
Tutoriel Apache Kafka : introduction, concepts, flux de travail, outils, applications
Publié: 2020-03-10Table des matières
introduction
Avec la popularité croissante de Kafka en tant que système de messagerie, de nombreuses entreprises exigent des professionnels ayant une bonne connaissance des compétences de Kafka, et c'est là qu'un didacticiel Apache Kafka est utile. Une énorme quantité de données est utilisée dans le domaine du Big Data qui nécessite un système de messagerie pour la collecte et l'analyse des données.
Kafka est un remplacement efficace du courtier de messages conventionnel avec un débit amélioré, un partitionnement et une réplication inhérents et une tolérance aux pannes intégrée, ce qui le rend adapté aux applications de traitement de messages à grande échelle. Si vous recherchez un didacticiel Apache Kafka , cet article est fait pour vous.
Principaux points à retenir de ce didacticiel Apache Kafka
- Concept de systèmes de messagerie
- Une brève introduction à Apache Kafka
- Concepts liés au cluster Kafka et à l'architecture Kafka
- Brève description du workflow de messagerie Kafka
- Vue d'ensemble des outils Kafka importants
- Cas d'utilisation et applications d'Apache Kafka
Découvrez également : Didacticiel Apache Spark Streaming pour les débutants
Un bref aperçu des systèmes de messagerie
La fonction principale d'un système de messagerie est de permettre le transfert de données d'une application à une autre ; le système garantit que les applications se concentrent uniquement sur les données sans se bloquer pendant le processus de partage et de transmission des données. Il existe deux types de systèmes de messagerie :
1. Système de messagerie point à point
Dans ce système, les producteurs des messages sont appelés expéditeurs et ceux qui consomment les messages sont les récepteurs. Dans ce domaine, les messages sont échangés via une destination appelée file d'attente ; les expéditeurs ou les producteurs produisent les messages vers la file d'attente, et les messages sont consommés par les récepteurs de la file d'attente.

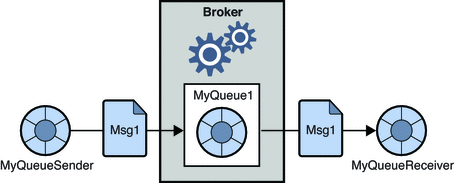
La source
2. Système de messagerie Publier-Abonnez-vous
Dans ce système, les producteurs des messages sont appelés éditeurs et ceux qui consomment les messages sont abonnés. Cependant, dans ce domaine, les messages sont échangés via une destination appelée topic. Un éditeur produit les messages d'un sujet et s'étant abonnés à un sujet, les abonnés consomment les messages du sujet. Ce système permet la diffusion de messages (avoir plus d'un abonné et chacun reçoit une copie des messages publiés sur un sujet particulier).
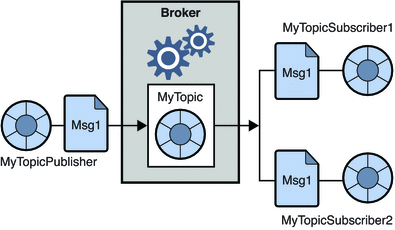
La source
Apache Kafka – une introduction
Apache Kafka est basé sur un système de messagerie de publication-abonnement (pub-sub). Dans le système de messagerie pub-sub, les éditeurs sont les producteurs des messages et les abonnés sont les consommateurs des messages. Dans ce système, les consommateurs peuvent consommer tous les messages du ou des sujets abonnés. Ce principe du système de messagerie pub-sub est employé dans Apache Kafka.
De plus, Apache Kafka utilise le concept de messagerie distribuée, selon lequel il existe une file d'attente non synchrone des messages entre le système de messagerie et les applications. Avec une file d'attente robuste capable de gérer un grand volume de données, Kafka vous permet de transmettre des messages d'un point de terminaison à un autre et est adapté à la consommation de messages en ligne et hors ligne. Combinant fiabilité, évolutivité, durabilité et performances à haut débit, Apache Kafka est idéal pour l'intégration et la communication entre les unités de systèmes de données à grande échelle dans le monde réel.
Lisez aussi : Idées de projets Big Data
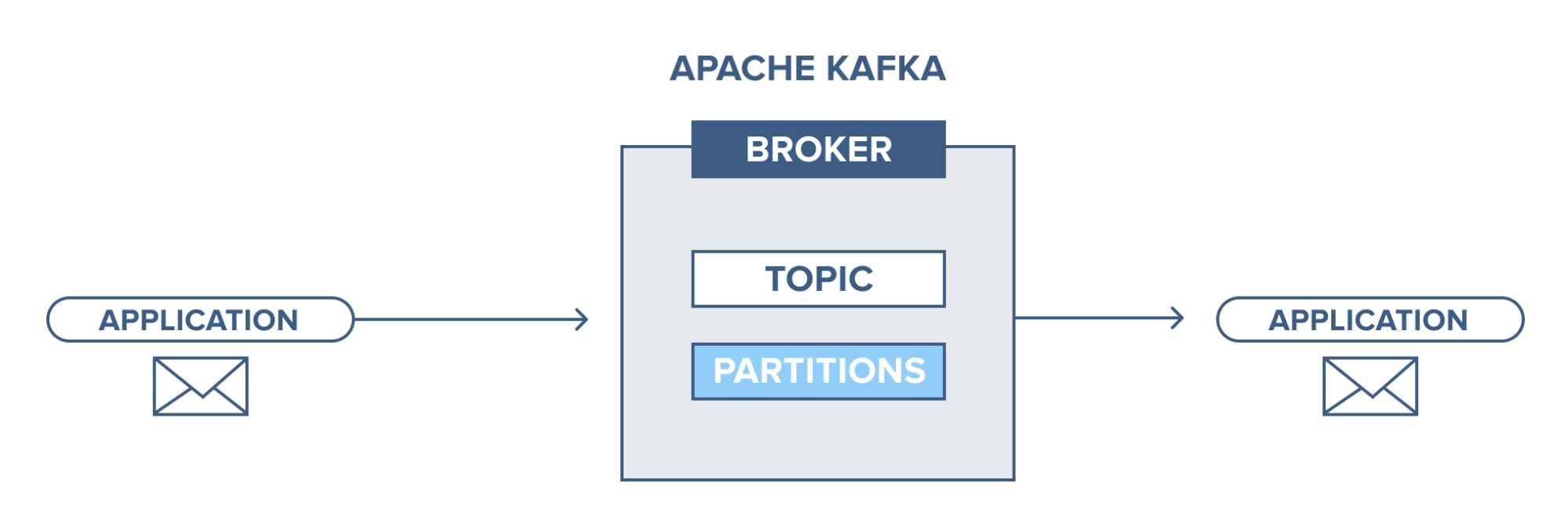
La source
Concept des clusters Apache Kafka
La source
- Gardien de zoo Kafka : Les courtiers d'un cluster sont coordonnés et gérés par des gardiens de zoo. Zookeeper informe les producteurs et les consommateurs de la présence d'un nouveau courtier ou de l'échec d'un courtier dans le système Kafka et informe les consommateurs de la valeur de compensation. Les producteurs et les consommateurs coordonnent leurs activités avec un autre courtier dès réception du gardien du zoo.
- Courtier Kafka : Les courtiers Kafka sont des systèmes chargés de maintenir les données publiées dans les clusters Kafka avec l'aide de zookeepers. Un courtier peut avoir zéro ou plusieurs partitions pour chaque rubrique.
- Producteur Kafka : les messages sur un ou plusieurs sujets Kafka sont publiés par le producteur et poussés vers les courtiers, sans attendre l'accusé de réception des courtiers.
- Consommateur Kafka : les consommateurs extraient les données des courtiers et consomment les messages déjà publiés d'un ou plusieurs sujets, envoient une demande d'extraction non synchrone au courtier pour disposer d'un tampon d'octets prêt à consommer, puis fournissent une valeur de décalage pour revenir en arrière ou passer à n'importe quel point de partition.
Concepts fondamentaux de l'architecture Kafka
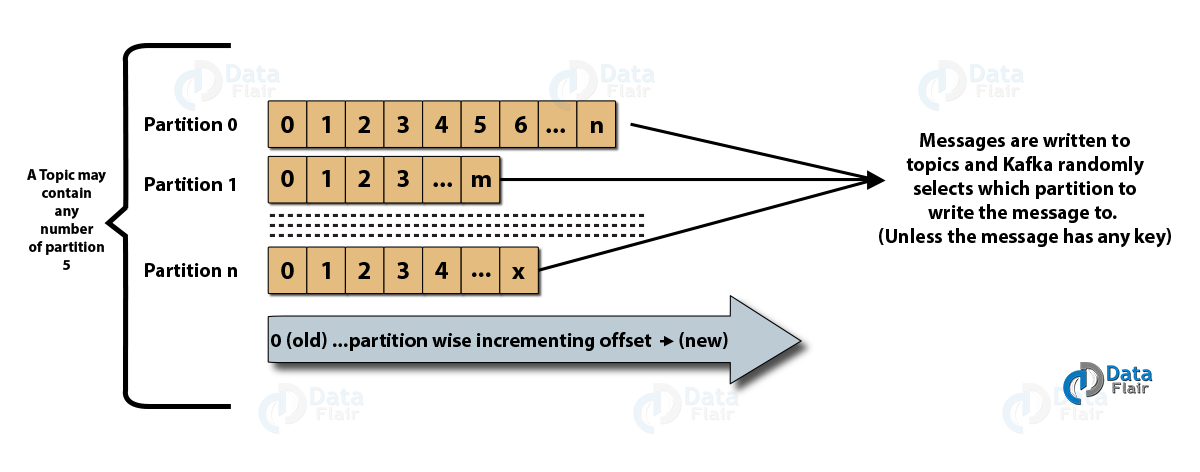
- Topics : C'est un canal logique sur lequel les messages sont publiés par les producteurs et à partir duquel les messages sont reçus par les consommateurs. Les sujets peuvent être répliqués (copiés) ainsi que partitionnés (divisés). Un type particulier de message est publié sur un sujet spécifique, chaque sujet étant identifiable par son nom unique.
- Partitions de sujets : dans le cluster Kafka, les sujets sont divisés en partitions et répliqués sur les courtiers. Un producteur peut ajouter une clé à un message publié, et les messages avec la même clé se retrouvent dans la même partition. Un ID incrémentiel appelé décalage est attribué à chaque message dans une partition, et ces ID ne sont valides qu'au sein de la partition et n'ont aucune valeur entre les partitions d'une rubrique.
- Leader et réplique : chaque courtier Kafka a quelques partitions avec chaque partition, soit un leader, soit une réplique (sauvegarde) du sujet. Le leader est responsable non seulement de la lecture et de l'écriture dans un sujet, mais également de la mise à jour des répliques avec de nouvelles données. Si, dans tous les cas, le leader échoue, la réplique peut prendre le relais en tant que nouveau leader.
Architecture d'Apache Kafka
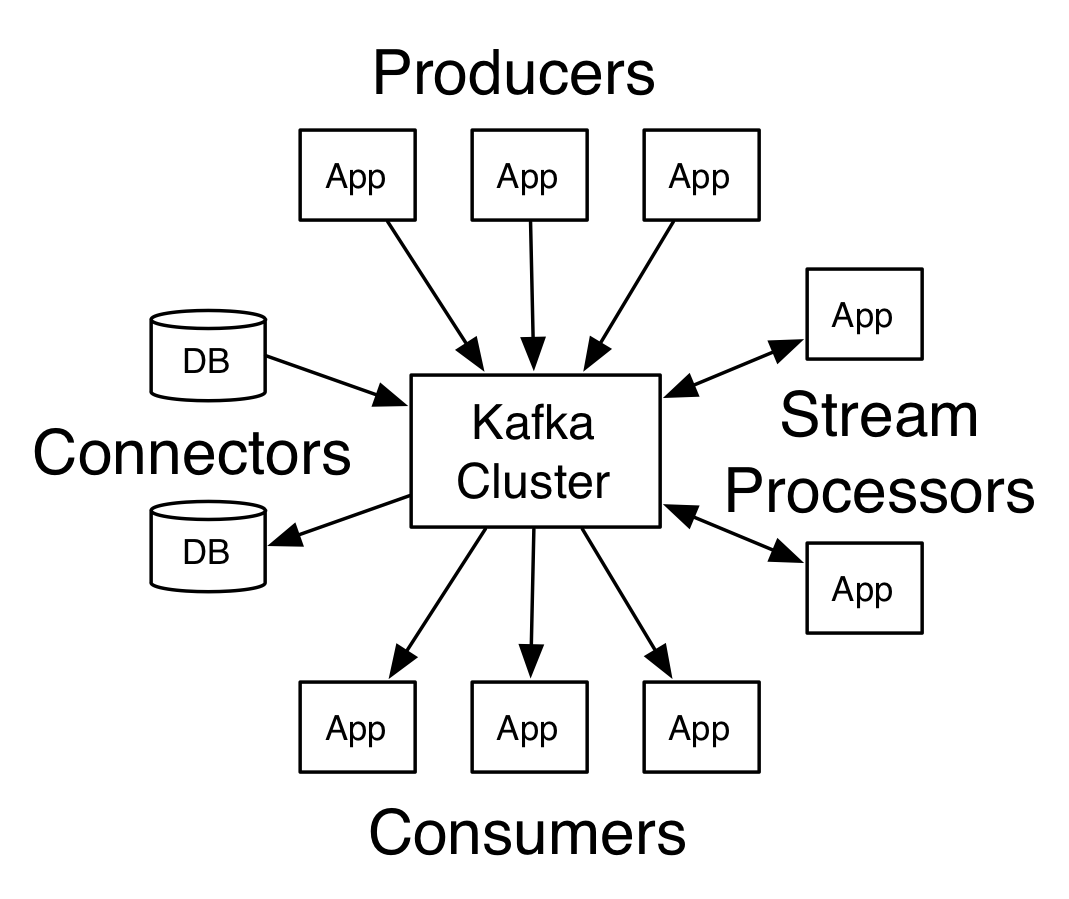
La source
Un Kafka ayant plus d'un courtier est appelé un cluster Kafka. Quatre des principales API seront abordées dans ce tutoriel Apache Kafka :
- API producteur : L'API producteur Kafka permet de publier un flux d'enregistrements par une application vers un ou plusieurs sujets Kafka.
- API consommateur : l'API consommateur permet à une application de traiter le flux continu d'enregistrements produits dans un ou plusieurs sujets.
- API Streams : L'API Streams permet à une application de consommer un flux d'entrée d'un ou plusieurs sujets et de générer un flux de sortie vers un ou plusieurs sujets de sortie, permettant ainsi à l'application d'agir comme un processeur de flux. Cela modifie efficacement les flux d'entrée en flux de sortie.
- API de connecteur : l'API de connecteur permet la création et l'exécution de producteurs et de consommateurs réutilisables, permettant ainsi une connexion entre les sujets Kafka et les systèmes de données ou applications existants.
Workflow du domaine de messagerie éditeur-abonné
- Les producteurs de Kafka envoient des messages à un sujet à intervalles réguliers.
- Les courtiers Kafka assurent une distribution égale des messages au sein des partitions en les stockant dans les partitions configurées pour un sujet particulier.
- L'abonnement à un sujet spécifique est effectué par les consommateurs Kafka. Une fois que le consommateur s'est abonné à un sujet, le décalage actuel du sujet est proposé au consommateur, et le sujet est enregistré dans l'ensemble zookeeper.
- Le consommateur demande à Kafka de nouveaux messages à intervalles réguliers.
- Kafka transmet les messages aux consommateurs dès leur réception par les producteurs.
- Le consommateur reçoit le message et le traite.
- Le courtier Kafka reçoit un accusé de réception dès que le message est traité.
- A réception de l'acquittement, l'offset est mis à jour à la nouvelle valeur.
- Le flux se répète jusqu'à ce que le consommateur arrête la requête.
- Le consommateur peut ignorer ou rembobiner un décalage à tout moment et lire les messages suivants selon sa convenance.
Flux de travail du système de messagerie de file d'attente
Dans un système de messagerie de file d'attente, plusieurs consommateurs avec le même ID de groupe peuvent s'abonner à un sujet. Ils sont considérés comme un seul groupe et partagent les messages. Le flux de travail du système est :

- Les producteurs de Kafka envoient des messages à un sujet à intervalles réguliers.
- Les courtiers Kafka assurent une distribution égale des messages au sein des partitions en les stockant dans les partitions configurées pour un sujet particulier.
- Un seul consommateur s'abonne à un sujet spécifique.
- Jusqu'à ce qu'un nouveau consommateur s'abonne au même sujet, Kafka interagit avec le consommateur unique.
- Avec l'arrivée des nouveaux consommateurs, les données sont partagées entre deux consommateurs. Le partage est répété jusqu'à ce que le nombre de partitions configurées pour ce sujet soit égal au nombre de consommateurs.
- Un nouveau consommateur ne recevra plus de messages lorsque le nombre de consommateurs dépasse le nombre de partitions configurées. Cette situation se produit en raison de la condition selon laquelle chaque consommateur a droit à au moins une partition, et si aucune partition n'est vide, les nouveaux consommateurs doivent attendre.
2 outils importants dans Apache Kafka
Ensuite, dans ce didacticiel Apache Kafka , nous aborderons les outils Kafka regroupés sous « org.apache.kafka.tools.*.
1. Outils de réplication
Il s'agit d'un outil de conception de haut niveau qui confère une plus grande disponibilité et une plus grande durabilité.
- Outil Créer une rubrique : Cet outil est utilisé pour créer une rubrique avec un facteur de réplication et un nombre de partitions par défaut et utilise le schéma par défaut de Kafka pour effectuer une affectation de réplique.
- Outil de liste de sujets : les informations d'une liste de sujets donnée sont répertoriées par cet outil. Des champs tels que la partition, le nom du sujet, le leader, les répliques et l'isr sont affichés par cet outil.
- Outil Ajouter une partition : cet outil permet d'ajouter plus de partitions pour un sujet particulier. Il effectue également l'affectation manuelle des répliques des partitions ajoutées.
2. Outils système
Le script de classe d'exécution peut être utilisé pour exécuter des outils système dans Kafka. La syntaxe est :
- Mirror Maker : L'utilisation de cet outil consiste à mettre en miroir un cluster Kafka sur un autre.
- Outil de migration Kafka : cet outil aide à migrer un courtier Kafka d'une version à une autre.
- Consumer Offset Checker : Cet outil affiche le sujet Kafka, la taille du journal, le décalage, les partitions, le groupe de consommateurs et le propriétaire pour l'ensemble particulier de sujets.
Lire aussi : Tutoriel Apache Pig

Top 4 des cas d'utilisation d'Apache Kafka
Discutons de quelques cas d'utilisation importants d'Apache Kafka dans ce didacticiel Apache Kafka :
- Traitement de flux : La caractéristique de forte durabilité de Kafka lui permet d'être utilisé dans le domaine du traitement de flux. Dans ce cas, les données sont lues à partir d'un sujet, traitées et les données traitées sont ensuite écrites dans un nouveau sujet pour les rendre disponibles pour les applications et les utilisateurs.
- Métriques : Kafka est fréquemment utilisé pour la surveillance opérationnelle des données. Les statistiques sont agrégées à partir d'applications distribuées pour constituer un flux centralisé de données opérationnelles.
- Suivi de l'activité du site Web : les entrepôts de données tels que BigQuery et Google utilisent Kafka pour suivre les activités sur les sites Web. Les activités du site telles que les recherches, les pages vues ou d'autres actions de l'utilisateur sont publiées dans des rubriques centrales et rendues accessibles pour le traitement en temps réel, l'analyse hors ligne et les tableaux de bord.
- Agrégation de journaux : à l'aide de Kafka, les journaux peuvent être collectés à partir de nombreux services et mis à disposition dans un format standardisé pour de nombreux consommateurs.
Top 5 des applications d'Apache Kafka
Certaines des meilleures applications industrielles prises en charge par Kafka incluent :
- Uber : L'application de taxi nécessite un traitement en temps réel immense et gère un énorme volume de données. Des processus importants tels que l'audit, les calculs d'ETA et la mise en correspondance des conducteurs et des clients sont modélisés sur la base de Kafka Streams.
- Netflix : la plate-forme de streaming Internet à la demande Netflix utilise les métriques Kafka pour le traitement des événements et la surveillance en temps réel.
- LinkedIn : LinkedIn gère 7 000 milliards de messages chaque jour, avec 100 000 sujets, 7 millions de partitions et plus de 4 000 courtiers. Apache Kafka est utilisé dans LinkedIn pour le suivi, la surveillance et le suivi de l'activité des utilisateurs.
- Tinder : cette application de rencontres populaire utilise Kafka Streams pour plusieurs processus, notamment la modération du contenu, les recommandations, la mise à jour du fuseau horaire de l'utilisateur, les notifications et l'activation de l'utilisateur, entre autres.
- Pinterest : Avec une recherche mensuelle de milliards d'épingles et d'idées, Pinterest a tiré parti de Kafka pour de nombreux processus. Kafka Streams est utilisé pour l'indexation des contenus, la détection des spams, les recommandations et le calcul des budgets des publicités en temps réel.
Conclusion
Dans ce didacticiel Apache Kafka , nous avons abordé les concepts fondamentaux d'Apache Kafka, l'architecture et le cluster dans Kafka, le workflow Kafka, les outils Kafka et certaines applications de Kafka. Apache Kafka possède certaines des meilleures fonctionnalités telles que la durabilité, l'évolutivité, la tolérance aux pannes, la fiabilité, l'extensibilité, la réplication et le haut débit qui le rendent accessible à certaines des meilleures applications industrielles, comme illustré dans ce didacticiel Apache Kafka .
Si vous souhaitez en savoir plus sur le Big Data, consultez notre programme PG Diploma in Software Development Specialization in Big Data qui est conçu pour les professionnels en activité et fournit plus de 7 études de cas et projets, couvre 14 langages et outils de programmation, pratique pratique ateliers, plus de 400 heures d'apprentissage rigoureux et d'aide au placement dans les meilleures entreprises.
Apprenez des cours de développement de logiciels en ligne dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.