
Tutorial Apache Kafka: Introducere, Concepte, Flux de lucru, Instrumente, Aplicații
Publicat: 2020-03-10Cuprins
Introducere
Odată cu popularitatea tot mai mare a lui Kafka ca sistem de mesagerie, multe companii solicită profesioniști cu cunoștințe solide despre abilitățile Kafka și aici este util un tutorial Apache Kafka. O cantitate enormă de date este folosită în domeniul Big Data care necesită un sistem de mesagerie pentru colectarea și analiza datelor.
Kafka este o înlocuire eficientă a brokerului de mesaje convențional, cu un debit îmbunătățit, partiționare și replicare inerente și toleranță la erori încorporată, făcându-l potrivit pentru aplicațiile de procesare a mesajelor la scară largă. Dacă ați căutat un tutorial Apache Kafka , acesta este articolul potrivit pentru dvs.
Recomandări cheie ale acestui tutorial Apache Kafka
- Conceptul de sisteme de mesagerie
- O scurtă introducere în Apache Kafka
- Concepte legate de clusterul Kafka și arhitectura Kafka
- Scurtă descriere a fluxului de lucru al mesajelor Kafka
- Prezentare generală a instrumentelor Kafka importante
- Cazuri de utilizare și aplicații Apache Kafka
Aflați și despre: Apache Spark Streaming Tutorial pentru începători
O scurtă prezentare a sistemelor de mesagerie
Funcția principală a unui sistem de mesagerie este de a permite transferul de date de la o aplicație la alta; sistemul asigură că aplicațiile se concentrează numai pe date, fără a fi blocate în timpul procesului de partajare și transmitere a datelor. Există două tipuri de sisteme de mesagerie:
1. Sistem de mesagerie punct la punct
În acest sistem, producătorii mesajelor sunt numiți expeditori, iar cei care consumă mesajele sunt receptori. În acest domeniu, mesajele sunt schimbate printr-o destinație cunoscută sub numele de coadă; emițătorii sau producătorii produc mesajele în coadă, iar mesajele sunt consumate de receptorii din coadă.

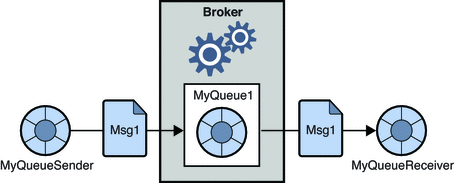
Sursă
2. Publicare-abonare sistem de mesagerie
În acest sistem, producătorii mesajelor sunt numiți editori, iar cei care consumă mesajele sunt abonați. Cu toate acestea, în acest domeniu, mesajele sunt schimbate printr-o destinație cunoscută ca subiect. Un editor produce mesajele la un subiect și, după ce s-au abonat la un subiect, abonații consumă mesajele din subiect. Acest sistem permite difuzarea mesajelor (având mai mult de un abonat și fiecare primește o copie a mesajelor publicate pentru un anumit subiect).
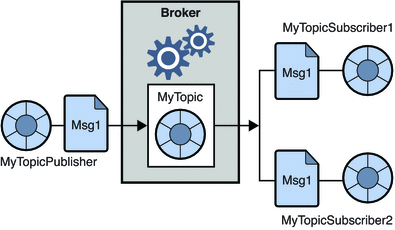
Sursă
Apache Kafka – o introducere
Apache Kafka se bazează pe un sistem de mesagerie publish-subscribe (pub-sub). În sistemul de mesagerie pub-sub, editorii sunt producătorii mesajelor, iar abonații sunt consumatorii mesajelor. În acest sistem, consumatorii pot consuma toate mesajele subiectului(e) abonat(e). Acest principiu al sistemului de mesagerie pub-sub este folosit în Apache Kafka.
În plus, Apache Kafka folosește conceptul de mesagerie distribuită, prin care există o coadă de mesaje nesincronă între sistemul de mesagerie și aplicații. Cu o coadă robustă capabilă să gestioneze un volum mare de date, Kafka vă permite să transmiteți mesaje de la un punct final la altul și este potrivit atât pentru consumul de mesaje online, cât și offline. Combinând fiabilitatea, scalabilitatea, durabilitatea și performanța de mare debit, Apache Kafka este ideal pentru integrarea și comunicarea între unități ale sistemelor de date la scară largă din lumea reală.
Citește și: Idei de proiecte Big Data
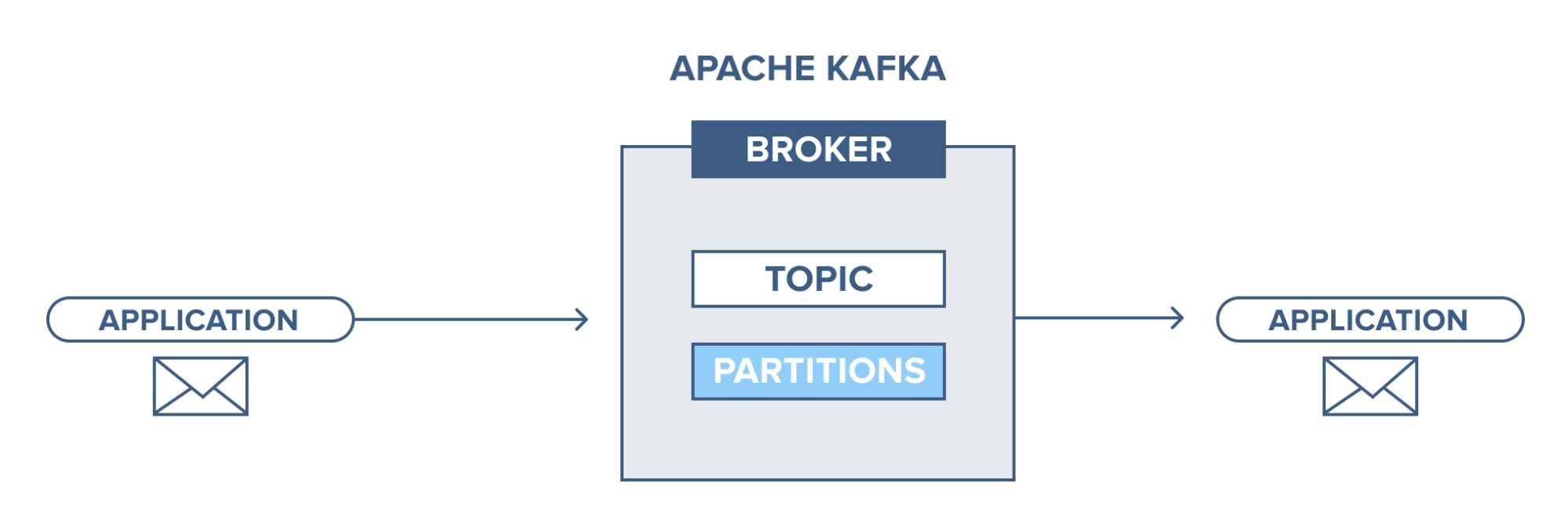
Sursă
Conceptul clusterelor Apache Kafka
Sursă
- Zookeeper Kafka : Brokerii dintr-un grup sunt coordonați și gestionați de grădinii zoo. Zookeeper informează producătorii și consumatorii despre prezența unui nou broker sau eșecul unui broker în sistemul Kafka, precum și anunță consumatorii despre valoarea compensației. Producătorii și consumatorii își coordonează activitățile cu un alt broker la primirea de la grădina zoologică.
- Broker Kafka: Brokerii Kafka sunt sisteme responsabile cu menținerea datelor publicate în clusterele Kafka cu ajutorul îngrijitorilor zoo. Un broker poate avea zero sau mai multe partiții pentru fiecare subiect.
- Producător Kafka: Mesajele despre unul sau mai multe subiecte Kafka sunt publicate de producător și transmise brokerilor, fără a aștepta confirmarea brokerului.
- Consumatorul Kafka: consumatorii extrag date de la brokeri și consumă mesaje deja publicate de la unul sau mai multe subiecte, lansează o cerere de extragere nesincronă către broker pentru a avea un buffer de octeți gata de consumat și apoi furnizează o valoare de compensare pentru a derula înapoi sau a trece la orice punct de partiție.
Concepte fundamentale ale arhitecturii Kafka
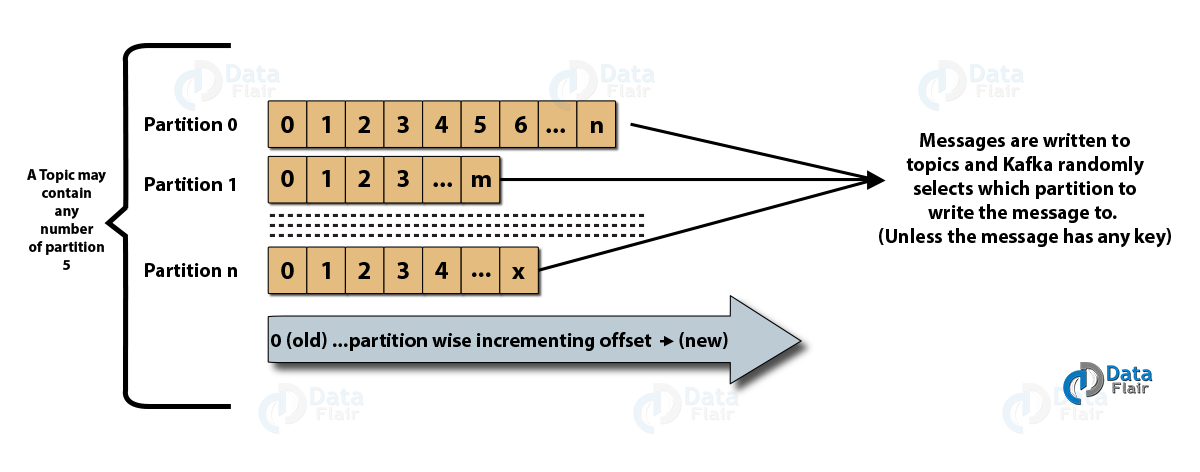
- Subiecte : Este un canal logic către care mesajele sunt publicate de producători și de la care mesajele sunt primite de consumatori. Subiectele pot fi replicate (copiate) precum și împărțite (divizate). Un anumit tip de mesaj este publicat pe un anumit subiect, fiecare subiect fiind identificabil prin numele său unic.
- Partiții de subiecte: în clusterul Kafka, subiectele sunt împărțite în partiții și sunt replicate între brokeri. Un producător poate adăuga o cheie la un mesaj publicat, iar mesajele cu aceeași cheie ajung în aceeași partiție. Fiecărui mesaj dintr-o partiție i se atribuie un ID incremental numit offset, iar aceste ID-uri sunt valide numai în cadrul partiției și nu au nicio valoare între partițiile dintr-un subiect.
- Lider și replica: Fiecare broker Kafka are câteva partiții cu fiecare partiție, fie fiind lider, fie o replică (backup) a subiectului. Liderul este responsabil nu numai de citirea și scrierea unui subiect, ci și de actualizarea replicilor cu date noi. Dacă, în orice caz, liderul eșuează, replica poate prelua ca noul lider.
Arhitectura lui Apache Kafka
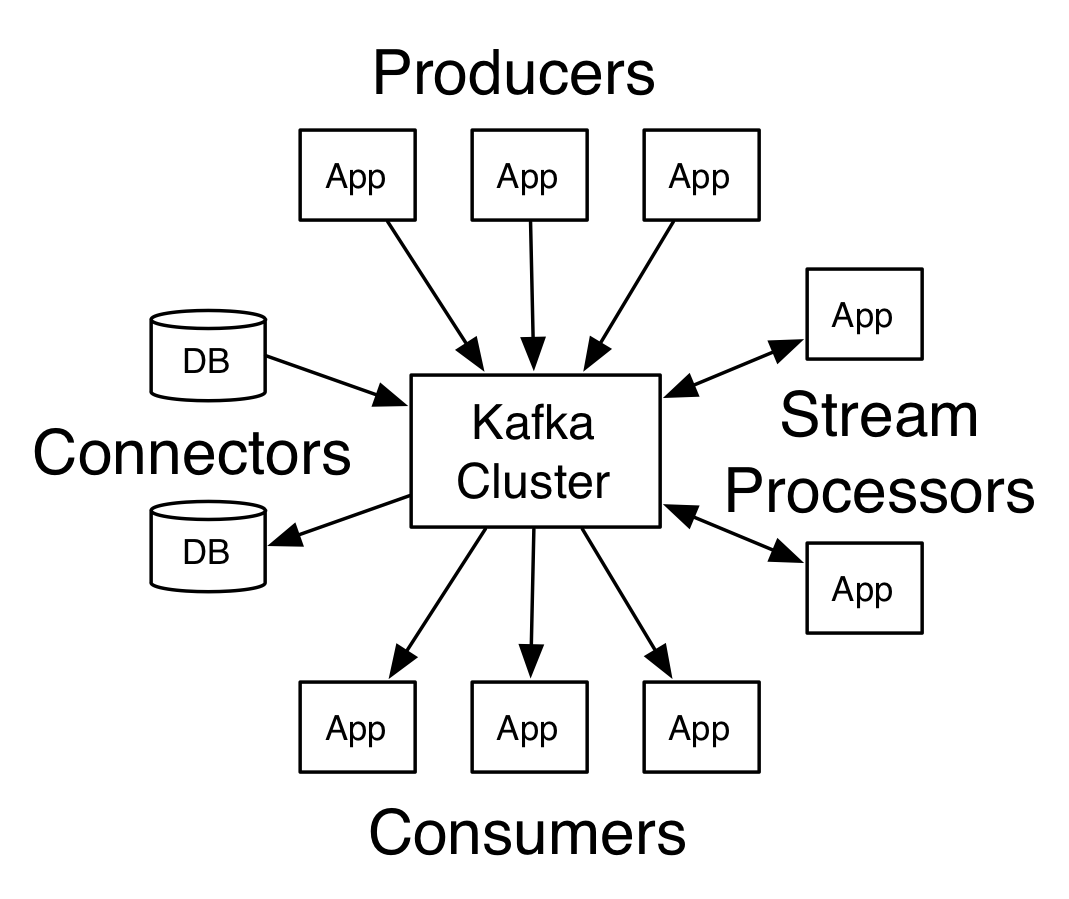
Sursă
Un Kafka care are mai mult de un broker se numește cluster Kafka. Patru dintre API-urile de bază vor fi discutate în acest tutorial Apache Kafka :
- Producer API: Kafka producer API permite ca o aplicație să publice un flux de înregistrări pentru unul sau mai multe subiecte Kafka.
- Consumer API: Consumer API permite unei aplicații să proceseze fluxul continuu de înregistrări produse pentru unul sau mai multe subiecte.
- Streams API: Streams API permite unei aplicații să consume un flux de intrare de la unul sau mai multe subiecte și să genereze un flux de ieșire la unul sau mai multe subiecte de ieșire, permițând astfel aplicației să acționeze ca un procesor de flux. Acest lucru modifică eficient fluxurile de intrare în fluxurile de ieșire.
- Connector API: Connector API permite crearea și rularea de producători și consumatori reutilizabili, permițând astfel o conexiune între subiectele Kafka și sistemele sau aplicațiile de date existente.
Fluxul de lucru al domeniului de mesagerie editor-abonat
- Producătorii Kafka trimit mesaje la un subiect la intervale regulate.
- Brokerii Kafka asigură o distribuție egală a mesajelor în cadrul partițiilor prin stocarea lor în partițiile configurate pentru un anumit subiect.
- Abonarea la un anumit subiect se face de către consumatorii Kafka. Odată ce consumatorul s-a abonat la un subiect, offset-ul curent al subiectului este oferit consumatorului, iar subiectul este salvat în ansamblul zookeeper.
- Consumatorul solicită Kafka mesaje noi la intervale regulate.
- Kafka transmite mesajele către consumatori imediat după primirea de la producători.
- Consumatorul primește mesajul și îl procesează.
- Brokerul Kafka primește o confirmare de îndată ce mesajul este procesat.
- La primirea confirmării, compensarea este actualizată la noua valoare.
- Fluxul se repetă până când consumatorul oprește cererea.
- Consumatorul poate sări peste sau să deruleze înapoi o compensare în orice moment și să citească mesajele ulterioare după comoditate.
Fluxul de lucru al sistemului de mesagerie la coadă
Într-un sistem de mesagerie la coadă, mai mulți consumatori cu același ID de grup se pot abona la un subiect. Sunt considerați un singur grup și împărtășesc mesajele. Fluxul de lucru al sistemului este:

- Producătorii Kafka trimit mesaje la un subiect la intervale regulate.
- Brokerii Kafka asigură o distribuție egală a mesajelor în cadrul partițiilor prin stocarea lor în partițiile configurate pentru un anumit subiect.
- Un singur consumator se abonează la un anumit subiect.
- Până când un nou consumator se abonează la același subiect, Kafka interacționează cu consumatorul unic.
- Odată cu venirea noilor consumatori, datele sunt partajate între doi consumatori. Partajarea se repetă până când numărul de partiții configurate pentru acel subiect este egal cu numărul de consumatori.
- Un nou consumator nu va mai primi mesaje atunci când numărul de consumatori depășește numărul de partiții configurate. Această situație apare din cauza condiției ca fiecare consumator să aibă dreptul la minim o partiție, iar dacă nicio partiție nu este goală, noii consumatori trebuie să aștepte.
2 instrumente importante în Apache Kafka
În continuare, în acest tutorial Apache Kafka , vom discuta despre instrumentele Kafka ambalate sub „org.apache.kafka.tools.*.
1. Instrumente de replicare
Este un instrument de proiectare de nivel înalt care oferă o disponibilitate mai mare și mai multă durabilitate.
- Instrument Creare subiect: Acest instrument este folosit pentru a crea un subiect cu un factor de replicare și un număr implicit de partiții și folosește schema implicită Kafka pentru a efectua o atribuire de replica.
- Instrument Listă subiecte: Informațiile pentru o anumită listă de subiecte sunt listate de acest instrument. Câmpuri precum partiția, numele subiectului, liderul, replicile și isr sunt afișate de acest instrument.
- Instrumentul Adăugați partiții: mai multe partiții pentru un anumit subiect pot fi adăugate prin acest instrument. De asemenea, efectuează atribuirea manuală a replicilor partițiilor adăugate.
2. Instrumente de sistem
Scriptul de clasă de rulare poate fi folosit pentru a rula instrumente de sistem în Kafka. Sintaxa este:
- Mirror Maker: Utilizarea acestui instrument este de a oglindi un cluster Kafka la altul.
- Instrument de migrare Kafka: Acest instrument ajută la migrarea unui broker Kafka de la o versiune la alta.
- Consumer Offset Checker: Acest instrument afișează subiectul Kafka, dimensiunea jurnalului, decalajul, partițiile, grupul de consumatori și proprietarul pentru un anumit set de subiecte.
Citește și: Tutorial Apache Pig

Top 4 cazuri de utilizare ale Apache Kafka
Să discutăm câteva cazuri importante de utilizare ale Apache Kafka în acest tutorial Apache Kafka:
- Procesarea fluxului: Caracteristica de durabilitate puternică a lui Kafka îi permite să fie utilizat în domeniul procesării fluxului. În acest caz, datele sunt citite dintr-un subiect, procesate, iar datele prelucrate sunt apoi scrise într-un subiect nou pentru a le face disponibile pentru aplicații și utilizatori.
- Metrici: Kafka este frecvent utilizat pentru monitorizarea operațională a datelor. Statisticile sunt agregate din aplicațiile distribuite pentru a realiza un flux centralizat de date operaționale.
- Urmărirea activității site-ului web: depozitele de date precum BigQuery și Google folosesc Kafka pentru urmărirea activităților de pe site-uri web. Activitățile de pe site, cum ar fi căutările, vizualizările de pagini sau alte acțiuni ale utilizatorilor, sunt publicate în subiecte centrale și sunt accesibile pentru procesare în timp real, analize offline și tablouri de bord.
- Agregarea jurnalelor: folosind Kafka, jurnalele pot fi colectate de la multe servicii și puse la dispoziție într-un format standardizat pentru mulți consumatori.
Top 5 aplicații ale Apache Kafka
Unele dintre cele mai bune aplicații industriale susținute de Kafka includ:
- Uber: aplicația de taxi are nevoie de procesare imensă în timp real și gestionează un volum uriaș de date. Procesele importante precum auditul, calculele ETA și potrivirea șoferului și clienților sunt modelate pe baza Kafka Streams.
- Netflix: Platforma de streaming pe internet la cerere Netflix utilizează valorile Kafka pentru procesarea evenimentelor și monitorizarea în timp real.
- LinkedIn: LinkedIn gestionează 7 trilioane de mesaje în fiecare zi, cu 100.000 de subiecte, 7 milioane de partiții și peste 4000 de brokeri. Apache Kafka este folosit în LinkedIn pentru urmărirea, monitorizarea și urmărirea activității utilizatorilor.
- Tinder: Această aplicație populară de întâlniri folosește Kafka Streams pentru mai multe procese care includ moderarea conținutului, recomandări, actualizarea fusului orar al utilizatorului, notificări și activarea utilizatorului, printre altele.
- Pinterest: Cu o căutare lunară de miliarde de pin și idei, Pinterest a folosit Kafka pentru multe procese. Kafka Streams sunt utilizate pentru indexarea conținutului, detectarea spam-urilor, recomandări și pentru calcularea bugetelor reclamelor în timp real.
Concluzie
În acest tutorial Apache Kafka , am discutat despre conceptele fundamentale ale Apache Kafka, arhitectura și clusterul în Kafka, fluxul de lucru Kafka, instrumentele Kafka și unele aplicații ale Kafka. Apache Kafka are unele dintre cele mai bune caracteristici, cum ar fi durabilitatea, scalabilitatea, toleranța la erori, fiabilitatea, extensibilitatea, replicarea și debitul mare, care îl fac accesibil în unele dintre cele mai bune aplicații industriale, așa cum este exemplificat în acest tutorial Apache Kafka .
Dacă sunteți interesat să aflați mai multe despre Big Data, consultați programul nostru PG Diploma în Dezvoltare Software Specializare în Big Data, care este conceput pentru profesioniști care lucrează și oferă peste 7 studii de caz și proiecte, acoperă 14 limbaje și instrumente de programare, practică practică. ateliere de lucru, peste 400 de ore de învățare riguroasă și asistență pentru plasarea unui loc de muncă cu firme de top.
Învață cursuri de dezvoltare software online de la cele mai bune universități din lume. Câștigați programe Executive PG, programe avansate de certificat sau programe de master pentru a vă accelera cariera.