
Учебное пособие по Apache Kafka: введение, концепции, рабочий процесс, инструменты, приложения
Опубликовано: 2020-03-10Оглавление
Введение
С ростом популярности Kafka как системы обмена сообщениями многим компаниям требуются специалисты с хорошим знанием навыков Kafka, и именно здесь пригодится учебник по Apache Kafka. В сфере больших данных используется огромное количество данных, для сбора и анализа которых требуется система обмена сообщениями.
Kafka — это эффективная замена обычного брокера сообщений с улучшенной пропускной способностью, встроенным разделением и репликацией, а также встроенной отказоустойчивостью, что делает его подходящим для крупномасштабных приложений обработки сообщений. Если вы искали учебник по Apache Kafka , эта статья для вас.
Основные выводы из этого руководства по Apache Kafka
- Концепция систем обмена сообщениями
- Краткое введение в Apache Kafka
- Понятия, связанные с кластером Kafka и архитектурой Kafka
- Краткое описание рабочего процесса обмена сообщениями Kafka
- Обзор важных инструментов Kafka
- Варианты использования и приложения Apache Kafka
Также узнайте о: Учебное пособие по потоковой передаче Apache Spark для начинающих
Краткий обзор систем обмена сообщениями
Основная функция системы обмена сообщениями — обеспечить передачу данных из одного приложения в другое; система гарантирует, что приложения сосредоточатся только на данных, не останавливаясь в процессе обмена и передачи данных. Существует два вида систем обмена сообщениями:
1. Система обмена сообщениями «точка-точка»
В этой системе производители сообщений называются отправителями, а те, кто потребляет сообщения, — получателями. В этом домене обмен сообщениями осуществляется через место назначения, известное как очередь; отправители или производители отправляют сообщения в очередь, а сообщения потребляются получателями из очереди.

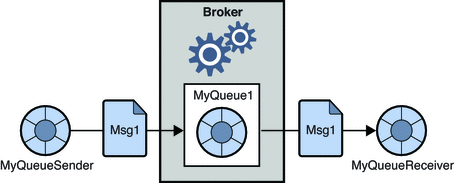
Источник
2. Система обмена сообщениями «публикация-подписка»
В этой системе производители сообщений называются издателями, а те, кто потребляет сообщения, — подписчиками. Однако в этом домене обмен сообщениями осуществляется через место назначения, известное как тема. Издатель создает сообщения в теме, и, подписавшись на тему, подписчики потребляют сообщения из темы. Эта система позволяет транслировать сообщения (иметь более одного подписчика, и каждый получает копию сообщения, опубликованного в определенной теме).
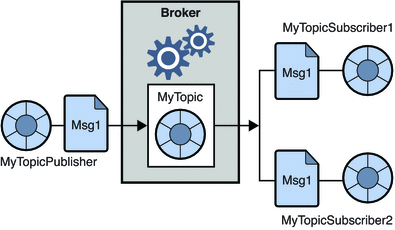
Источник
Apache Kafka — введение
Apache Kafka основан на системе обмена сообщениями типа «публикация-подписка». В системе обмена сообщениями pub-sub издатели являются производителями сообщений, а подписчики — потребителями сообщений. В этой системе потребители могут потреблять все сообщения темы (тем) с подпиской. Этот принцип системы обмена сообщениями pub-sub используется в Apache Kafka.
Кроме того, Apache Kafka использует концепцию распределенного обмена сообщениями, в соответствии с которой существует несинхронная организация очереди сообщений между системой обмена сообщениями и приложениями. Благодаря надежной очереди, способной обрабатывать большие объемы данных, Kafka позволяет передавать сообщения от одной конечной точки к другой и подходит для потребления сообщений как в сети, так и в автономном режиме. Сочетая в себе надежность, масштабируемость, долговечность и высокую производительность, Apache Kafka идеально подходит для интеграции и связи между единицами крупномасштабных систем данных в реальном мире.
Читайте также: Идеи проекта больших данных
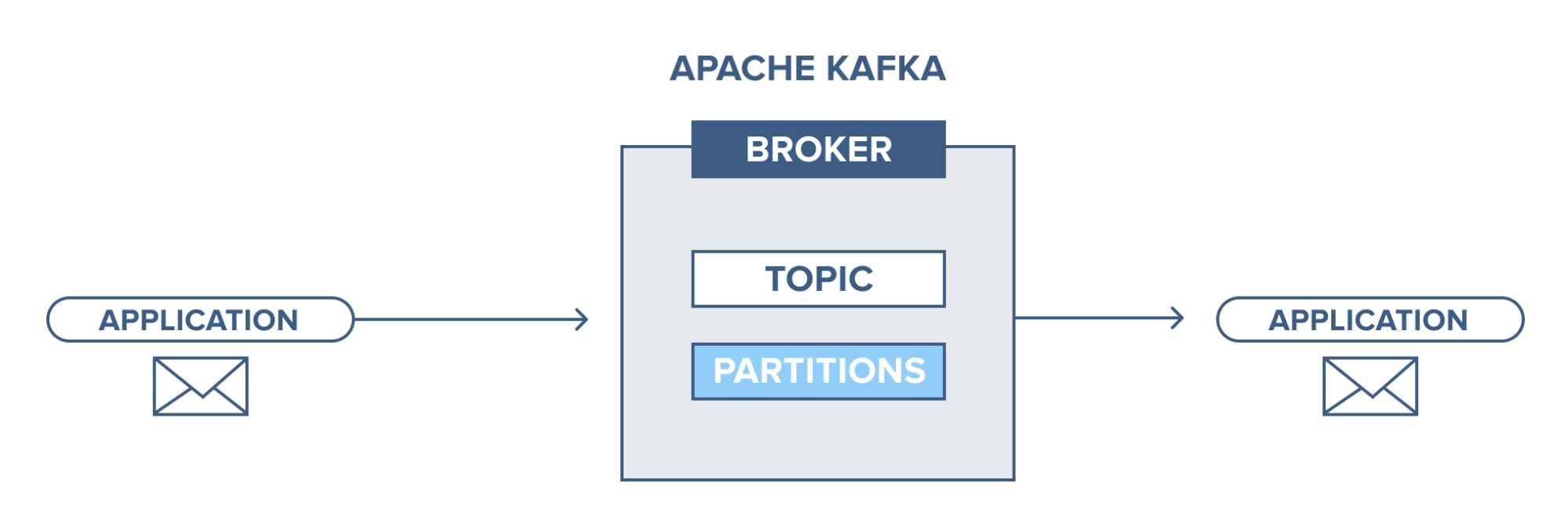
Источник
Концепция кластеров Apache Kafka
Источник
- Kafka zookeeper : Брокеры в кластере координируются и управляются зоопарками. Zookeeper уведомляет производителей и потребителей о появлении нового брокера или выходе из строя брокера в системе Kafka, а также уведомляет потребителей о величине компенсации. Производители и потребители согласовывают свою деятельность с другим посредником при получении от смотрителя зоопарка.
- Брокер Kafka: Брокеры Kafka — это системы, отвечающие за поддержание опубликованных данных в кластерах Kafka с помощью зоопарков. Брокер может иметь ноль или более разделов для каждой темы.
- Производитель Kafka: сообщения по одной или нескольким темам Kafka публикуются производителем и передаются брокерам, не дожидаясь подтверждения брокера.
- Потребитель Kafka: потребители извлекают данные из брокеров и используют уже опубликованные сообщения из одной или нескольких тем, отправляют несинхронный запрос на извлечение брокеру, чтобы иметь готовый к использованию буфер байтов, а затем предоставляют значение смещения для перемотки назад или перехода к любая точка раздела.
Основные концепции архитектуры Кафки
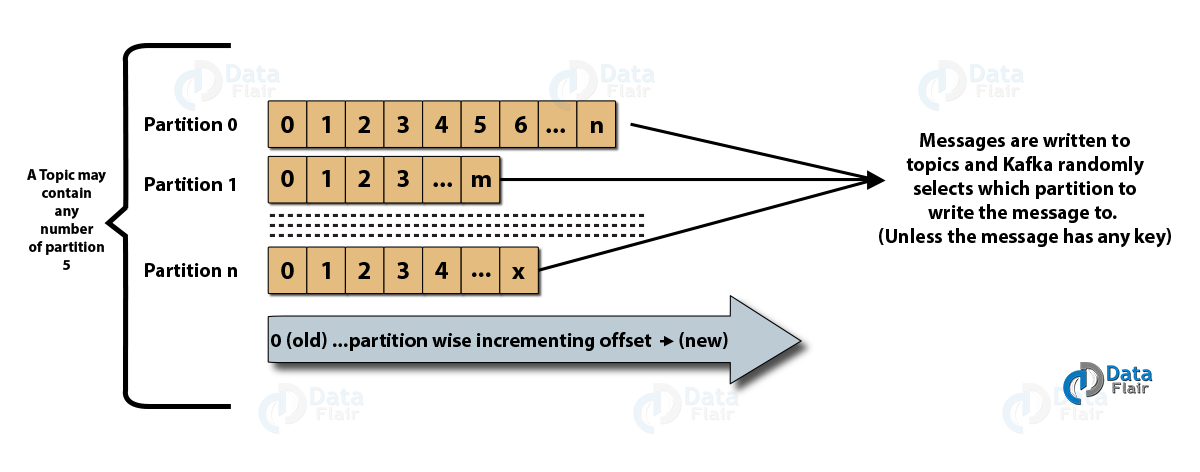
- Темы : Это логический канал, по которому сообщения публикуются производителями и откуда сообщения принимаются потребителями. Темы можно реплицировать (копировать), а также разделять (разделять). Сообщения определенного типа публикуются в определенной теме, причем каждая тема идентифицируется по своему уникальному имени.
- Разделы тем : в кластере Kafka темы делятся на разделы, а также реплицируются между брокерами. Производитель может добавить ключ к опубликованному сообщению, и сообщения с таким же ключом попадут в один и тот же раздел. Каждому сообщению в разделе назначается добавочный идентификатор, называемый смещением, и эти идентификаторы действительны только в пределах раздела и не имеют значения между разделами в теме.
- Лидер и реплика: у каждого брокера Kafka есть несколько разделов, каждый из которых является либо ведущим, либо репликой (резервной копией) темы. Лидер отвечает не только за чтение и запись в топик, но и за обновление реплик новыми данными. Если в любом случае лидер выходит из строя, реплика может стать новым лидером.
Архитектура Apache Kafka
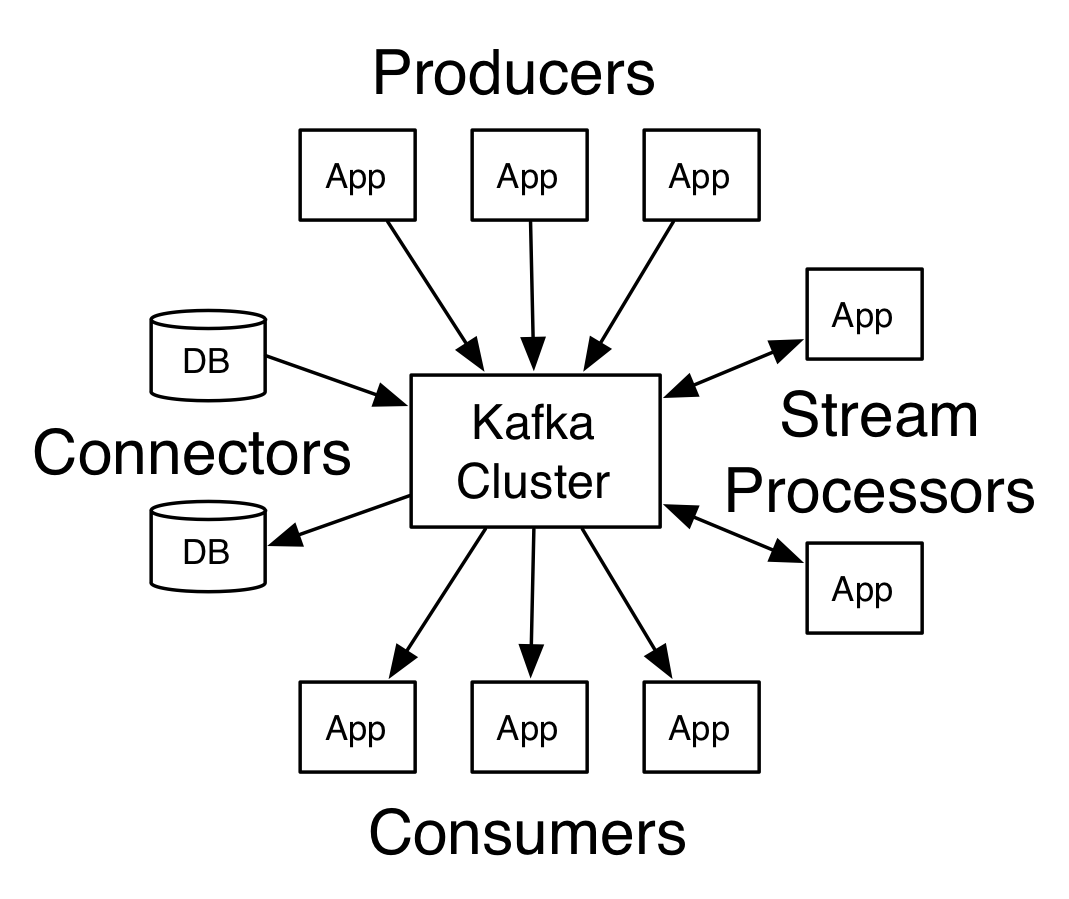
Источник
Kafka, имеющая более одного брокера, называется кластером Kafka. В этом руководстве по Apache Kafka будут обсуждаться четыре основных API :
- API производителя: API производителя Kafka позволяет приложению публиковать поток записей в одной или нескольких темах Kafka.
- Потребительский API: Потребительский API позволяет приложению обрабатывать непрерывный поток записей, созданных для одной или нескольких тем.
- API потоков: API потоков позволяет приложению потреблять входной поток из одной или нескольких тем и генерировать выходной поток для одной или нескольких выходных тем, что позволяет приложению действовать как потоковый процессор. Это эффективно изменяет входные потоки на выходные потоки.
- API коннектора: API коннектора позволяет создавать и запускать многоразовых производителей и потребителей, тем самым обеспечивая связь между темами Kafka и существующими системами данных или приложениями.
Рабочий процесс домена обмена сообщениями издатель-подписчик
- Производители Kafka отправляют сообщения в тему через регулярные промежутки времени.
- Брокеры Kafka обеспечивают равное распределение сообщений внутри разделов, сохраняя их в разделах, настроенных для определенной темы.
- Подписка на определенную тему осуществляется потребителями Kafka. Как только потребитель подписался на тему, потребителю предлагается текущее смещение темы, и тема сохраняется в ансамбле zookeeper.
- Потребитель через регулярные промежутки времени запрашивает у Kafka новые сообщения.
- Kafka пересылает сообщения потребителям сразу после получения от производителей.
- Потребитель получает сообщение и обрабатывает его.
- Брокер Kafka получает подтверждение, как только сообщение обрабатывается.
- При получении подтверждения смещение обновляется до нового значения.
- Поток повторяется до тех пор, пока потребитель не остановит запрос.
- Потребитель может пропустить или перемотать смещение в любое время и прочитать последующие сообщения по своему усмотрению.
Рабочий процесс системы обмена сообщениями очереди
В системе обмена сообщениями очереди несколько потребителей с одним и тем же идентификатором группы могут подписаться на тему. Они считаются единой группой и обмениваются сообщениями. Рабочий процесс системы таков:

- Производители Kafka отправляют сообщения в тему через регулярные промежутки времени.
- Брокеры Kafka обеспечивают равное распределение сообщений внутри разделов, сохраняя их в разделах, настроенных для определенной темы.
- Один потребитель подписывается на определенную тему.
- Пока новый потребитель не подпишется на ту же тему, Kafka взаимодействует с одним потребителем.
- С появлением новых потребителей данные распределяются между двумя потребителями. Совместное использование повторяется до тех пор, пока количество настроенных разделов для этой темы не сравняется с количеством потребителей.
- Новый потребитель не будет получать дальнейших сообщений, когда количество потребителей превышает количество настроенных разделов. Эта ситуация возникает из-за того, что каждый потребитель имеет право как минимум на один раздел, и если ни один из разделов не пуст, новые потребители должны ждать.
2 важных инструмента в Apache Kafka
Далее в этом руководстве по Apache Kafka мы обсудим инструменты Kafka, упакованные в «org.apache.kafka.tools.*.
1. Инструменты репликации
Это инструмент проектирования высокого уровня, обеспечивающий более высокую доступность и большую надежность.
- Инструмент « Создать тему». Этот инструмент используется для создания темы с коэффициентом репликации и количеством разделов по умолчанию и использует схему Kafka по умолчанию для выполнения назначения реплики.
- Инструмент «Список тем»: с помощью этого инструмента выводится информация по заданному списку тем. Этот инструмент отображает такие поля, как раздел, имя темы, лидер, реплики и isr.
- Инструмент « Добавить раздел»: с помощью этого инструмента можно добавить больше разделов для определенной темы. Он также выполняет ручное назначение реплик добавленных разделов.
2. Системные инструменты
Сценарий класса запуска можно использовать для запуска системных инструментов в Kafka. Синтаксис:
- Mirror Maker: этот инструмент используется для зеркалирования одного кластера Kafka в другой.
- Инструмент миграции Kafka: этот инструмент помогает перенести брокера Kafka с одной версии на другую.
- Средство проверки смещения потребителей: этот инструмент отображает тему Kafka, размер журнала, смещение, разделы, группу потребителей и владельца для определенного набора тем.
Читайте также: Учебник по Apache Pig

4 основных варианта использования Apache Kafka
Давайте обсудим некоторые важные варианты использования Apache Kafka в этом учебном пособии по Apache Kafka:
- Потоковая обработка: особенность высокой прочности Kafka позволяет использовать ее в области потоковой обработки. В этом случае данные считываются из темы, обрабатываются, а затем обработанные данные записываются в новую тему, чтобы сделать их доступными для приложений и пользователей.
- Метрики: Kafka часто используется для оперативного мониторинга данных. Статистические данные собираются из распределенных приложений для создания централизованного потока оперативных данных.
- Отслеживание действий на веб-сайтах. Хранилища данных, такие как BigQuery и Google, используют Kafka для отслеживания действий на веб-сайтах. Действия на сайте, такие как поиски, просмотры страниц или другие действия пользователей, публикуются в центральных темах и становятся доступными для обработки в режиме реального времени, автономного анализа и информационных панелей.
- Агрегация журналов. Используя Kafka, журналы можно собирать из многих сервисов и делать доступными в стандартном формате многим потребителям.
Топ 5 приложений Apache Kafka
Некоторые из лучших промышленных приложений, поддерживаемых Kafka, включают:
- Uber: Приложение такси требует огромной обработки в реальном времени и обрабатывает огромные объемы данных. Важные процессы, такие как аудит, расчет ожидаемого времени прибытия и подбор водителей и клиентов, моделируются на основе Kafka Streams.
- Netflix: Платформа интернет-стриминга по запросу Netflix использует метрики Kafka для обработки событий и мониторинга в реальном времени.
- LinkedIn: LinkedIn ежедневно обрабатывает 7 триллионов сообщений по 100 000 тем, 7 миллионам разделов и более 4000 брокеров. Apache Kafka используется в LinkedIn для отслеживания, мониторинга и отслеживания действий пользователей.
- Tinder: это популярное приложение для знакомств использует Kafka Streams для нескольких процессов, включая модерацию контента, рекомендации, обновление часового пояса пользователя, уведомления и активацию пользователя, среди прочего.
- Pinterest: ежемесячно проводя поиск миллиардов пинов и идей, Pinterest использует Kafka для многих процессов. Kafka Streams используются для индексации контента, обнаружения спама, рекомендаций и расчета бюджета рекламы в реальном времени.
Заключение
В этом учебном пособии по Apache Kafka мы обсудили основные концепции Apache Kafka, архитектуру и кластер в Kafka, рабочий процесс Kafka, инструменты Kafka и некоторые приложения Kafka. Apache Kafka обладает одними из лучших функций, такими как долговечность, масштабируемость, отказоустойчивость, надежность, расширяемость, репликация и высокая пропускная способность, которые делают его доступным для некоторых из лучших промышленных приложений, как показано в этом учебном пособии по Apache Kafka .
Если вам интересно узнать больше о больших данных, ознакомьтесь с нашей программой PG Diploma в области разработки программного обеспечения со специализацией в области больших данных, которая предназначена для работающих профессионалов и включает более 7 тематических исследований и проектов, охватывает 14 языков и инструментов программирования, практические занятия. семинары, более 400 часов интенсивного обучения и помощь в трудоустройстве в ведущих фирмах.
Изучайте онлайн-курсы по разработке программного обеспечения в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.