
บทช่วยสอน Apache Kafka: บทนำ แนวคิด เวิร์กโฟลว์ เครื่องมือ แอปพลิเคชัน
เผยแพร่แล้ว: 2020-03-10สารบัญ
บทนำ
ด้วยความนิยมที่เพิ่มขึ้นของ Kafka ในฐานะระบบการส่งข้อความ บริษัทจำนวนมากต้องการผู้เชี่ยวชาญที่มีความรู้ด้านทักษะของ Kafka และนั่นคือที่ที่ Apache Kafka Tutorial มีประโยชน์ ข้อมูลจำนวนมหาศาลถูกใช้ในขอบเขตของ Big Data ที่ต้องการระบบการส่งข้อความสำหรับการรวบรวมและวิเคราะห์ข้อมูล
Kafka เป็นการแทนที่ที่มีประสิทธิภาพของโบรกเกอร์ข้อความทั่วไปด้วยปริมาณงานที่ได้รับการปรับปรุง การแบ่งพาร์ติชันและการจำลองแบบโดยธรรมชาติ และความทนทานต่อข้อผิดพลาดในตัว ทำให้เหมาะสำหรับแอปพลิเคชันการประมวลผลข้อความในขนาดใหญ่ หากคุณกำลังมองหา Apache Kafka Tutorial นี่เป็นบทความที่เหมาะสมสำหรับคุณ
ประเด็นสำคัญของ บทช่วยสอน Apache Kafka นี้
- แนวคิดของระบบส่งข้อความ
- ข้อมูลเบื้องต้นเกี่ยวกับ Apache Kafka
- แนวคิดที่เกี่ยวข้องกับคลัสเตอร์คาฟคาและสถาปัตยกรรมคาฟคา
- คำอธิบายสั้น ๆ ของเวิร์กโฟลว์การส่งข้อความ Kafka
- ภาพรวมของเครื่องมือ Kafka ที่สำคัญ
- ใช้กรณีและแอปพลิเคชันของ Apache Kafka
เรียนรู้เพิ่มเติมเกี่ยวกับ: บทแนะนำการสตรีม Apache Spark สำหรับผู้เริ่มต้น
ภาพรวมโดยย่อของระบบการส่งข้อความ
หน้าที่หลักของระบบส่งข้อความคืออนุญาตให้ถ่ายโอนข้อมูลจากแอปพลิเคชันหนึ่งไปยังอีกแอปพลิเคชันหนึ่ง ระบบทำให้มั่นใจได้ว่าแอปพลิเคชันจะเน้นที่ข้อมูลเท่านั้นโดยไม่หยุดชะงักระหว่างกระบวนการแบ่งปันและส่งข้อมูล ระบบการส่งข้อความมีสองประเภท:
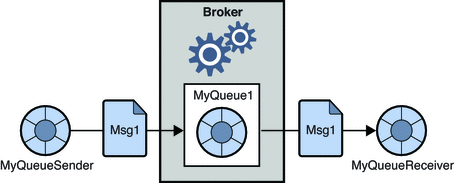
1. ระบบส่งข้อความแบบชี้ไปที่จุด
ในระบบนี้ ผู้ผลิตข้อความจะเรียกว่าผู้ส่ง และผู้ที่ใช้ข้อความคือผู้รับ ในโดเมนนี้ ข้อความจะถูกแลกเปลี่ยนผ่านปลายทางที่เรียกว่าคิว ผู้ส่งหรือผู้ผลิตสร้างข้อความไปยังคิว และข้อความจะถูกใช้โดยผู้รับจากคิว

แหล่งที่มา
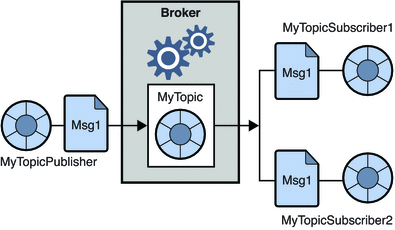
2. เผยแพร่-สมัครสมาชิกระบบข้อความ
ในระบบนี้ ผู้ผลิตข้อความจะเรียกว่าผู้เผยแพร่และผู้ที่ใช้ข้อความคือสมาชิก อย่างไรก็ตาม ในโดเมนนี้ ข้อความจะถูกแลกเปลี่ยนผ่านปลายทางที่เรียกว่าหัวข้อ ผู้จัดพิมพ์สร้างข้อความไปยังหัวข้อและสมัครรับข้อมูลจากหัวข้อ สมาชิกใช้ข้อความจากหัวข้อ ระบบนี้อนุญาตให้เผยแพร่ข้อความ (มีสมาชิกมากกว่าหนึ่งคนและแต่ละคนจะได้รับสำเนาของข้อความที่เผยแพร่ไปยังหัวข้อใดหัวข้อหนึ่ง)
แหล่งที่มา
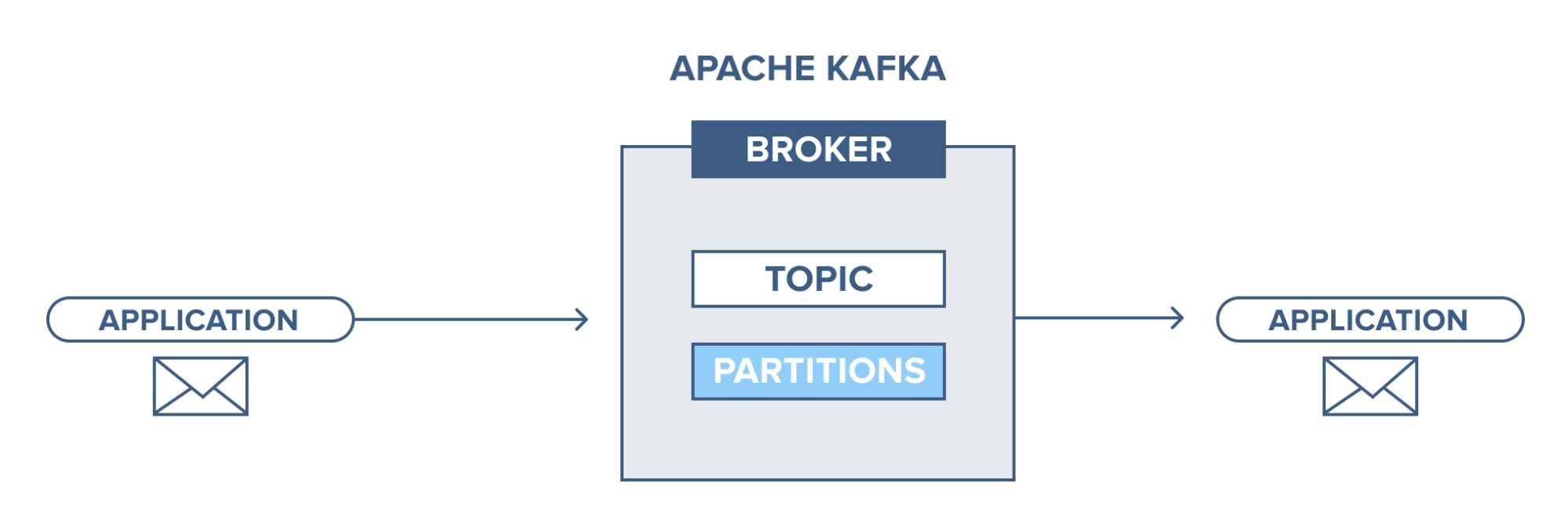
Apache Kafka – บทนำ
Apache Kafka ใช้ระบบส่งข้อความแบบเผยแพร่สมัครสมาชิก (pub-sub) ในระบบการส่งข้อความแบบผับ-ย่อย ผู้เผยแพร่คือผู้ผลิตข้อความ และสมาชิกคือผู้บริโภคข้อความ ในระบบนี้ ผู้บริโภคสามารถใช้ข้อความทั้งหมดของหัวข้อที่สมัครรับข้อมูล หลักการของระบบการส่งข้อความแบบผับย่อยนี้ใช้ใน Apache Kafka
นอกจากนี้ Apache Kafka ยังใช้แนวคิดของการส่งข้อความแบบกระจายด้วยเหตุนี้จึงมีการจัดคิวข้อความแบบไม่ซิงโครนัสระหว่างระบบส่งข้อความและแอปพลิเคชัน ด้วยคิวที่แข็งแกร่งซึ่งสามารถจัดการข้อมูลปริมาณมาก Kafka ช่วยให้คุณสามารถส่งข้อความจากจุดสิ้นสุดที่หนึ่งไปยังอีกจุดหนึ่ง และเหมาะสมกับการใช้ข้อความทั้งแบบออนไลน์และออฟไลน์ การรวมความน่าเชื่อถือ ความสามารถในการปรับขนาด ความทนทาน และประสิทธิภาพการรับส่งข้อมูลสูง Apache Kafka เหมาะอย่างยิ่งสำหรับการผสานรวมและการสื่อสารระหว่างหน่วยของระบบข้อมูลขนาดใหญ่ในโลกแห่งความเป็นจริง
อ่านเพิ่มเติม: แนวคิดโครงการข้อมูลขนาดใหญ่
แหล่งที่มา
แนวคิดของคลัสเตอร์ Apache Kafka
แหล่งที่มา
- ผู้ดูแลสวนสัตว์คาฟคา : นายหน้าในกลุ่มได้รับการประสานงานและจัดการโดยผู้ดูแลสวนสัตว์ Zookeeper แจ้งผู้ผลิตและผู้บริโภคเกี่ยวกับการมีอยู่ของนายหน้ารายใหม่หรือความล้มเหลวของนายหน้าในระบบ Kafka ตลอดจนแจ้งผู้บริโภคเกี่ยวกับค่าชดเชย ผู้ผลิตและผู้บริโภคประสานงานกิจกรรมกับนายหน้ารายอื่นในการรับจากผู้ดูแลสวนสัตว์
- นายหน้า Kafka: นายหน้า Kafka เป็นระบบที่รับผิดชอบในการรักษาข้อมูลที่เผยแพร่ในกลุ่ม Kafka ด้วยความช่วยเหลือจากผู้ดูแลสวนสัตว์ นายหน้าอาจมีพาร์ติชั่นเป็นศูนย์หรือมากกว่าสำหรับแต่ละหัวข้อ
- ผู้ผลิต Kafka: ข้อความในหัวข้อ Kafka อย่างน้อยหนึ่งหัวข้อเผยแพร่โดยผู้ผลิตและส่งต่อไปยังนายหน้าโดยไม่ต้องรอการรับทราบจากนายหน้า
- ผู้บริโภค Kafka: ผู้บริโภคดึงข้อมูลจากโบรกเกอร์และใช้ข้อความที่เผยแพร่แล้วจากหัวข้อหนึ่งหรือหลายหัวข้อ ออกคำขอดึงแบบไม่ซิงโครนัสไปยังนายหน้าเพื่อให้พร้อมที่จะใช้บัฟเฟอร์ของไบต์จากนั้นให้ค่าชดเชยเพื่อกรอกลับหรือข้ามไป จุดแบ่งส่วนใด ๆ
แนวคิดพื้นฐานของสถาปัตยกรรมคาฟคา
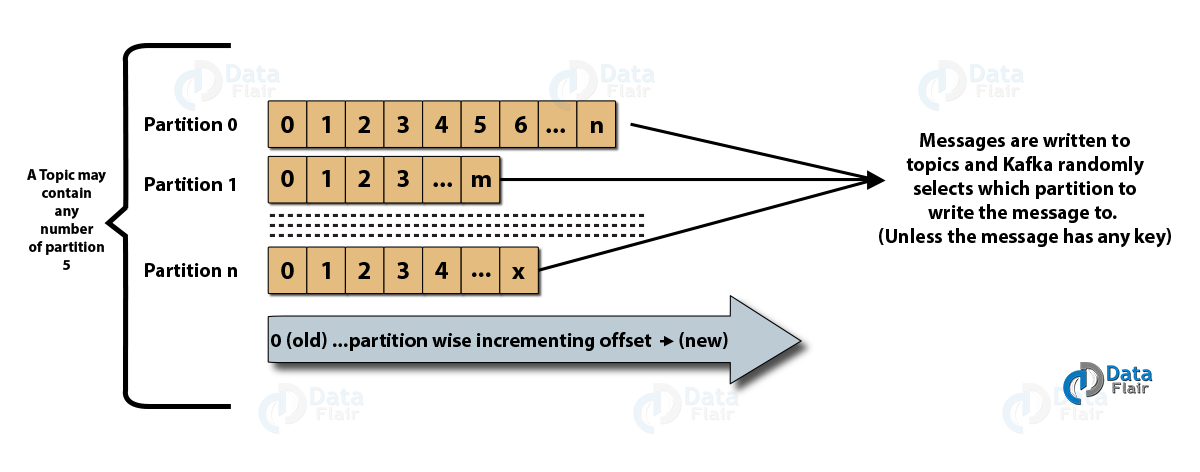
- หัวข้อ : เป็นช่องทางตรรกะที่ข้อความถูกเผยแพร่โดยผู้ผลิต และได้รับข้อความจากผู้บริโภค หัวข้อสามารถทำซ้ำ (คัดลอก) เช่นเดียวกับแบ่งพาร์ติชัน (แบ่ง) ข้อความประเภทใดประเภทหนึ่งถูกเผยแพร่ในหัวข้อใดหัวข้อหนึ่ง โดยแต่ละหัวข้อสามารถระบุได้ด้วยชื่อเฉพาะ
- พาร์ติชั่นหัวข้อ: ในคลัสเตอร์ Kafka หัวข้อจะถูกแบ่งออกเป็นพาร์ติชั่นและจำลองแบบข้ามโบรกเกอร์ ผู้ผลิตสามารถเพิ่มคีย์ให้กับข้อความที่เผยแพร่ และข้อความที่มีคีย์เดียวกันจะจบลงในพาร์ติชั่นเดียวกัน ID ส่วนเพิ่มที่เรียกว่า offset ถูกกำหนดให้กับแต่ละข้อความในพาร์ติชั่น และ ID เหล่านี้ใช้ได้เฉพาะภายในพาร์ติชั่นเท่านั้น และไม่มีค่าข้ามพาร์ติชั่นในหัวข้อ
- ผู้นำและแบบจำลอง: โบรกเกอร์ Kafka ทุกรายมีพาร์ติชั่นสองสามพาร์ติชั่นโดยแต่ละพาร์ติชั่น ไม่ว่าจะเป็นผู้นำหรือตัวจำลอง (สำรอง) ของหัวข้อ ผู้นำมีหน้าที่ไม่เพียงแต่อ่านและเขียนหัวข้อเท่านั้น แต่ยังต้องอัปเดตแบบจำลองด้วยข้อมูลใหม่ด้วย ไม่ว่าในกรณีใด ผู้นำล้มเหลว แบบจำลองสามารถเข้าแทนที่เป็นผู้นำคนใหม่ได้
สถาปัตยกรรมของ Apache Kafka
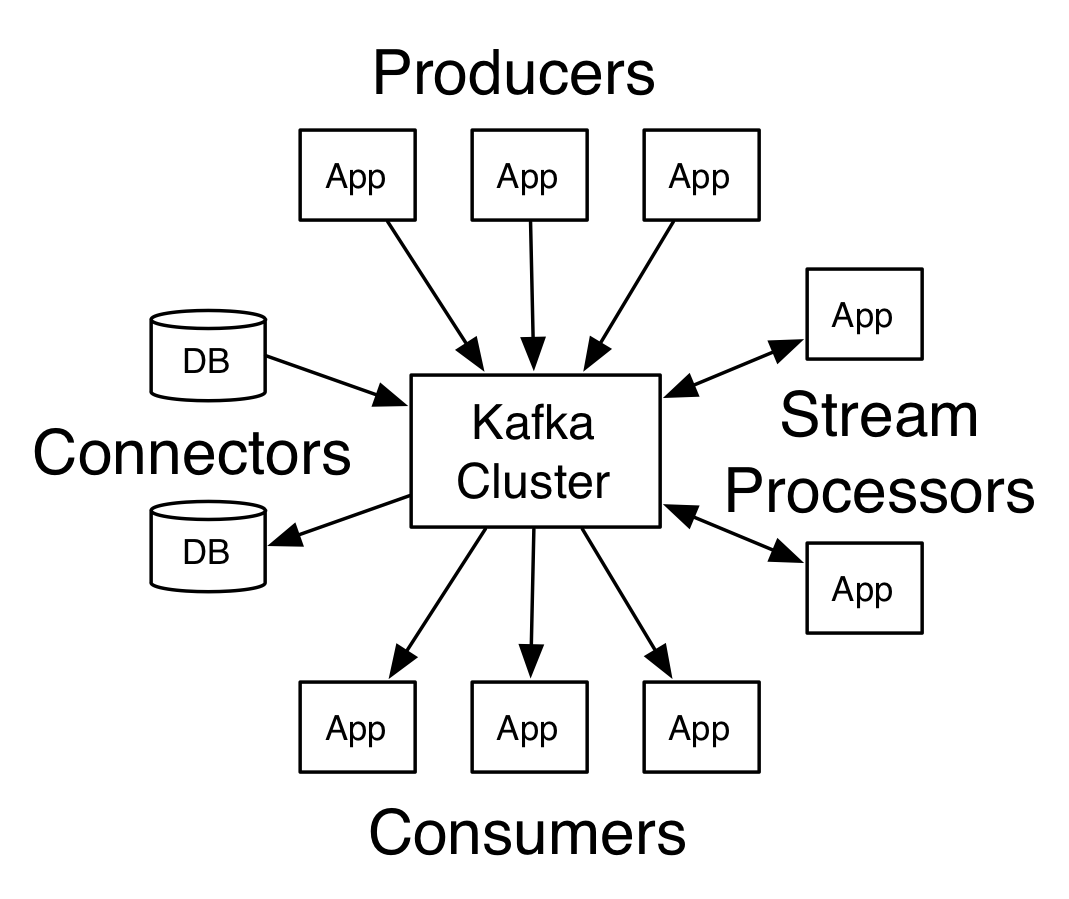
แหล่งที่มา
คาฟคาที่มีนายหน้ามากกว่าหนึ่งรายเรียกว่าคลัสเตอร์คาฟคา API หลักสี่ตัวจะกล่าวถึงใน บทช่วย สอน Apache Kafka นี้ :
- ผู้ผลิต API: API ของผู้ผลิต Kafka อนุญาตให้สตรีมของระเบียนถูกเผยแพร่โดยแอปพลิเคชันไปยังหัวข้อ Kafka หนึ่งหรือหลายหัวข้อ
- Consumer API: Consumer API อนุญาตให้แอปพลิเคชันประมวลผลโฟลว์ต่อเนื่องของเรคคอร์ดที่สร้างไปยังหัวข้ออย่างน้อยหนึ่งหัวข้อ
- Streams API: Streams API อนุญาตให้แอปพลิเคชันใช้อินพุตสตรีมจากหัวข้อหนึ่งหรือหลายหัวข้อ และสร้างสตรีมเอาต์พุตไปยังหัวข้อเอาต์พุตหนึ่งรายการหรือหลายรายการ ดังนั้นจึงอนุญาตให้แอปพลิเคชันทำหน้าที่เป็นตัวประมวลผลสตรีม สิ่งนี้จะแก้ไขสตรีมอินพุตไปยังสตรีมเอาต์พุตอย่างมีประสิทธิภาพ
- Connector API: API ตัวเชื่อมต่อช่วยให้สามารถสร้างและเรียกใช้ผู้ผลิตและผู้บริโภคที่นำกลับมาใช้ใหม่ได้ ซึ่งทำให้สามารถเชื่อมต่อระหว่างหัวข้อ Kafka กับระบบข้อมูลหรือแอปพลิเคชันที่มีอยู่ได้
เวิร์กโฟลว์ของโดเมนการส่งข้อความของผู้จัดพิมพ์-สมาชิก
- ผู้ผลิต Kafka ส่งข้อความไปยังหัวข้อเป็นระยะ
- โบรกเกอร์ Kafka ช่วยรับประกันการกระจายข้อความภายในพาร์ติชั่นที่เท่าเทียมกันโดยจัดเก็บไว้ในพาร์ติชั่นที่กำหนดค่าไว้สำหรับหัวข้อเฉพาะ
- การสมัครสมาชิกหัวข้อเฉพาะทำโดยผู้บริโภค Kafka เมื่อผู้บริโภคสมัครรับข้อมูลหัวข้อแล้ว จะมีการเสนอออฟเซ็ตปัจจุบันของหัวข้อให้กับผู้บริโภค และหัวข้อจะถูกบันทึกไว้ในชุดผู้ดูแลสวนสัตว์
- ผู้บริโภคร้องขอ Kafka สำหรับข้อความใหม่เป็นระยะ
- Kafka ส่งต่อข้อความไปยังผู้บริโภคทันทีที่ได้รับจากผู้ผลิต
- ผู้บริโภคได้รับข้อความและประมวลผล
- นายหน้า Kafka จะรับทราบทันทีที่มีการประมวลผลข้อความ
- เมื่อได้รับการตอบรับ ออฟเซ็ตจะถูกอัพเกรดเป็นค่าใหม่
- โฟลว์ซ้ำจนกว่าผู้บริโภคจะหยุดการร้องขอ
- ผู้บริโภคสามารถข้ามหรือกรอกลับการชดเชยได้ตลอดเวลาและอ่านข้อความที่ตามมาตามความสะดวก
เวิร์กโฟลว์ของระบบข้อความคิว
ในระบบข้อความในคิว ผู้บริโภคหลายรายที่มี ID กลุ่มเดียวกันสามารถสมัครรับข้อมูลหัวข้อได้ ถือว่าเป็นกลุ่มเดียวและแชร์ข้อความ ขั้นตอนการทำงานของระบบคือ:

- ผู้ผลิต Kafka ส่งข้อความไปยังหัวข้อเป็นระยะ
- โบรกเกอร์ Kafka ช่วยรับประกันการกระจายข้อความภายในพาร์ติชั่นที่เท่าเทียมกันโดยจัดเก็บไว้ในพาร์ติชั่นที่กำหนดค่าไว้สำหรับหัวข้อเฉพาะ
- ผู้บริโภครายเดียวสมัครรับข้อมูลหัวข้อเฉพาะ
- จนกว่าผู้บริโภครายใหม่จะสมัครรับข้อมูลหัวข้อเดียวกัน Kafka จะโต้ตอบกับผู้บริโภครายเดียว
- ด้วยการมาถึงของผู้บริโภครายใหม่ ข้อมูลจะถูกแบ่งปันระหว่างผู้บริโภคสองราย การแบ่งปันจะเกิดขึ้นซ้ำๆ จนกระทั่งจำนวนพาร์ติชันที่กำหนดค่าไว้สำหรับหัวข้อนั้นเท่ากับจำนวนผู้ใช้บริการ
- ผู้ใช้บริการรายใหม่จะไม่ได้รับข้อความเพิ่มเติมเมื่อจำนวนผู้ใช้บริการเกินจำนวนพาร์ติชันที่กำหนดค่าไว้ สถานการณ์นี้เกิดขึ้นเนื่องจากเงื่อนไขที่ผู้บริโภคแต่ละรายมีสิทธิ์ในพาร์ติชั่นอย่างน้อยหนึ่งพาร์ติชั่น และหากไม่มีพาร์ติชั่นว่าง ผู้บริโภครายใหม่ต้องรอ
2 เครื่องมือสำคัญใน Apache Kafka
ต่อไป ใน บทช่วย สอน Apache Kafka เราจะพูดถึงเครื่องมือ Kafka ที่บรรจุอยู่ภายใต้ “org.apache.kafka.tools.*
1. เครื่องมือการจำลองแบบ
เป็นเครื่องมือออกแบบระดับสูงที่ให้ความพร้อมใช้งานและความทนทานที่สูงขึ้น
- เครื่องมือสร้างหัวข้อ: เครื่องมือนี้ใช้เพื่อสร้างหัวข้อที่มีปัจจัยการจำลองแบบและจำนวนพาร์ติชันเริ่มต้น และใช้ชุดรูปแบบเริ่มต้นของ Kafka เพื่อดำเนินการมอบหมายแบบจำลอง
- เครื่องมือรายการหัวข้อ: ข้อมูลสำหรับรายการหัวข้อที่กำหนดจะแสดงรายการโดยเครื่องมือนี้ เครื่องมือนี้แสดงฟิลด์ต่างๆ เช่น พาร์ติชั่น ชื่อหัวข้อ ผู้นำ เรพลิกา และ isr
- เครื่องมือเพิ่มพาร์ติชั่น: เครื่องมือ นี้สามารถเพิ่มพาร์ติชั่นเพิ่มเติมสำหรับหัวข้อเฉพาะ นอกจากนี้ยังดำเนินการกำหนดแบบจำลองของพาร์ติชันที่เพิ่มด้วยตนเอง
2. เครื่องมือระบบ
สามารถใช้ run class script เพื่อเรียกใช้เครื่องมือระบบใน Kafka ไวยากรณ์คือ:
- Mirror Maker: การใช้เครื่องมือนี้คือการทำมิเรอร์คลัสเตอร์ Kafka หนึ่งไปยังอีกคลัสเตอร์หนึ่ง
- เครื่องมือการย้าย Kafka: เครื่องมือนี้ช่วยในการโยกย้ายโบรกเกอร์ Kafka จากรุ่นหนึ่งไปอีกรุ่นหนึ่ง
- Consumer Offset Checker: เครื่องมือนี้แสดงหัวข้อ Kafka, ขนาดบันทึก, ออฟเซ็ต, พาร์ติชั่น, กลุ่มผู้บริโภค และเจ้าของสำหรับชุดหัวข้อเฉพาะ
อ่านเพิ่มเติม: Apache Pig Tutorial

กรณีการใช้งาน 4 อันดับแรกของ Apache Kafka
ให้เราพูดถึงกรณีการใช้งานที่สำคัญของ Apache Kafka ในบทช่วยสอน Apache Kafka นี้:
- การประมวลผลแบบสตรีม: คุณลักษณะของความทนทานที่แข็งแกร่งของ Kafka ช่วยให้สามารถใช้ในด้านการประมวลผลแบบสตรีมได้ ในกรณีนี้ ข้อมูลจะถูกอ่านจากหัวข้อ ประมวลผล และข้อมูลที่ประมวลผลแล้วจะถูกเขียนไปยังหัวข้อใหม่เพื่อให้พร้อมใช้งานสำหรับแอปพลิเคชันและผู้ใช้
- ตัวชี้วัด: Kafka มักใช้สำหรับการตรวจสอบข้อมูลการปฏิบัติงาน สถิติถูกรวบรวมจากแอปพลิเคชันแบบกระจายเพื่อสร้างฟีดข้อมูลการปฏิบัติงานแบบรวมศูนย์
- การติดตามกิจกรรมเว็บไซต์: คลังข้อมูล เช่น BigQuery และ Google ใช้ Kafka เพื่อติดตามกิจกรรมบนเว็บไซต์ กิจกรรมของไซต์ เช่น การค้นหา การดูหน้าเว็บ หรือการดำเนินการของผู้ใช้อื่นๆ จะถูกเผยแพร่ไปยังหัวข้อส่วนกลาง และทำให้สามารถเข้าถึงได้สำหรับการประมวลผลแบบเรียลไทม์ การวิเคราะห์ออฟไลน์ และแดชบอร์ด
- การรวมบันทึก: การใช้ Kafka สามารถรวบรวมบันทึกจากบริการต่างๆ และให้บริการในรูปแบบมาตรฐานสำหรับผู้บริโภคจำนวนมาก
แอปพลิเคชั่น 5 อันดับแรกของ Apache Kafka
แอปพลิเคชั่นอุตสาหกรรมที่ดีที่สุดบางตัวที่รองรับโดย Kafka ได้แก่:
- Uber: แอพ cab ต้องการการประมวลผลแบบเรียลไทม์อย่างมากและจัดการปริมาณข้อมูลจำนวนมาก กระบวนการที่สำคัญ เช่น การตรวจสอบ การคำนวณ ETA และโปรแกรมควบคุมและการจับคู่ลูกค้านั้นสร้างแบบจำลองตาม Kafka Streams
- Netflix: แพลตฟอร์มสตรีมมิ่งอินเทอร์เน็ตแบบออนดีมานด์ Netflix ใช้ตัวชี้วัด Kafka สำหรับการประมวลผลเหตุการณ์และการตรวจสอบแบบเรียลไทม์
- LinkedIn: LinkedIn จัดการข้อความ 7 ล้านล้านข้อความทุกวัน โดยมี 100,000 หัวข้อ 7 ล้านพาร์ติชั่น และโบรกเกอร์มากกว่า 4,000 แห่ง Apache Kafka ใช้ใน LinkedIn สำหรับการติดตามตรวจสอบและติดตามกิจกรรมของผู้ใช้
- Tinder: แอพหาคู่ยอดนิยมนี้ใช้ Kafka Streams สำหรับกระบวนการต่างๆ ซึ่งรวมถึงการดูแลเนื้อหา คำแนะนำ การอัปเดตเขตเวลาของผู้ใช้ การแจ้งเตือน และการเปิดใช้งานผู้ใช้ และอื่นๆ
- Pinterest: ด้วยการค้นหาพินและไอเดียนับพันล้านครั้งต่อเดือน Pinterest ได้ใช้ประโยชน์จาก Kafka สำหรับกระบวนการต่างๆ Kafka Streams ใช้สำหรับสร้างดัชนีเนื้อหา ตรวจจับสแปม คำแนะนำ และสำหรับการคำนวณงบประมาณของโฆษณาแบบเรียลไทม์
บทสรุป
ใน บทช่วย สอน Apache Kafka นี้ เราได้พูดถึงแนวคิดพื้นฐานของ Apache Kafka, สถาปัตยกรรมและคลัสเตอร์ใน Kafka, เวิร์กโฟลว์ Kafka, เครื่องมือ Kafka และแอปพลิเคชั่นบางตัวของ Kafka Apache Kafka มีคุณสมบัติที่ดีที่สุดบางอย่าง เช่น ความทนทาน ความสามารถในการปรับขนาด ความทนทานต่อข้อผิดพลาด ความน่าเชื่อถือ ความสามารถในการขยาย การจำลองแบบ และปริมาณงานสูงที่ทำให้สามารถเข้าถึงได้จากแอปพลิเคชันอุตสาหกรรมที่ดีที่สุดบางตัว ดังตัวอย่างใน บทช่วย สอน Apache Kafka นี้
หากคุณสนใจที่จะทราบข้อมูลเพิ่มเติมเกี่ยวกับ Big Data โปรดดูที่ PG Diploma in Software Development Specialization in Big Data program ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 7 กรณี ครอบคลุมภาษาและเครื่องมือในการเขียนโปรแกรม 14 รายการ เวิร์กช็อป ความช่วยเหลือด้านการเรียนรู้และจัดหางานอย่างเข้มงวดมากกว่า 400 ชั่วโมงกับบริษัทชั้นนำ
เรียนรู้ หลักสูตรการพัฒนาซอฟต์แวร์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว