka 主题。
- 消费者 API:消费者 API 允许应用程序处理生成到一个或多个主题的连续记录流。
- Streams API:流 API 允许应用程序使用来自一个或多个主题的输入流并生成一个或多个输出主题的输出流,从而允许应用程序充当流处理器。 这有效地将输入流修改为输出流。
- 连接器 API:连接器 API 允许创建和运行可重用的生产者和消费者,从而实现 Kafka 主题与现有数据系统或应用程序之间的连接。
发布者-订阅者消息传递域的工作流程
- Kafka 生产者定期向主题发送消息。
- Kafka 代理通过将消息存储在为特定主题配置的分区中来确保消息在分区内的平等分布。
- 订阅特定主题由 Kafka 消费者完成。 一旦消费者订阅了一个主题,该主题的当前偏移量就会提供给消费者,并且该主题将保存在 zookeeper ensemble 中。
- 消费者定期向 Kafka 请求新消息。
- Kafka 在收到生产者的消息后立即将消息转发给消费者。
- 消费者接收消息并处理它。
- 处理完消息后,Kafka 代理会立即获得确认。
- 收到确认后,偏移量将升级为新值。
- 流程重复,直到消费者停止请求。
- 消费者可以随时跳过或回退偏移量,并根据方便阅读后续消息。
队列消息系统的工作流程
在队列消息系统中,具有相同组 ID 的多个消费者可以订阅一个主题。 他们被视为一个组并共享消息。 系统的工作流程是:
- Kafka 生产者定期向主题发送消息。
- Kafka 代理通过将消息存储在为特定主题配置的分区中来确保消息在分区内的平等分布。
- 单个消费者订阅特定主题。
- 在新的消费者订阅同一个主题之前,Kafka 会与单个消费者进行交互。
- 随着新消费者的到来,数据在两个消费者之间共享。 重复共享,直到为该主题配置的分区数等于消费者数。
- 当消费者数量超过配置的分区数量时,新消费者将不会收到更多消息。 出现这种情况是因为每个消费者至少有权获得一个分区,如果没有分区是空白的,新的消费者必须等待。
Apache Kafka 中的 2 个重要工具
接下来,在本Apache Kafka 教程中,我们将讨论打包在“org.apache.kafka.tools.*”下的 Kafka 工具。
1. 复制工具
它是一种高级设计工具,可提供更高的可用性和更高的耐用性。
- Create Topic 工具:该工具用于创建具有复制因子和默认分区数的主题,并使用 Kafka 的默认方案进行副本分配。
- 列出主题工具:此工具列出给定主题列表的信息。 此工具显示分区、主题名称、领导者、副本和 isr 等字段。
- 添加分区工具:此工具可以为特定主题添加更多分区。 它还执行添加分区的副本的手动分配。
2.系统工具
运行类脚本可用于在 Kafka 中运行系统工具。 语法是:
- Mirror Maker:这个工具的用途是将一个Kafka集群镜像到另一个。
- Kafka 迁移工具:此工具有助于将 Kafka 代理从一个版本迁移到另一个版本。
- Consumer Offset Checker:此工具显示特定主题集的 Kafka 主题、日志大小、偏移量、分区、消费者组和所有者。
另请阅读: Apache Pig 教程

Apache Kafka 的 4 大用例
让我们在这个 Apache Kafka 教程中讨论 Apache Kafka 的一些重要用例:
- 流处理: Kafka 强大的持久性特性使其可以应用于流处理领域。 在这种情况下,从主题中读取数据并进行处理,然后将处理后的数据写入新主题以使其可供应用程序和用户使用。
- 指标: Kafka 经常用于数据的操作监控。 统计数据从分布式应用程序汇总,以集中提供运营数据。
- 跟踪网站活动: BigQuery 和 Google 等数据仓库使用 Kafka 来跟踪网站上的活动。 搜索、页面查看或其他用户操作等站点活动被发布到中心主题,并可用于实时处理、离线分析和仪表板。
- 日志聚合:使用 Kafka,可以从许多服务中收集日志,并以标准化格式提供给许多消费者。
Apache Kafka 的 5 大应用
Kafka 支持的一些最佳工业应用包括:
- Uber:出租车应用程序需要大量的实时处理并处理大量数据。 审计、ETA 计算以及驱动程序和客户匹配等重要流程都是基于 Kafka Streams 建模的。
- Netflix:点播互联网流媒体平台 Netflix 使用 Kafka 指标来处理事件和实时监控。
- LinkedIn: LinkedIn 每天管理 7 万亿条消息,包含 100,000 个主题、700 万个分区和 4000 多个经纪人。 Apache Kafka 在 LinkedIn 中用于用户活动跟踪、监控和跟踪。
- Tinder:这款流行的约会应用程序将 Kafka Streams 用于多个流程,包括内容审核、推荐、更新用户时区、通知和用户激活等。
- Pinterest:每月搜索数十亿个图钉和想法,Pinterest 已将 Kafka 用于许多流程。 Kafka Streams 用于索引内容、检测垃圾邮件、推荐和计算实时广告的预算。
结论
在本Apache Kafka 教程中,我们讨论了 Apache Kafka 的基本概念、Kafka 中的架构和集群、Kafka 工作流程、Kafka 工具以及 Kafka 的一些应用。 Apache Kafka 具有一些最好的特性,如持久性、可扩展性、容错性、可靠性、可扩展性、复制和高吞吐量,使其可以在一些最好的工业应用程序中访问,如本Apache Kafka 教程所示。
如果您有兴趣了解有关大数据的更多信息,请查看我们的 PG 大数据软件开发专业文凭课程,该课程专为在职专业人士设计,提供 7 多个案例研究和项目,涵盖 14 种编程语言和工具,实用的动手操作研讨会,超过 400 小时的严格学习和顶级公司的就业帮助。
从世界顶级大学在线学习软件开发课程。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。