
Tutorial Apache Kafka: Pengenalan, Konsep, Alur Kerja, Alat, Aplikasi
Diterbitkan: 2020-03-10Daftar isi
pengantar
Dengan meningkatnya popularitas Kafka sebagai sistem pesan, banyak perusahaan menuntut profesional dengan pengetahuan yang baik tentang keterampilan Kafka, dan di situlah Tutorial Apache Kafka berguna. Sejumlah besar data digunakan di ranah Big Data yang membutuhkan sistem pengiriman pesan untuk pengumpulan dan analisis data.
Kafka adalah pengganti yang efisien dari broker pesan konvensional dengan peningkatan throughput, partisi dan replikasi yang melekat dan toleransi kesalahan built-in, sehingga cocok untuk aplikasi pemrosesan pesan dalam skala besar. Jika Anda sedang mencari Tutorial Apache Kafka , ini adalah artikel yang tepat untuk Anda.
Takeaways utama dari Tutorial Apache Kafka ini
- Konsep sistem pesan
- Pengantar singkat untuk Apache Kafka
- Konsep yang terkait dengan klaster Kafka dan arsitektur Kafka
- Deskripsi singkat tentang alur kerja pengiriman pesan Kafka
- Ikhtisar alat Kafka penting
- Kasus penggunaan dan aplikasi Apache Kafka
Pelajari juga tentang: Tutorial Streaming Apache Spark Untuk Pemula
Tinjauan singkat tentang sistem perpesanan
Fungsi utama dari sistem pesan adalah untuk memungkinkan transfer data dari satu aplikasi ke aplikasi lain; sistem memastikan bahwa aplikasi hanya fokus pada data tanpa terhenti selama proses berbagi dan transmisi data. Ada dua jenis sistem pesan:
1. Sistem pesan titik ke titik
Dalam sistem ini, pembuat pesan disebut pengirim dan yang mengkonsumsi pesan disebut penerima. Dalam domain ini, pesan dipertukarkan melalui tujuan yang dikenal sebagai antrian; pengirim atau produsen menghasilkan pesan ke antrian, dan pesan dikonsumsi oleh penerima dari antrian.

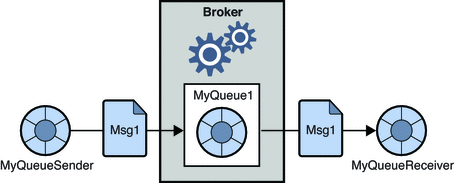
Sumber
2. Terbitkan-berlangganan sistem pesan
Dalam sistem ini, produsen pesan disebut penerbit dan yang mengkonsumsi pesan adalah pelanggan. Namun, dalam domain ini, pesan dipertukarkan melalui tujuan yang dikenal sebagai topik. Penerbit menghasilkan pesan untuk suatu topik dan setelah berlangganan suatu topik, pelanggan mengkonsumsi pesan dari topik tersebut. Sistem ini memungkinkan penyiaran pesan (memiliki lebih dari satu pelanggan dan masing-masing mendapat salinan pesan yang diterbitkan untuk topik tertentu).
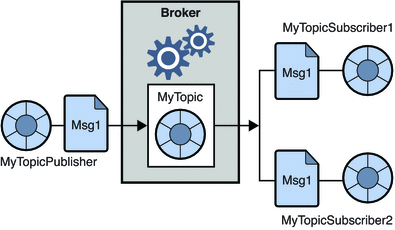
Sumber
Apache Kafka – sebuah pengantar
Apache Kafka didasarkan pada sistem pesan publish-subscribe (pub-sub). Dalam sistem pesan pub-sub, penerbit adalah produsen pesan, dan pelanggan adalah konsumen pesan. Dalam sistem ini, konsumen dapat mengkonsumsi semua pesan dari topik yang dilanggan. Prinsip sistem perpesanan pub-sub ini digunakan di Apache Kafka.
Selain itu, Apache Kafka menggunakan konsep perpesanan terdistribusi, di mana terdapat antrian pesan yang tidak sinkron antara sistem perpesanan dan aplikasi. Dengan antrian yang kuat yang mampu menangani volume data yang besar, Kafka memungkinkan Anda untuk mengirimkan pesan dari satu titik akhir ke titik akhir lainnya dan cocok untuk konsumsi pesan online dan offline. Menggabungkan keandalan, skalabilitas, daya tahan, dan kinerja throughput tinggi, Apache Kafka sangat ideal untuk integrasi dan komunikasi antar unit sistem data skala besar di dunia nyata.
Baca juga: Ide Proyek Big Data
Sumber
Konsep cluster Apache Kafka
Sumber
- Kafka Zookeeper : Broker dalam sebuah cluster dikoordinasikan dan dikelola oleh zookeepers. Zookeeper memberi tahu produsen dan konsumen tentang keberadaan broker baru atau kegagalan broker dalam sistem Kafka serta memberi tahu konsumen tentang nilai offset. Produsen dan konsumen mengkoordinasikan kegiatan mereka dengan broker lain pada penerimaan dari penjaga kebun binatang.
- Pialang Kafka: Pialang Kafka adalah sistem yang bertanggung jawab untuk memelihara data yang dipublikasikan di klaster Kafka dengan bantuan penjaga kebun binatang. Pialang mungkin memiliki nol atau lebih partisi untuk setiap topik.
- Produser Kafka: Pesan pada satu atau lebih dari satu topik Kafka diterbitkan oleh produser dan dikirim ke broker, tanpa menunggu pengakuan broker.
- Konsumen Kafka: Konsumen mengekstrak data dari broker dan mengkonsumsi pesan yang sudah diterbitkan dari satu atau lebih topik, mengeluarkan permintaan tarik non-sinkron ke broker untuk memiliki buffer byte siap pakai dan kemudian memasok nilai offset untuk mundur atau melompat ke setiap titik partisi.
Konsep dasar arsitektur Kafka
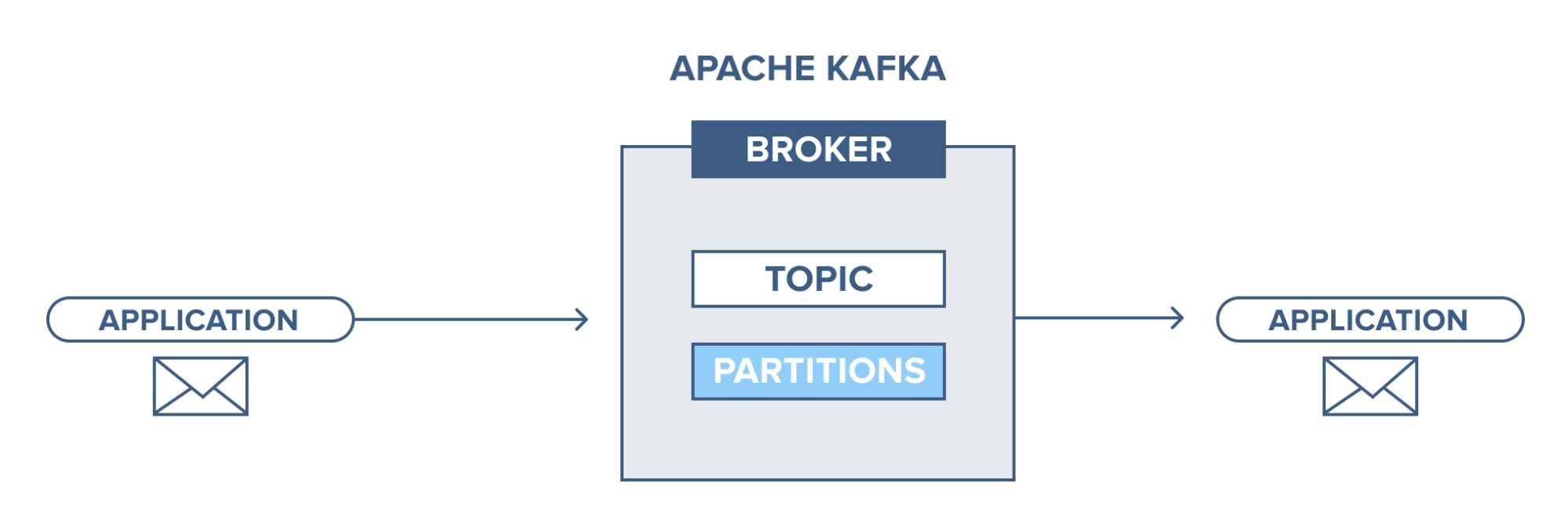
- Topik : Ini adalah saluran logis di mana pesan diterbitkan oleh produsen dan dari mana pesan diterima oleh konsumen. Topik dapat direplikasi (disalin) maupun dipartisi (dibagi). Jenis pesan tertentu diterbitkan tentang topik tertentu, dengan setiap topik dapat diidentifikasi dengan nama uniknya.
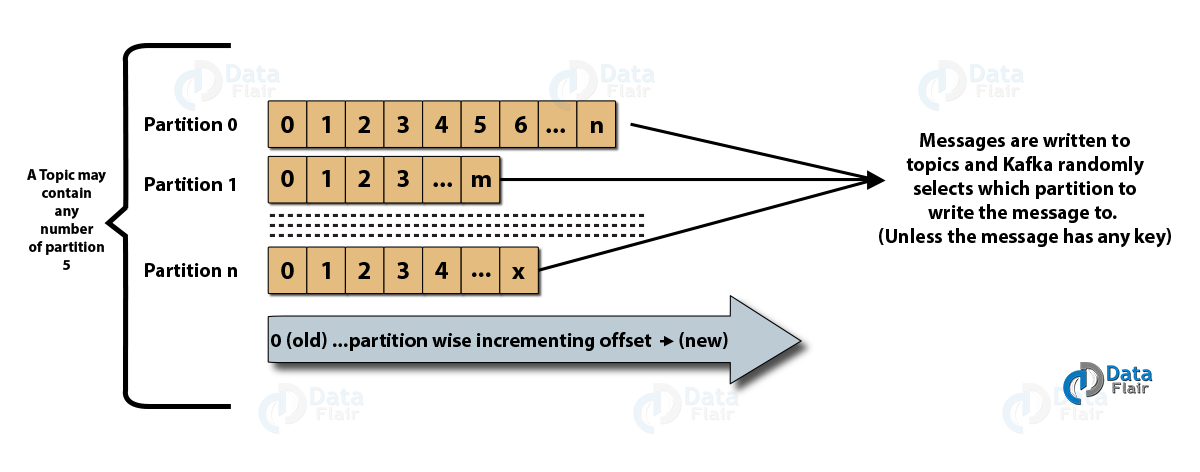
- Partisi topik: Di klaster Kafka, topik dibagi menjadi beberapa partisi serta direplikasi di seluruh broker. Produser dapat menambahkan kunci ke pesan yang diterbitkan, dan pesan dengan kunci yang sama akan berakhir di partisi yang sama. ID tambahan yang disebut offset ditetapkan ke setiap pesan dalam partisi, dan ID ini hanya valid di dalam partisi dan tidak memiliki nilai di seluruh partisi dalam suatu topik.
- Pemimpin dan replika: Setiap broker Kafka memiliki beberapa partisi dengan setiap partisi, baik menjadi pemimpin atau replika (cadangan) topik. Pemimpin bertanggung jawab tidak hanya untuk membaca dan menulis suatu topik tetapi juga memperbarui replika dengan data baru. Jika, bagaimanapun, pemimpin gagal, replika dapat mengambil alih sebagai pemimpin baru.
Arsitektur Apache Kafka
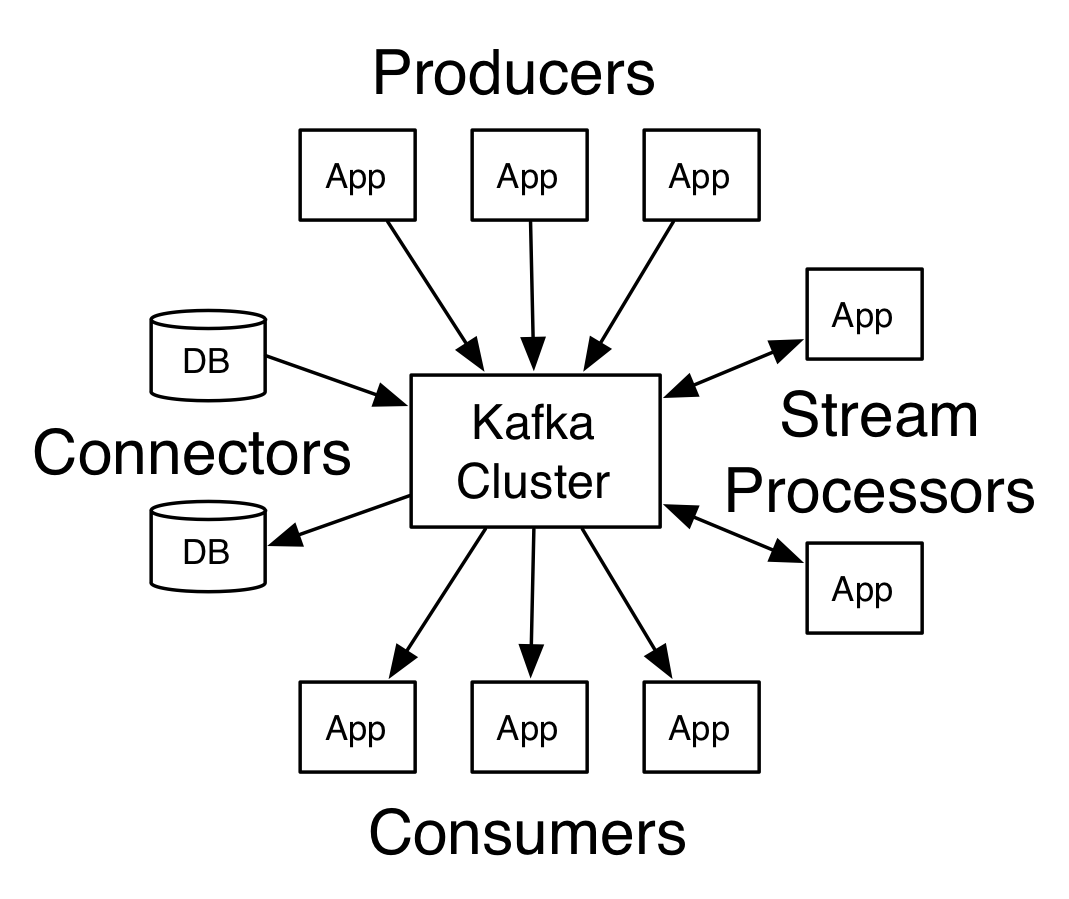
Sumber
Kafka yang memiliki lebih dari satu broker disebut klaster Kafka. Empat API inti akan dibahas dalam Tutorial Apache Kafka ini :
- Producer API: API produser Kafka memungkinkan aliran rekaman diterbitkan oleh aplikasi ke satu atau beberapa topik Kafka.
- API Konsumen: API konsumen memungkinkan aplikasi memproses aliran rekaman yang berkelanjutan yang dihasilkan ke satu atau beberapa topik.
- Streams API: Streams API memungkinkan aplikasi untuk menggunakan aliran input dari satu atau beberapa topik dan menghasilkan aliran output ke satu atau beberapa topik output, sehingga memungkinkan aplikasi untuk bertindak sebagai pemroses aliran. Ini secara efisien memodifikasi aliran input ke aliran output.
- API Konektor: API konektor memungkinkan pembuatan dan pengoperasian produsen dan konsumen yang dapat digunakan kembali, sehingga memungkinkan koneksi antara topik Kafka dan sistem atau aplikasi data yang ada.
Alur kerja domain perpesanan penerbit-pelanggan
- Produsen Kafka mengirim pesan ke suatu topik secara berkala.
- Pialang Kafka memastikan distribusi pesan yang merata di dalam partisi dengan menyimpannya di partisi yang dikonfigurasi untuk topik tertentu.
- Berlangganan topik tertentu dilakukan oleh konsumen Kafka. Setelah konsumen berlangganan suatu topik, offset topik saat ini ditawarkan kepada konsumen, dan topik tersebut disimpan dalam ansambel penjaga kebun binatang.
- Konsumen meminta Kafka untuk pesan baru secara berkala.
- Kafka meneruskan pesan ke konsumen segera setelah diterima dari produsen.
- Konsumen menerima pesan dan memprosesnya.
- Broker Kafka mendapat pengakuan segera setelah pesan diproses.
- Pada penerimaan pengakuan, offset ditingkatkan ke nilai baru.
- Alur berulang sampai konsumen menghentikan permintaan.
- Konsumen dapat melewati atau memundurkan offset kapan saja dan membaca pesan berikutnya sesuai kenyamanan.
Alur kerja sistem pesan antrian
Dalam sistem pesan antrian, beberapa konsumen dengan ID grup yang sama dapat berlangganan suatu topik. Mereka dianggap sebagai satu grup dan berbagi pesan. Alur kerja dari sistem ini adalah:

- Produsen Kafka mengirim pesan ke suatu topik secara berkala.
- Pialang Kafka memastikan distribusi pesan yang merata di dalam partisi dengan menyimpannya di partisi yang dikonfigurasi untuk topik tertentu.
- Seorang konsumen tunggal berlangganan topik tertentu.
- Sampai konsumen baru berlangganan topik yang sama, Kafka berinteraksi dengan konsumen tunggal.
- Dengan kedatangan konsumen baru, data dibagi antara dua konsumen. Pembagian ini diulang hingga jumlah partisi yang dikonfigurasi untuk topik tersebut sama dengan jumlah konsumen.
- Konsumen baru tidak akan menerima pesan lebih lanjut ketika jumlah konsumen melebihi jumlah partisi yang dikonfigurasi. Situasi ini muncul karena kondisi bahwa setiap konsumen berhak mendapatkan minimal satu partisi, dan jika tidak ada partisi yang kosong, konsumen baru harus menunggu.
2 alat penting di Apache Kafka
Selanjutnya, dalam Tutorial Apache Kafka ini , kita akan membahas tools Kafka yang dikemas dalam “org.apache.kafka.tools.*.
1. Alat Replikasi
Ini adalah alat desain tingkat tinggi yang memberikan ketersediaan lebih tinggi dan daya tahan lebih.
- Alat Buat Topik: Alat ini digunakan untuk membuat topik dengan faktor replikasi dan jumlah partisi default dan menggunakan skema default Kafka untuk melakukan tugas replika.
- Alat Daftar Topik: Informasi untuk daftar topik tertentu didaftar oleh alat ini. Bidang seperti partisi, nama topik, pemimpin, replika dan isr ditampilkan oleh alat ini.
- Add Partition tool: Lebih banyak partisi untuk topik tertentu dapat ditambahkan oleh alat ini. Itu juga melakukan tugas manual replika partisi yang ditambahkan.
2. Alat sistem
Skrip kelas run dapat digunakan untuk menjalankan alat sistem di Kafka. Sintaksnya adalah:
- Pembuat Cermin: Penggunaan alat ini adalah untuk mencerminkan satu cluster Kafka ke yang lain.
- Alat Migrasi Kafka: Alat ini membantu dalam memigrasikan broker Kafka dari satu versi ke versi lainnya.
- Pemeriksa Offset Konsumen: Alat ini menampilkan topik Kafka, ukuran log, offset, partisi, grup konsumen, dan pemilik untuk rangkaian topik tertentu.
Baca Juga: Tutorial Babi Apache

4 kasus penggunaan teratas Apache Kafka
Mari kita bahas beberapa kasus penggunaan penting Apache Kafka dalam Tutorial Apache Kafka ini:
- Pemrosesan aliran: Fitur daya tahan yang kuat dari Kafka memungkinkannya untuk digunakan di bidang pemrosesan aliran. Dalam hal ini, data dibaca dari suatu topik, diproses dan data yang diproses kemudian ditulis ke topik baru agar tersedia untuk aplikasi dan pengguna.
- Metrik: Kafka sering digunakan untuk pemantauan operasional data. Statistik dikumpulkan dari aplikasi terdistribusi untuk membuat umpan data operasional terpusat.
- Melacak aktivitas situs web: Gudang data seperti BigQuery dan Google menggunakan Kafka untuk melacak aktivitas di situs web. Aktivitas situs seperti penelusuran, tampilan halaman, atau tindakan pengguna lainnya dipublikasikan ke topik utama dan dapat diakses untuk pemrosesan waktu nyata, analisis offline, dan dasbor.
- Agregasi log: Menggunakan Kafka, log dapat dikumpulkan dari banyak layanan dan tersedia dalam format standar untuk banyak konsumen.
5 Aplikasi Teratas Apache Kafka
Beberapa aplikasi industri terbaik yang didukung oleh Kafka antara lain:
- Uber: Aplikasi taksi membutuhkan pemrosesan real-time yang sangat besar dan menangani volume data yang sangat besar. Proses penting seperti audit, perhitungan ETA, dan pencocokan driver dan pelanggan dimodelkan berdasarkan Kafka Streams.
- Netflix: Platform streaming internet sesuai permintaan Netflix menggunakan metrik Kafka untuk memproses acara dan pemantauan waktu nyata.
- LinkedIn: LinkedIn mengelola 7 triliun pesan setiap hari, dengan 100.000 topik, 7 juta partisi, dan lebih dari 4000 broker. Apache Kafka digunakan di LinkedIn untuk pelacakan, pemantauan, dan pelacakan aktivitas pengguna.
- Tinder: Aplikasi kencan populer ini menggunakan Kafka Streams untuk beberapa proses yang mencakup moderasi konten, rekomendasi, memperbarui zona waktu pengguna, notifikasi, dan aktivasi pengguna, antara lain.
- Pinterest: Dengan pencarian bulanan miliaran pin dan ide, Pinterest telah memanfaatkan Kafka untuk banyak proses. Kafka Streams digunakan untuk mengindeks konten, mendeteksi spam, rekomendasi, dan untuk menghitung anggaran iklan waktu nyata.
Kesimpulan
Dalam Tutorial Apache Kafka ini , kita telah membahas konsep dasar Apache Kafka, arsitektur dan cluster di Kafka, alur kerja Kafka, alat Kafka dan beberapa aplikasi Kafka. Apache Kafka memiliki beberapa fitur terbaik seperti daya tahan, skalabilitas, toleransi kesalahan, keandalan, ekstensibilitas, replikasi, dan throughput tinggi yang membuatnya dapat diakses di beberapa aplikasi industri terbaik, seperti yang dicontohkan dalam Tutorial Apache Kafka ini .
Jika Anda tertarik untuk mengetahui lebih banyak tentang Big Data, lihat Diploma PG kami dalam Spesialisasi Pengembangan Perangkat Lunak dalam program Big Data yang dirancang untuk para profesional yang bekerja dan menyediakan 7+ studi kasus & proyek, mencakup 14 bahasa & alat pemrograman, praktik langsung lokakarya, lebih dari 400 jam pembelajaran yang ketat & bantuan penempatan kerja dengan perusahaan-perusahaan top.
Pelajari Kursus Pengembangan Perangkat Lunak online dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.