
Apache Kafka 튜토리얼: 소개, 개념, 워크플로, 도구, 애플리케이션
게시 됨: 2020-03-10목차
소개
메시징 시스템으로 Kafka의 인기가 높아짐에 따라 많은 회사에서 Kafka 기술에 대한 충분한 지식을 갖춘 전문가를 요구하며 Apache Kafka Tutorial 이 유용한 곳입니다. 데이터 수집 및 분석을 위한 메시징 시스템이 필요한 빅데이터 영역에서는 엄청난 양의 데이터가 사용됩니다.
Kafka는 향상된 처리량, 고유한 분할 및 복제, 내장된 내결함성을 갖춘 기존 메시지 브로커를 효율적으로 대체하므로 대규모 메시지 처리 애플리케이션에 적합합니다. Apache Kafka Tutorial 을 찾고 있었다면 이 기사가 적합합니다.
이 Apache Kafka 자습서 의 주요 내용
- 메시징 시스템의 개념
- Apache Kafka에 대한 간략한 소개
- Kafka 클러스터 및 Kafka 아키텍처와 관련된 개념
- Kafka 메시징 워크플로에 대한 간략한 설명
- 중요한 Kafka 도구 개요
- Apache Kafka의 사용 사례 및 애플리케이션
추가 정보: 초보자를 위한 Apache Spark 스트리밍 자습서
메시징 시스템에 대한 간략한 개요
메시징 시스템의 주요 기능은 한 응용 프로그램에서 다른 응용 프로그램으로 데이터를 전송할 수 있도록 하는 것입니다. 이 시스템은 애플리케이션이 데이터 공유 및 전송 과정에서 중단되지 않고 데이터에만 집중할 수 있도록 합니다. 메시징 시스템에는 두 가지 종류가 있습니다.
1. 포인트 투 포인트 메시징 시스템
이 시스템에서 메시지를 생성하는 사람을 발신자라고 하고 메시지를 소비하는 사람을 수신자라고 합니다. 이 도메인에서 메시지는 대기열이라는 대상을 통해 교환됩니다. 발신자 또는 생산자는 대기열에 메시지를 생성하고 대기열의 수신자는 메시지를 사용합니다.

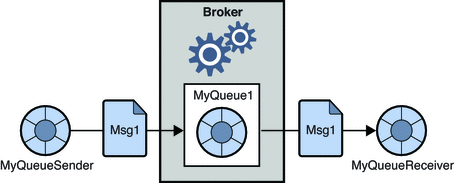
원천
2. 발행-구독 메시징 시스템
이 시스템에서 메시지의 생산자는 게시자라고 하고 메시지를 소비하는 사람은 구독자입니다. 그러나 이 도메인에서 메시지는 주제로 알려진 대상을 통해 교환됩니다. 게시자는 주제에 대한 메시지를 생성하고 주제를 구독하면 구독자는 주제의 메시지를 소비합니다. 이 시스템은 메시지 브로드캐스트를 허용합니다(둘 이상의 구독자가 있고 각 구독자는 특정 주제에 게시된 메시지 사본을 얻음).
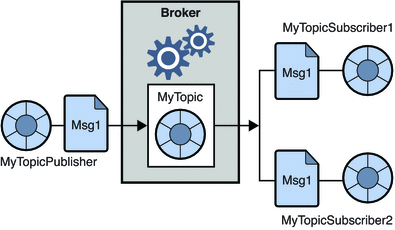
원천
Apache Kafka – 소개
Apache Kafka는 게시-구독(pub-sub) 메시징 시스템을 기반으로 합니다. pub-sub 메시징 시스템에서 게시자는 메시지 생산자이고 구독자는 메시지 소비자입니다. 이 시스템에서 소비자는 구독된 주제의 모든 메시지를 사용할 수 있습니다. pub-sub 메시징 시스템의 이러한 원칙은 Apache Kafka에서 사용됩니다.
또한 Apache Kafka는 분산 메시징 개념을 사용하므로 메시징 시스템과 애플리케이션 간에 비동기식 메시지 대기열이 있습니다. 대용량 데이터를 처리할 수 있는 강력한 대기열을 통해 Kafka를 사용하면 한 끝점에서 다른 끝점으로 메시지를 전송할 수 있으며 온라인 및 오프라인 메시지 소비에 모두 적합합니다. 안정성, 확장성, 내구성 및 높은 처리량 성능을 결합한 Apache Kafka는 실제 환경에서 대규모 데이터 시스템 단위 간의 통합 및 통신에 이상적입니다.
읽어보기: 빅 데이터 프로젝트 아이디어
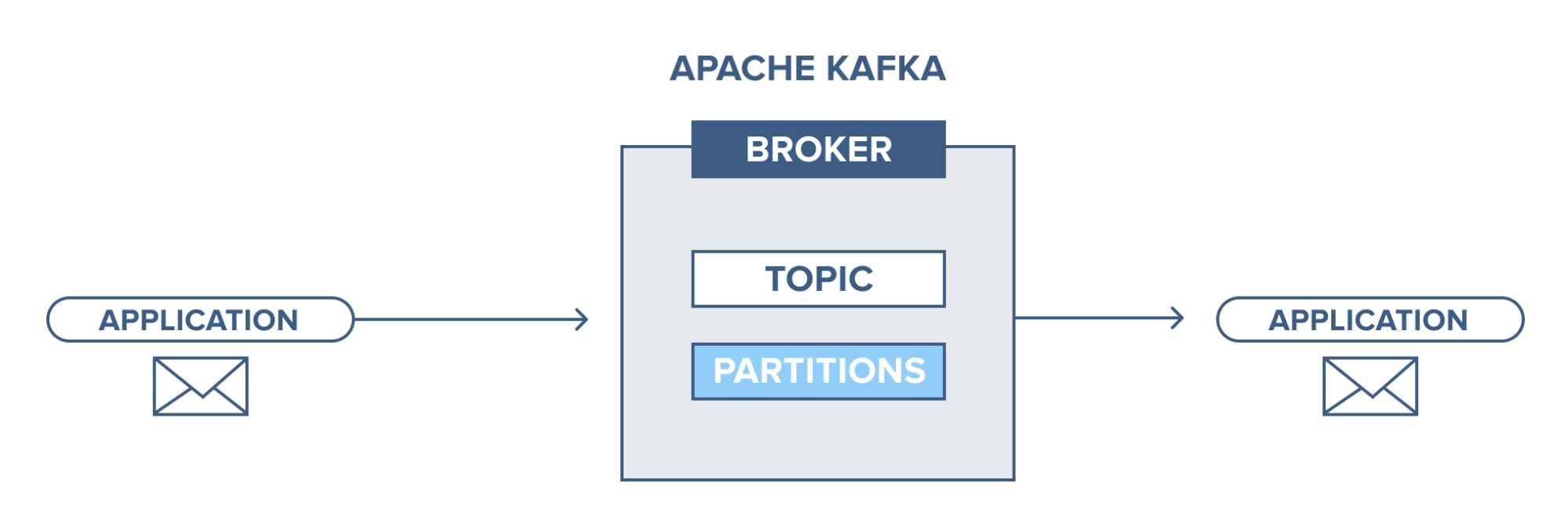
원천
Apache Kafka 클러스터의 개념
원천
- Kafka 사육사 : 클러스터의 브로커는 사육사에 의해 조정되고 관리됩니다. Zookeeper는 Kafka 시스템에서 새로운 브로커의 존재 또는 브로커의 실패에 대해 생산자와 소비자에게 알리고 오프셋 값에 대해 소비자에게 알립니다. 생산자와 소비자는 사육사로부터 받은 후 다른 브로커와 활동을 조정합니다.
- Kafka 브로커: Kafka 브로커는 사육사의 도움을 받아 Kafka 클러스터에 게시된 데이터를 유지 관리하는 시스템입니다. 브로커는 각 주제에 대해 0개 이상의 파티션을 가질 수 있습니다.
- Kafka 생산자: 하나 이상의 Kafka 주제에 대한 메시지는 제작자가 게시하고 브로커 승인을 기다리지 않고 브로커에 푸시됩니다.
- Kafka 소비자: 소비자는 브로커에서 데이터를 추출하고 하나 이상의 주제에서 이미 게시된 메시지를 사용하고, 바이트 버퍼를 사용할 준비가 되도록 브로커에 비동기식 풀 요청을 발행한 다음 되감거나 건너뛸 오프셋 값을 제공합니다. 모든 파티션 지점.
Kafka 아키텍처의 기본 개념
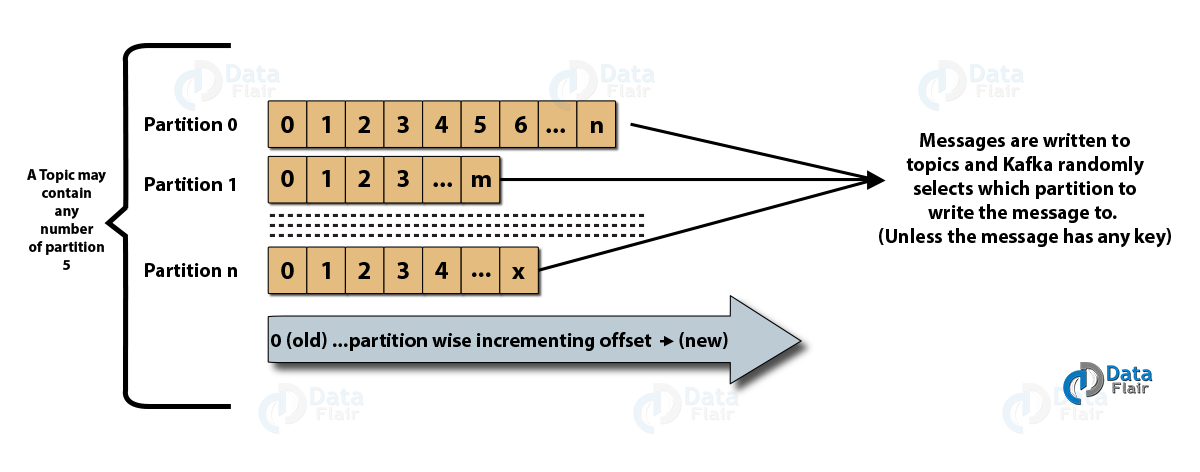
- 토픽 : 생산자가 메시지를 발행하고 소비자가 메시지를 수신하는 논리적 채널입니다. 주제는 복제(복사)할 수도 있고 분할(분할)할 수도 있습니다. 특정 종류의 메시지는 고유한 이름으로 식별할 수 있는 각 주제와 함께 특정 주제에 게시됩니다.
- 토픽 파티션: Kafka 클러스터에서 토픽은 파티션으로 분할되고 브로커 간에 복제됩니다. 생산자는 게시된 메시지에 키를 추가할 수 있으며 동일한 키를 가진 메시지는 결국 동일한 파티션에 있게 됩니다. 오프셋이라는 증분 ID는 파티션의 각 메시지에 할당되며 이러한 ID는 파티션 내에서만 유효하며 주제의 파티션 간에는 값이 없습니다.
- 리더 및 복제본: 모든 Kafka 브로커에는 각 파티션이 있는 몇 개의 파티션이 있으며, 이는 주제의 리더 또는 복제본(백업)입니다. 리더는 주제를 읽고 쓸 뿐만 아니라 복제본을 새 데이터로 업데이트하는 책임이 있습니다. 어떤 경우든 리더가 실패하면 복제본이 새 리더 역할을 인계받을 수 있습니다.
Apache Kafka의 아키텍처
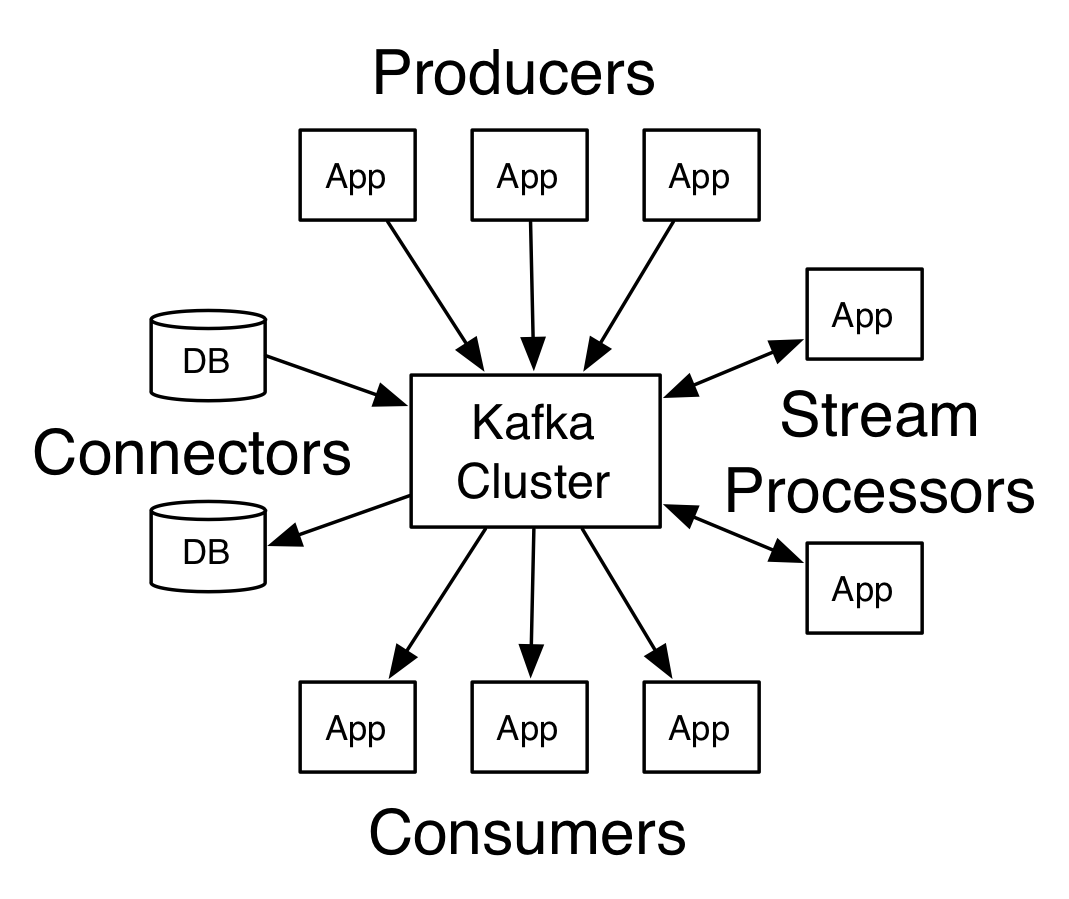
원천

둘 이상의 브로커가 있는 Kafka를 Kafka 클러스터라고 합니다. 이 Apache Kafka Tutorial 에서는 4가지 핵심 API에 대해 설명합니다 .
- 생산자 API: Kafka 생산자 API를 사용하면 애플리케이션에서 하나 이상의 Kafka 주제에 레코드 스트림을 게시할 수 있습니다.
- 소비자 API: 소비자 API를 사용하면 애플리케이션에서 하나 이상의 주제에 대해 생성된 레코드의 지속적인 흐름을 처리할 수 있습니다.
- 스트림 API: 스트림 API를 사용하면 애플리케이션이 하나 또는 여러 주제의 입력 스트림을 사용하고 하나 이상의 출력 주제에 대한 출력 스트림을 생성할 수 있으므로 애플리케이션이 스트림 프로세서 역할을 할 수 있습니다. 이것은 입력 스트림을 출력 스트림으로 효율적으로 수정합니다.
- 커넥터 API: 커넥터 API를 사용하면 재사용 가능한 생산자 및 소비자를 만들고 실행할 수 있으므로 Kafka 주제와 기존 데이터 시스템 또는 애플리케이션 간의 연결이 가능합니다.
게시자-가입자 메시징 도메인의 워크플로
- Kafka 생산자는 일정한 간격으로 주제에 메시지를 보냅니다.
- Kafka 브로커는 특정 주제에 대해 구성된 파티션에 메시지를 저장하여 파티션 내에서 메시지의 균등한 배포를 보장합니다.
- 특정 주제에 대한 구독은 Kafka 소비자가 수행합니다. 소비자가 주제를 구독하면 주제의 현재 오프셋이 소비자에게 제공되고 주제는 사육사 앙상블에 저장됩니다.
- 소비자는 정기적으로 Kafka에 새 메시지를 요청합니다.
- Kafka는 생산자로부터 메시지를 받는 즉시 소비자에게 메시지를 전달합니다.
- 소비자는 메시지를 수신하고 처리합니다.
- Kafka 브로커는 메시지가 처리되는 즉시 승인을 받습니다.
- 승인을 받으면 오프셋이 새 값으로 업그레이드됩니다.
- 소비자가 요청을 중지할 때까지 흐름이 반복됩니다.
- 소비자는 언제든지 오프셋을 건너뛰거나 되감고 편의에 따라 후속 메시지를 읽을 수 있습니다.
대기열 메시징 시스템의 워크플로
대기열 메시징 시스템에서 동일한 그룹 ID를 가진 여러 소비자가 주제를 구독할 수 있습니다. 그들은 단일 그룹으로 간주되어 메시지를 공유합니다. 시스템의 작업 흐름은 다음과 같습니다.
- Kafka 생산자는 일정한 간격으로 주제에 메시지를 보냅니다.
- Kafka 브로커는 특정 주제에 대해 구성된 파티션에 메시지를 저장하여 파티션 내에서 메시지의 균등한 배포를 보장합니다.
- 단일 소비자가 특정 주제를 구독합니다.
- 새로운 소비자가 동일한 주제를 구독할 때까지 Kafka는 단일 소비자와 상호 작용합니다.
- 새로운 소비자가 도착하면 데이터가 두 소비자 간에 공유됩니다. 해당 주제에 대해 구성된 파티션 수가 소비자 수와 같아질 때까지 공유가 반복됩니다.
- 소비자 수가 구성된 파티션 수를 초과하면 새 소비자는 추가 메시지를 받지 않습니다. 이 상황은 각 소비자가 최소 하나의 파티션에 대한 자격이 있고 빈 파티션이 없으면 새 소비자가 기다려야 한다는 조건으로 인해 발생합니다.
Apache Kafka의 2가지 중요한 도구
다음으로 이 Apache Kafka Tutorial 에서 "org.apache.kafka.tools.*" 에 패키지된 Kafka 도구에 대해 설명합니다.
1. 복제 도구
더 높은 가용성과 내구성을 부여하는 고급 설계 도구입니다.
- 주제 생성 도구: 이 도구는 복제 요소와 기본 파티션 수로 주제를 생성하는 데 사용되며 기본 구성표인 Kafka를 사용하여 복제본 할당을 수행합니다.
- 목록 주제 도구: 이 도구는 주어진 주제 목록에 대한 정보를 나열합니다. 파티션, 주제 이름, 리더, 복제본 및 isr과 같은 필드가 이 도구에 의해 표시됩니다.
- 파티션 추가 도구: 이 도구는 특정 주제에 대해 더 많은 파티션을 추가할 수 있습니다. 또한 추가된 파티션의 복제본을 수동으로 할당합니다.
2. 시스템 도구
실행 클래스 스크립트는 Kafka에서 시스템 도구를 실행하는 데 사용할 수 있습니다. 구문은 다음과 같습니다.
- 미러 메이커: 이 도구의 사용은 한 Kafka 클러스터를 다른 클러스터로 미러링하는 것입니다.
- Kafka 마이그레이션 도구: 이 도구는 Kafka 브로커를 한 버전에서 다른 버전으로 마이그레이션하는 데 도움이 됩니다.
- 소비자 오프셋 검사기: 이 도구는 특정 주제 세트에 대한 Kafka 주제, 로그 크기, 오프셋, 파티션, 소비자 그룹 및 소유자를 표시합니다.
또한 읽기: Apache Pig 자습서

Apache Kafka의 상위 4가지 사용 사례
이 Apache Kafka Tutorial에서 Apache Kafka의 몇 가지 중요한 사용 사례에 대해 논의해 보겠습니다.
- 스트림 처리: Kafka는 내구성이 강하여 스트림 처리 분야에서 사용할 수 있습니다. 이 경우 주제에서 데이터를 읽고 처리한 다음 처리된 데이터를 새 주제에 기록하여 애플리케이션과 사용자가 사용할 수 있도록 합니다.
- 메트릭: Kafka는 데이터의 운영 모니터링에 자주 사용됩니다. 통계는 분산 애플리케이션에서 집계되어 운영 데이터의 중앙 집중식 피드를 만듭니다.
- 웹사이트 활동 추적: BigQuery 및 Google과 같은 데이터 웨어하우스는 웹사이트 활동을 추적하기 위해 Kafka를 사용합니다. 검색, 페이지 보기 또는 기타 사용자 작업과 같은 사이트 활동은 중앙 주제에 게시되고 실시간 처리, 오프라인 분석 및 대시보드에 액세스할 수 있습니다.
- 로그 집계: Kafka를 사용하면 많은 서비스에서 로그를 수집하고 많은 소비자가 표준화된 형식으로 사용할 수 있습니다.
Apache Kafka의 상위 5개 애플리케이션
Kafka가 지원하는 최고의 산업용 애플리케이션은 다음과 같습니다.
- Uber: 택시 앱은 엄청난 실시간 처리가 필요하고 엄청난 양의 데이터를 처리해야 합니다. 감사, ETA 계산, 동인 및 고객 매칭과 같은 중요한 프로세스는 Kafka Streams를 기반으로 모델링됩니다.
- Netflix: 주문형 인터넷 스트리밍 플랫폼인 Netflix는 이벤트 처리 및 실시간 모니터링을 위해 Kafka 메트릭을 사용합니다.
- LinkedIn: LinkedIn은 100,000개의 주제, 700만 개의 파티션 및 4000개 이상의 중개인을 포함하여 매일 7조 개의 메시지를 관리합니다. Apache Kafka는 LinkedIn에서 사용자 활동 추적, 모니터링 및 추적에 사용됩니다.
- Tinder: 이 인기 있는 데이트 앱은 콘텐츠 조정, 추천, 사용자 시간대 업데이트, 알림 및 사용자 활성화를 비롯한 여러 프로세스에 Kafka Streams를 사용합니다.
- Pinterest: 매달 수십억 개의 핀과 아이디어를 검색하는 Pinterest는 많은 프로세스에 Kafka를 활용했습니다. Kafka Streams는 콘텐츠 인덱싱, 스팸 감지, 권장 사항 및 실시간 광고 예산 계산에 활용됩니다.
결론
이 Apache Kafka Tutorial 에서 Apache Kafka의 기본 개념, Kafka의 아키텍처 및 클러스터, Kafka 워크플로, Kafka 도구 및 Kafka의 일부 애플리케이션에 대해 논의했습니다. Apache Kafka는 내구성, 확장성, 내결함성, 안정성, 확장성, 복제 및 높은 처리량과 같은 몇 가지 최고의 기능을 갖추고 있어 이 Apache Kafka Tutorial 에서 예시한 것처럼 최고의 산업용 애플리케이션에서 액세스할 수 있습니다 .
빅 데이터에 대해 더 알고 싶다면 PG 디플로마 빅 데이터 소프트웨어 개발 전문화 프로그램을 확인하세요. 이 프로그램은 실무 전문가를 위해 설계되었으며 7개 이상의 사례 연구 및 프로젝트를 제공하고 14개 프로그래밍 언어 및 도구, 실용적인 실습을 다룹니다. 워크샵, 400시간 이상의 엄격한 학습 및 최고의 기업과의 취업 지원.
세계 최고의 대학에서 온라인으로 소프트웨어 개발 과정 을 배우십시오 . 이그 제 큐 티브 PG 프로그램, 고급 인증 프로그램 또는 석사 프로그램을 획득하여 경력을 빠르게 추적하십시오.