
Samouczek Apache Kafka: wprowadzenie, koncepcje, przepływ pracy, narzędzia, aplikacje
Opublikowany: 2020-03-10Spis treści
Wstęp
Wraz z rosnącą popularnością Kafki jako systemu przesyłania wiadomości, wiele firm wymaga profesjonalistów posiadających solidną wiedzę na temat umiejętności Kafki, i tu przydaje się samouczek Apache Kafka. Ogromna ilość danych jest wykorzystywana w sferze Big Data, która wymaga systemu przesyłania wiadomości do gromadzenia i analizy danych.
Kafka jest wydajnym zamiennikiem tradycyjnego brokera komunikatów o ulepszonej przepustowości, nieodłącznym partycjonowaniu i replikacji oraz wbudowanej odporności na błędy, dzięki czemu nadaje się do zastosowań związanych z przetwarzaniem komunikatów na dużą skalę. Jeśli szukałeś samouczka Apache Kafka , to jest odpowiedni artykuł dla Ciebie.
Kluczowe wnioski z tego samouczka Apache Kafka
- Koncepcja systemów przesyłania wiadomości
- Krótkie wprowadzenie do Apache Kafka
- Koncepcje związane z klastrem Kafka i architekturą Kafki
- Krótki opis przepływu pracy wiadomości Kafka
- Przegląd ważnych narzędzi Kafki
- Przypadki użycia i aplikacje Apache Kafka
Dowiedz się również o: samouczku przesyłania strumieniowego Apache Spark dla początkujących
Krótki przegląd systemów przesyłania wiadomości
Główną funkcją systemu przesyłania wiadomości jest umożliwienie przesyłania danych z jednej aplikacji do drugiej; system zapewnia, że aplikacje skupiają się tylko na danych, bez zatrzymywania się podczas procesu udostępniania i transmisji danych. Istnieją dwa rodzaje systemów przesyłania wiadomości:
1. Wskaż system przesyłania wiadomości
W tym systemie producenci wiadomości nazywani są nadawcami, a odbiorcy, którzy je odbierają, są odbiorcami. W tej domenie wiadomości są wymieniane przez miejsce docelowe zwane kolejką; nadawcy lub producenci wytwarzają komunikaty do kolejki, a komunikaty są zużywane przez odbiorców z kolejki.

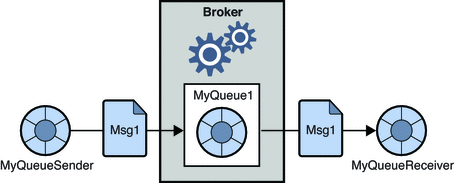
Źródło
2. System przesyłania wiadomości publikuj-subskrybuj
W tym systemie producenci wiadomości nazywani są wydawcami, a odbiorcy wiadomości są subskrybentami. Jednak w tej domenie wiadomości są wymieniane przez miejsce docelowe zwane tematem. Wydawca tworzy wiadomości do tematu i po zasubskrybowaniu tematu subskrybenci konsumują wiadomości z tego tematu. System ten umożliwia nadawanie wiadomości (mając więcej niż jednego subskrybenta i każdy otrzymuje kopię wiadomości publikowanych w określonym temacie).
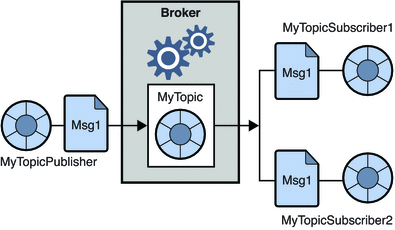
Źródło
Apache Kafka – wprowadzenie
Apache Kafka jest oparty na systemie przesyłania wiadomości typu publikuj-subskrybuj (pub-sub). W systemie wiadomości pub-sub, wydawcy są producentami wiadomości, a subskrybenci są konsumentami wiadomości. W tym systemie konsumenci mogą konsumować wszystkie wiadomości z subskrybowanych tematów. Ta zasada systemu przesyłania wiadomości pub-sub jest stosowana w Apache Kafka.
Ponadto Apache Kafka wykorzystuje koncepcję rozproszonego przesyłania wiadomości, w ramach której istnieje niesynchroniczne kolejkowanie wiadomości między systemem przesyłania wiadomości a aplikacjami. Dzięki solidnej kolejce zdolnej do obsługi dużej ilości danych, Kafka umożliwia przesyłanie wiadomości z jednego punktu końcowego do drugiego i jest przystosowana do korzystania z wiadomości zarówno w trybie online, jak i offline. Łącząc niezawodność, skalowalność, trwałość i wysoką przepustowość, Apache Kafka jest idealny do integracji i komunikacji między jednostkami wielkoskalowych systemów danych w świecie rzeczywistym.
Przeczytaj także: Pomysły na projekty Big Data
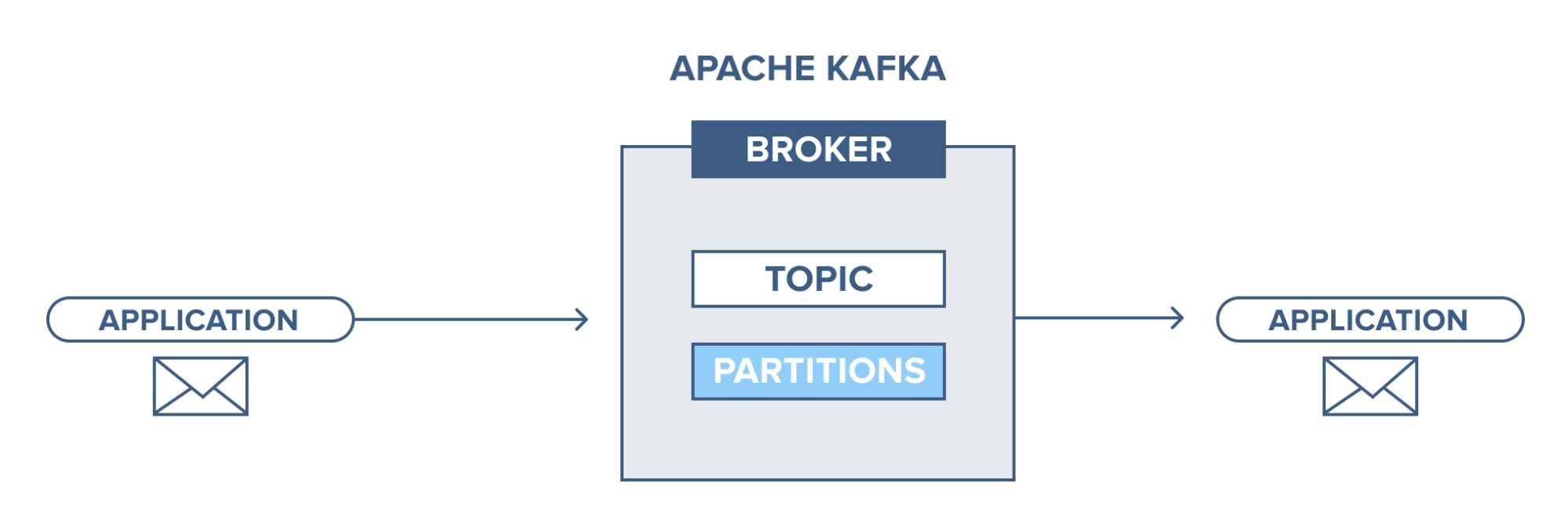
Źródło
Koncepcja klastrów Apache Kafka
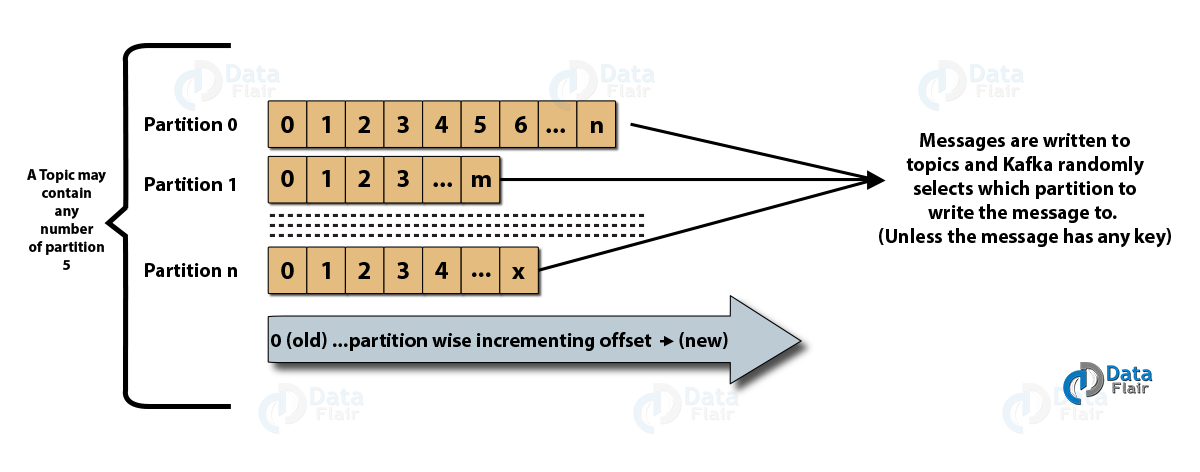
Źródło
- Kafka zookeeper : brokerzy w klastrze są koordynowani i zarządzani przez zookeeperów. Zookeeper powiadamia producentów i konsumentów o pojawieniu się nowego brokera lub awarii brokera w systemie Kafka oraz informuje konsumentów o wartości offsetu. Producenci i konsumenci koordynują swoje działania z innym pośrednikiem po otrzymaniu od zookeepera.
- Broker Kafki: Brokerzy Kafki to systemy odpowiedzialne za utrzymywanie publikowanych danych w klastrach Kafki z pomocą zookeeperów. Broker może mieć zero lub więcej partycji dla każdego tematu.
- Producent Kafka: komunikaty dotyczące jednego lub więcej niż jednego tematu Kafka są publikowane przez producenta i przesyłane do brokerów bez oczekiwania na potwierdzenie przez brokera.
- Konsument Kafki: konsumenci pobierają dane od brokerów i wykorzystują już opublikowane wiadomości z jednego lub więcej tematów, wysyłają do brokera niesynchroniczne żądanie ściągnięcia, aby mieć gotowy do użycia bufor bajtów, a następnie dostarczają wartość przesunięcia, aby przewinąć lub przejść do dowolny punkt podziału.
Podstawowe koncepcje architektury Kafki
- Tematy : Jest to kanał logiczny, na którym wiadomości publikowane są przez producentów iz którego wiadomości są odbierane przez konsumentów. Tematy mogą być replikowane (kopiowane), a także partycjonowane (dzielone). Określony rodzaj wiadomości jest publikowany na określony temat, przy czym każdy temat można zidentyfikować za pomocą unikalnej nazwy.
- Partycje tematyczne: w klastrze Kafka tematy są podzielone na partycje, a także replikowane przez brokerów. Producent może dodać klucz do opublikowanej wiadomości, a wiadomości z tym samym kluczem trafiają do tej samej partycji. Przyrostowy identyfikator o nazwie offset jest przypisywany do każdego komunikatu w partycji, a te identyfikatory są ważne tylko w obrębie partycji i nie mają wartości między partycjami w temacie.
- Lider i replika: Każdy broker Kafka ma kilka partycji z każdą partycją, która może być liderem lub repliką (kopią zapasową) tematu. Lider odpowiada nie tylko za odczytywanie i pisanie do tematu, ale także aktualizowanie replik o nowe dane. Jeśli w każdym razie lider zawiedzie, replika może przejąć rolę nowego lidera.
Architektura Apache Kafka
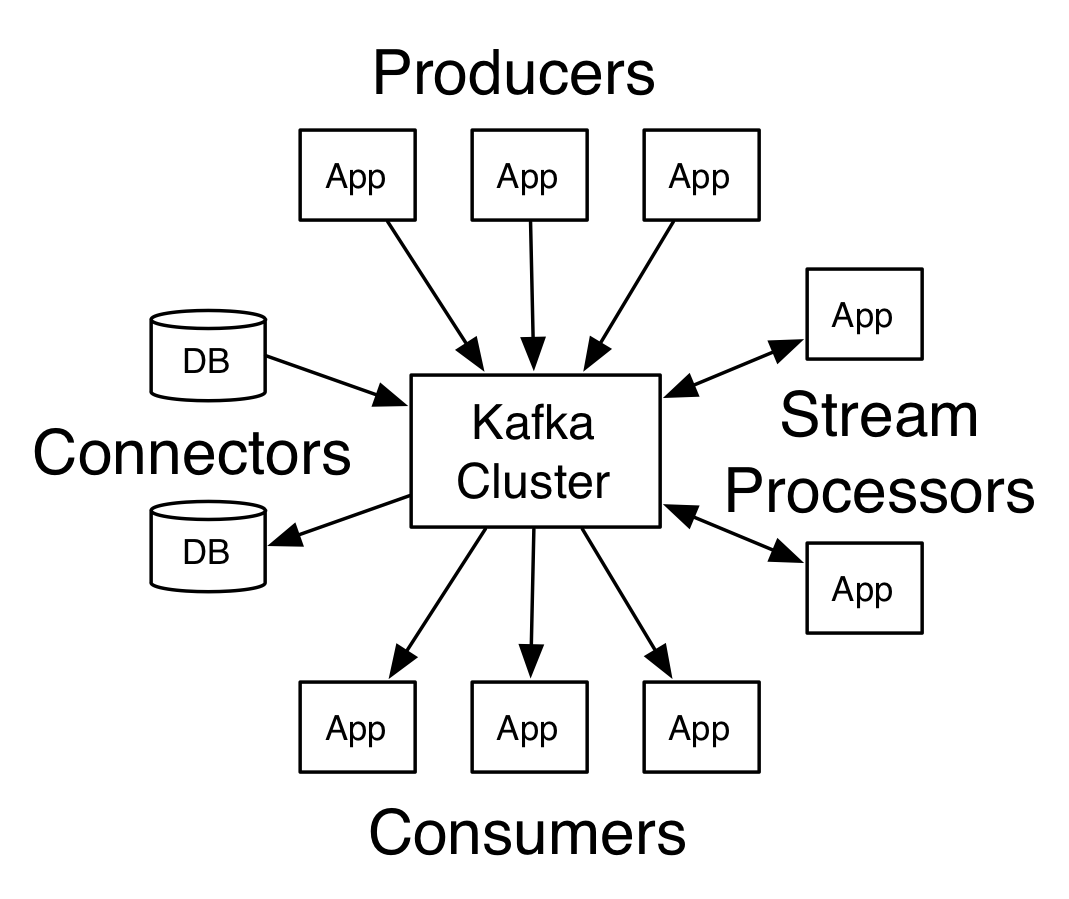
Źródło
Kafka mająca więcej niż jednego brokera nazywana jest klastrem Kafka. Cztery podstawowe interfejsy API zostaną omówione w tym samouczku Apache Kafka :
- Interfejs API producenta: interfejs API producenta Kafka umożliwia publikowanie strumienia rekordów przez aplikację w jednym lub kilku tematach Kafki.
- Consumer API: Consumer API umożliwia aplikacji przetwarzanie ciągłego przepływu rekordów tworzonych dla jednego lub większej liczby tematów.
- Streams API: Streams API umożliwia aplikacji korzystanie ze strumienia wejściowego z jednego lub kilku tematów i generowanie strumienia wyjściowego do jednego lub kilku tematów wyjściowych, dzięki czemu aplikacja może działać jako procesor strumienia. To skutecznie modyfikuje strumienie wejściowe do strumieni wyjściowych.
- Connector API: Connector API umożliwia tworzenie i uruchamianie producentów i konsumentów wielokrotnego użytku, umożliwiając w ten sposób połączenie między tematami Kafki a istniejącymi systemami danych lub aplikacjami.
Przepływ pracy domeny przesyłania wiadomości wydawca-subskrybent
- Producenci Kafki wysyłają wiadomości do tematu w regularnych odstępach czasu.
- Brokerzy Kafka zapewniają równą dystrybucję komunikatów w obrębie partycji, przechowując je w partycjach skonfigurowanych dla konkretnego tematu.
- Zapis na konkretny temat jest dokonywany przez konsumentów Kafki. Gdy konsument zasubskrybuje temat, aktualne przesunięcie tematu jest mu oferowane, a temat jest zapisywany w zespole zookeepera.
- Konsument regularnie prosi Kafkę o nowe wiadomości.
- Kafka przekazuje wiadomości konsumentom natychmiast po ich otrzymaniu od producentów.
- Konsument otrzymuje wiadomość i przetwarza ją.
- Broker Kafka otrzymuje potwierdzenie, gdy tylko wiadomość zostanie przetworzona.
- Po otrzymaniu potwierdzenia offset jest aktualizowany do nowej wartości.
- Przepływ powtarza się, dopóki konsument nie zatrzyma żądania.
- Konsument może w dowolnym momencie pominąć lub przewinąć przesunięcie i przeczytać kolejne komunikaty według własnego uznania.
Przepływ pracy systemu przesyłania wiadomości w kolejce
W systemie przesyłania komunikatów w kolejce kilku konsumentów z tym samym identyfikatorem grupy może subskrybować temat. Są uważani za jedną grupę i dzielą się wiadomościami. Przepływ pracy systemu to:

- Producenci Kafki wysyłają wiadomości do tematu w regularnych odstępach czasu.
- Brokerzy Kafka zapewniają równą dystrybucję komunikatów w obrębie partycji, przechowując je w partycjach skonfigurowanych dla konkretnego tematu.
- Pojedynczy konsument subskrybuje określony temat.
- Dopóki nowy konsument nie zasubskrybuje tego samego tematu, Kafka wchodzi w interakcję z pojedynczym konsumentem.
- Wraz z pojawieniem się nowych konsumentów dane są dzielone między dwoma konsumentami. Udostępnianie jest powtarzane, aż liczba skonfigurowanych partycji dla tego tematu będzie równa liczbie konsumentów.
- Nowy konsument nie otrzyma dalszych wiadomości, gdy liczba konsumentów przekroczy liczbę skonfigurowanych partycji. Sytuacja taka wynika z warunku, że każdemu konsumentowi przysługuje minimum jedna partycja, a jeśli żadna partycja nie jest pusta, nowi konsumenci muszą poczekać.
2 ważne narzędzia w Apache Kafka
Następnie w tym samouczku Apache Kafka omówimy narzędzia Kafki w pakiecie „org.apache.kafka.tools.*.
1. Narzędzia replikacji
Jest to narzędzie do projektowania wysokiego poziomu, które zapewnia większą dostępność i większą trwałość.
- Narzędzie Utwórz temat: To narzędzie służy do tworzenia tematu ze współczynnikiem replikacji i domyślną liczbą partycji oraz używa domyślnego schematu Kafki do przypisania repliki.
- Narzędzie Lista tematów: Informacje dla danej listy tematów są wyświetlane przez to narzędzie. Pola takie jak partycja, nazwa tematu, lider, repliki i isr są wyświetlane przez to narzędzie.
- Narzędzie dodawania partycji: za pomocą tego narzędzia można dodać więcej partycji dla określonego tematu. Wykonuje również ręczne przypisanie replik dodanych partycji.
2. Narzędzia systemowe
Skrypt run class może służyć do uruchamiania narzędzi systemowych w Kafce. Składnia to:
- Mirror Maker: Użycie tego narzędzia polega na odbiciu jednego klastra Kafki na drugim.
- Narzędzie migracji Kafka: To narzędzie pomaga w migracji brokera Kafka z jednej wersji do drugiej.
- Consumer Offset Checker: To narzędzie wyświetla temat Kafki, rozmiar dziennika, przesunięcie, partycje, grupę konsumentów i właściciela dla określonego zestawu tematów.
Przeczytaj także: Samouczek Apache Pig

4 najczęstsze przypadki użycia Apache Kafka
Omówmy kilka ważnych przypadków użycia Apache Kafka w tym samouczku Apache Kafka:
- Przetwarzanie strumieniowe: Cecha dużej trwałości Kafki pozwala na jej zastosowanie w dziedzinie przetwarzania strumieniowego. W takim przypadku dane są odczytywane z tematu, przetwarzane, a przetworzone dane są następnie zapisywane do nowego tematu w celu udostępnienia go aplikacjom i użytkownikom.
- Metryki: Kafka jest często używany do operacyjnego monitorowania danych. Statystyki są agregowane z aplikacji rozproszonych w celu stworzenia scentralizowanego źródła danych operacyjnych.
- Śledzenie aktywności w witrynie: hurtownie danych, takie jak BigQuery i Google, wykorzystują Kafkę do śledzenia aktywności w witrynach. Działania w witrynie, takie jak wyszukiwania, wyświetlenia stron lub inne działania użytkowników, są publikowane w centralnych tematach i udostępniane do przetwarzania w czasie rzeczywistym, analizy offline i pulpitów nawigacyjnych.
- Agregacja logów: za pomocą Kafki można zbierać logi z wielu usług i udostępniać je w standardowym formacie wielu konsumentom.
5 najlepszych zastosowań Apache Kafka
Niektóre z najlepszych aplikacji przemysłowych obsługiwanych przez Kafkę to:
- Uber: aplikacja cab wymaga ogromnego przetwarzania w czasie rzeczywistym i obsługuje ogromne ilości danych. Ważne procesy, takie jak audyt, obliczenia ETA oraz dopasowanie sterowników i klientów, są modelowane w oparciu o strumienie Kafka.
- Netflix: platforma internetowego streamingu na żądanie Netflix wykorzystuje metryki Kafki do przetwarzania zdarzeń i monitorowania w czasie rzeczywistym.
- LinkedIn: LinkedIn zarządza 7 bilionami wiadomości każdego dnia, ze 100 000 tematów, 7 milionami partycji i ponad 4000 brokerów. Apache Kafka jest używany na LinkedIn do śledzenia, monitorowania i śledzenia aktywności użytkowników.
- Tinder: Ta popularna aplikacja randkowa wykorzystuje Kafka Streams do kilku procesów, które obejmują między innymi moderację treści, rekomendacje, aktualizację strefy czasowej użytkownika, powiadomienia i aktywację użytkownika.
- Pinterest: dzięki comiesięcznemu przeszukiwaniu miliardów pinów i pomysłów, Pinterest wykorzystał Kafkę do wielu procesów. Strumienie Kafki są wykorzystywane do indeksowania treści, wykrywania spamu, rekomendacji oraz do obliczania budżetów reklam w czasie rzeczywistym.
Wniosek
W tym samouczku Apache Kafka omówiliśmy podstawowe koncepcje Apache Kafka, architekturę i klaster w Kafce, przepływ pracy Kafka, narzędzia Kafki i niektóre aplikacje Kafki. Apache Kafka ma jedne z najlepszych funkcji, takich jak trwałość, skalowalność, odporność na awarie, niezawodność, rozszerzalność, replikacja i wysoka przepustowość, dzięki którym jest dostępny w niektórych z najlepszych aplikacji przemysłowych, czego przykładem jest ten samouczek Apache Kafka .
Jeśli chcesz dowiedzieć się więcej o Big Data, sprawdź nasz program PG Diploma in Software Development Specialization in Big Data, który jest przeznaczony dla pracujących profesjonalistów i zawiera ponad 7 studiów przypadków i projektów, obejmuje 14 języków programowania i narzędzi, praktyczne praktyczne warsztaty, ponad 400 godzin rygorystycznej pomocy w nauce i pośrednictwie pracy w najlepszych firmach.
Ucz się kursów rozwoju oprogramowania online z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.