
Tutorial do Apache Kafka: introdução, conceitos, fluxo de trabalho, ferramentas, aplicativos
Publicados: 2020-03-10Índice
Introdução
Com a crescente popularidade do Kafka como sistema de mensagens, muitas empresas exigem profissionais com um bom conhecimento das habilidades do Kafka, e é aí que um Tutorial do Apache Kafka é útil. Uma enorme quantidade de dados é usada no domínio do Big Data que precisa de um sistema de mensagens para coleta e análise de dados.
O Kafka é um substituto eficiente do mediador de mensagens convencional com taxa de transferência aprimorada, particionamento e replicação inerentes e tolerância a falhas integrada, tornando-o adequado para aplicativos de processamento de mensagens em grande escala. Se você estava procurando por um Tutorial do Apache Kafka , este é o artigo certo para você.
Principais conclusões deste Tutorial do Apache Kafka
- Conceito de sistemas de mensagens
- Uma breve introdução ao Apache Kafka
- Conceitos relacionados ao cluster Kafka e arquitetura Kafka
- Breve descrição do fluxo de trabalho de mensagens Kafka
- Visão geral de ferramentas importantes do Kafka
- Casos de uso e aplicativos do Apache Kafka
Saiba também sobre: Tutorial de streaming do Apache Spark para iniciantes
Uma breve visão geral dos sistemas de mensagens
A principal função de um sistema de mensagens é permitir a transferência de dados de um aplicativo para outro; o sistema garante que os aplicativos se concentrem apenas nos dados sem ficarem parados durante o processo de compartilhamento e transmissão de dados. Existem dois tipos de sistemas de mensagens:
1. Sistema de mensagens ponto a ponto
Nesse sistema, os produtores das mensagens são chamados de emissores e os que consomem as mensagens são os receptores. Nesse domínio, as mensagens são trocadas por meio de um destino conhecido como fila; os remetentes ou os produtores produzem as mensagens para a fila e as mensagens são consumidas pelos destinatários da fila.

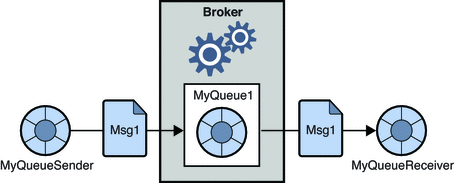
Fonte
2. Sistema de mensagens de publicação-assinatura
Nesse sistema, os produtores das mensagens são chamados de publicadores e os que consomem as mensagens são os assinantes. No entanto, neste domínio, as mensagens são trocadas por meio de um destino conhecido como tópico. Um publicador produz as mensagens para um tópico e, tendo se inscrito em um tópico, os assinantes consomem as mensagens do tópico. Este sistema permite a difusão de mensagens (tendo mais de um assinante e cada um recebe uma cópia das mensagens publicadas em um determinado tópico).
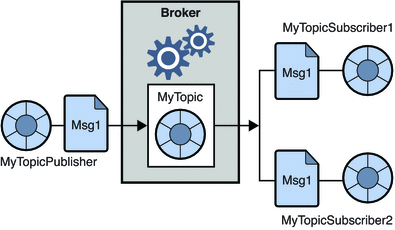
Fonte
Apache Kafka – uma introdução
O Apache Kafka é baseado em um sistema de mensagens de publicação-assinatura (pub-sub). No sistema de mensagens pub-sub, os editores são os produtores das mensagens e os assinantes são os consumidores das mensagens. Nesse sistema, os consumidores podem consumir todas as mensagens do(s) tópico(s) inscrito(s). Este princípio do sistema de mensagens pub-sub é empregado no Apache Kafka.
Além disso, o Apache Kafka usa o conceito de mensagens distribuídas, em que há um enfileiramento não síncrono de mensagens entre o sistema de mensagens e os aplicativos. Com uma fila robusta capaz de lidar com um grande volume de dados, o Kafka permite transmitir mensagens de um endpoint a outro e é adequado para o consumo de mensagens online e offline. Combinando confiabilidade, escalabilidade, durabilidade e desempenho de alto rendimento, o Apache Kafka é ideal para integração e comunicação entre unidades de sistemas de dados de grande escala no mundo real.
Leia também: Ideias de projetos de big data
Fonte
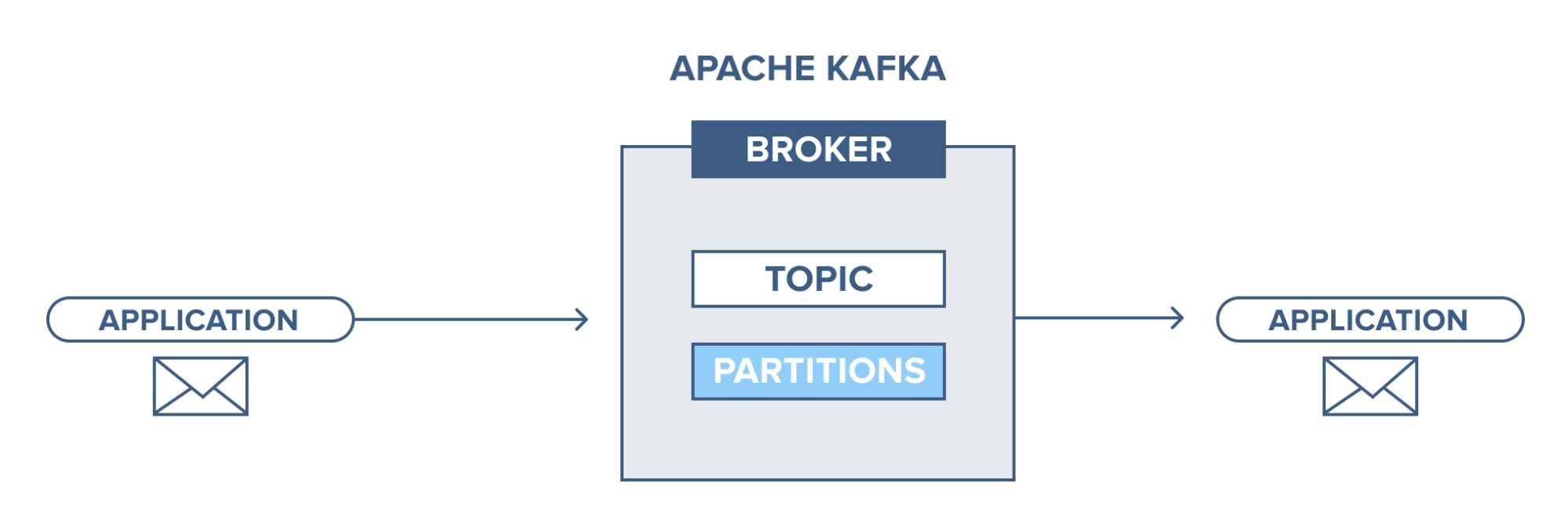
Conceito de clusters Apache Kafka
Fonte
- Kafka zookeeper : Os agentes em um cluster são coordenados e gerenciados por zookeepers. O Zookeeper notifica produtores e consumidores sobre a presença de um novo corretor ou falha de um corretor no sistema Kafka, bem como notifica os consumidores sobre o valor de compensação. Produtores e consumidores coordenam suas atividades com outro corretor ao receber do tratador.
- Corretor Kafka : Os corretores Kafka são sistemas responsáveis por manter os dados publicados em clusters Kafka com a ajuda de tratadores. Um broker pode ter zero ou mais partições para cada tópico.
- Produtor Kafka: As mensagens em um ou mais tópicos Kafka são publicadas pelo produtor e enviadas aos corretores, sem aguardar o reconhecimento do corretor.
- Consumidor Kafka: os consumidores extraem dados dos brokers e consomem mensagens já publicadas de um ou mais tópicos, emitem um pull request não síncrono para o broker para ter um buffer de bytes pronto para consumir e então fornece um valor de deslocamento para retroceder ou pular para qualquer ponto de partição.
Conceitos fundamentais da arquitetura Kafka
- Tópicos : É um canal lógico para o qual as mensagens são publicadas pelos produtores e do qual as mensagens são recebidas pelos consumidores. Os tópicos podem ser replicados (copiados), bem como particionados (divididos). Um tipo específico de mensagem é publicado em um tópico específico, com cada tópico identificável por seu nome exclusivo.
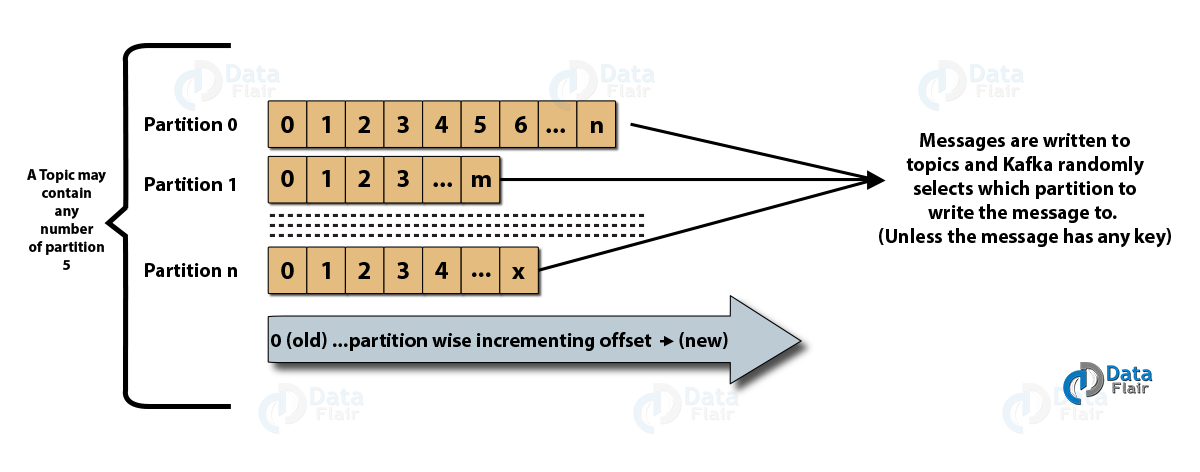
- Partições de tópicos: no cluster Kafka, os tópicos são divididos em partições e replicados entre os agentes. Um produtor pode adicionar uma chave a uma mensagem publicada e as mensagens com a mesma chave terminam na mesma partição. Um ID incremental chamado offset é atribuído a cada mensagem em uma partição e esses IDs são válidos apenas dentro da partição e não têm valor nas partições em um tópico.
- Líder e réplica: Cada broker do Kafka possui algumas partições com cada partição, sendo um líder ou uma réplica (backup) do tópico. O líder é responsável não apenas por ler e gravar em um tópico, mas também por atualizar as réplicas com novos dados. Se, em qualquer caso, o líder falhar, a réplica pode assumir o novo líder.
Arquitetura do Apache Kafka
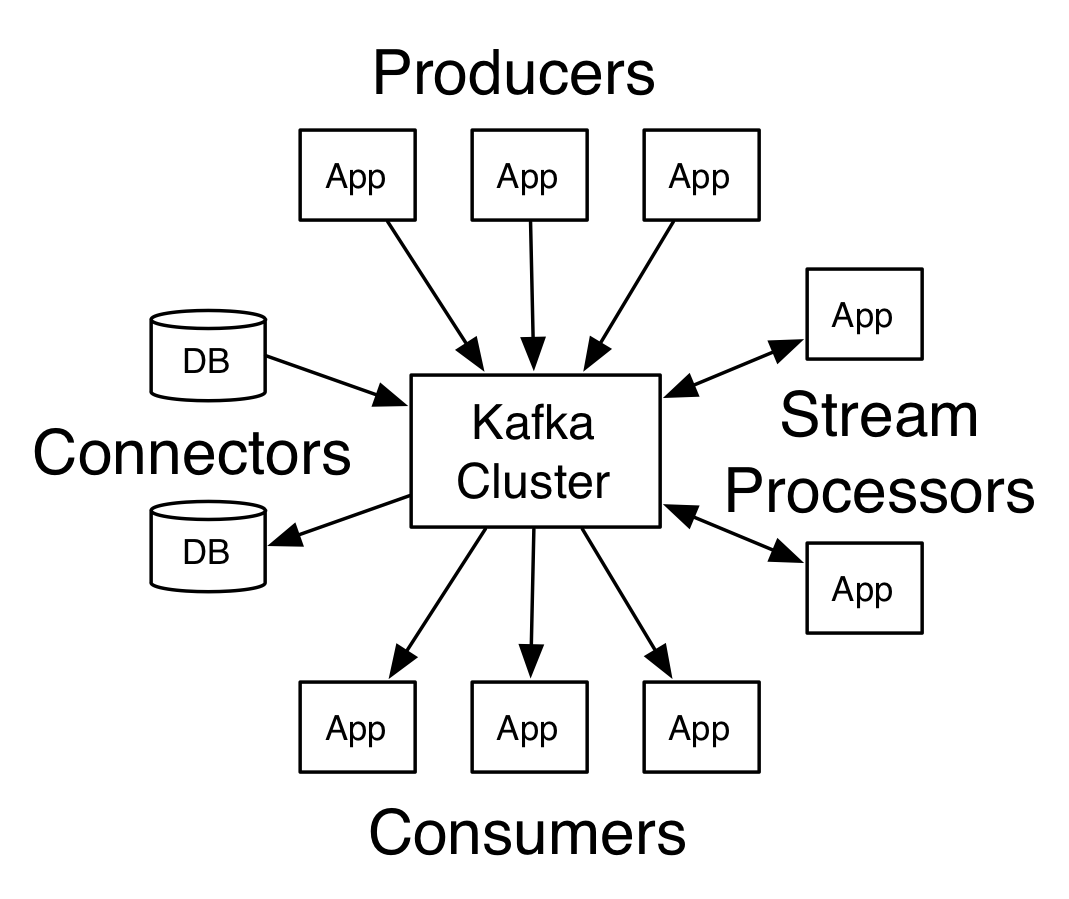
Fonte
Um Kafka com mais de um broker é chamado de cluster Kafka. Quatro das APIs principais serão discutidas neste Tutorial do Apache Kafka :
- API do produtor: A API do produtor do Kafka permite que um fluxo de registros seja publicado por um aplicativo para um ou vários tópicos do Kafka.
- API do consumidor: A API do consumidor permite que um aplicativo processe o fluxo contínuo de registros produzidos para um ou mais tópicos.
- API de fluxos: A API de fluxos permite que um aplicativo consuma um fluxo de entrada de um ou vários tópicos e gere um fluxo de saída para um ou vários tópicos de saída, permitindo que o aplicativo atue como um processador de fluxo. Isso modifica eficientemente os fluxos de entrada para os fluxos de saída.
- API do conector: A API do conector permite a criação e execução de produtores e consumidores reutilizáveis, permitindo assim uma conexão entre tópicos Kafka e sistemas de dados ou aplicativos existentes.
Fluxo de trabalho do domínio de mensagens do editor-assinante
- Os produtores de Kafka enviam mensagens para um tópico em intervalos regulares.
- Os agentes Kafka garantem a distribuição igualitária de mensagens dentro das partições armazenando-as nas partições configuradas para um determinado tópico.
- A inscrição em um tópico específico é feita pelos consumidores do Kafka. Depois que o consumidor se inscreve em um tópico, o deslocamento atual do tópico é oferecido ao consumidor e o tópico é salvo no conjunto zookeeper.
- O consumidor solicita a Kafka novas mensagens em intervalos regulares.
- Kafka encaminha as mensagens aos consumidores imediatamente após o recebimento dos produtores.
- O consumidor recebe a mensagem e a processa.
- O corretor Kafka recebe uma confirmação assim que a mensagem é processada.
- Ao receber a confirmação, o deslocamento é atualizado para o novo valor.
- O fluxo se repete até que o consumidor pare a solicitação.
- O consumidor pode pular ou retroceder um deslocamento a qualquer momento e ler as mensagens subsequentes conforme sua conveniência.
Fluxo de trabalho do sistema de mensagens de fila
Em um sistema de mensagens de fila, vários consumidores com o mesmo ID de grupo podem assinar um tópico. Eles são considerados um único grupo e compartilham as mensagens. O fluxo de trabalho do sistema é:

- Os produtores de Kafka enviam mensagens para um tópico em intervalos regulares.
- Os agentes Kafka garantem a distribuição igualitária de mensagens dentro das partições armazenando-as nas partições configuradas para um determinado tópico.
- Um único consumidor assina um tópico específico.
- Até que um novo consumidor se inscreva no mesmo tópico, Kafka interage com o consumidor único.
- Com a chegada dos novos consumidores, os dados são compartilhados entre dois consumidores. O compartilhamento é repetido até que o número de partições configuradas para esse tópico seja igual ao número de consumidores.
- Um novo consumidor não receberá mais mensagens quando o número de consumidores exceder o número de partições configuradas. Esta situação surge devido à condição de que cada consumidor tenha direito a um mínimo de uma partição, e se nenhuma partição estiver em branco, os novos consumidores terão que esperar.
2 ferramentas importantes no Apache Kafka
A seguir, neste Tutorial do Apache Kafka , discutiremos as ferramentas do Kafka empacotadas em “org.apache.kafka.tools.*.
1. Ferramentas de replicação
É uma ferramenta de design de alto nível que confere maior disponibilidade e maior durabilidade.
- Ferramenta Criar Tópico: Essa ferramenta é usada para criar um tópico com um fator de replicação e um número padrão de partições e usa o esquema padrão do Kafka para executar uma atribuição de réplica.
- Ferramenta Listar Tópicos: As informações de uma determinada lista de tópicos são listadas por esta ferramenta. Campos como partição, nome do tópico, líder, réplicas e isr são exibidos por esta ferramenta.
- Ferramenta Adicionar Partição: Mais partições para um tópico específico podem ser adicionadas por esta ferramenta. Ele também executa a atribuição manual de réplicas das partições adicionadas.
2. Ferramentas do sistema
O script de classe de execução pode ser usado para executar ferramentas do sistema no Kafka. A sintaxe é:
- Mirror Maker: O uso desta ferramenta é espelhar um cluster Kafka para outro.
- Ferramenta de migração Kafka: Esta ferramenta ajuda na migração de um broker Kafka de uma versão para outra.
- Consumer Offset Checker: Esta ferramenta exibe o tópico Kafka, tamanho do log, deslocamento, partições, grupo de consumidores e proprietário para o conjunto específico de tópicos.
Leia também: Tutorial Apache Pig

Os 4 principais casos de uso do Apache Kafka
Vamos discutir alguns casos de uso importantes do Apache Kafka neste Tutorial do Apache Kafka:
- Processamento de fluxo: O recurso de alta durabilidade do Kafka permite que ele seja usado no campo de processamento de fluxo. Nesse caso, os dados são lidos de um tópico, processados e os dados processados são então gravados em um novo tópico para disponibilizá-lo para aplicativos e usuários.
- Métricas: Kafka é frequentemente usado para monitoramento operacional de dados. As estatísticas são agregadas de aplicativos distribuídos para fazer um feed centralizado de dados operacionais.
- Rastreamento da atividade do site: armazéns de dados como BigQuery e Google empregam Kafka para rastrear atividades em sites. As atividades do site, como pesquisas, visualizações de página ou outras ações do usuário, são publicadas em tópicos centrais e disponibilizadas para processamento em tempo real, análise offline e painéis.
- Agregação de logs: usando o Kafka, os logs podem ser coletados de vários serviços e disponibilizados em um formato padronizado para muitos consumidores.
As 5 principais aplicações do Apache Kafka
Algumas das melhores aplicações industriais suportadas pelo Kafka incluem:
- Uber: O aplicativo de táxi precisa de imenso processamento em tempo real e lida com um grande volume de dados. Processos importantes como auditoria, cálculos de ETA e correspondência de motorista e cliente são modelados com base no Kafka Streams.
- Netflix: A plataforma de streaming de internet sob demanda Netflix usa métricas Kafka para processamento de eventos e monitoramento em tempo real.
- LinkedIn: o LinkedIn gerencia 7 trilhões de mensagens todos os dias, com 100.000 tópicos, 7 milhões de partições e mais de 4.000 corretores. O Apache Kafka é usado no LinkedIn para rastreamento, monitoramento e rastreamento de atividades do usuário.
- Tinder: Este popular aplicativo de namoro usa o Kafka Streams para diversos processos que incluem moderação de conteúdo, recomendações, atualização do fuso horário do usuário, notificações e ativação do usuário, entre outros.
- Pinterest: Com uma busca mensal de bilhões de pins e ideias, o Pinterest aproveitou o Kafka para muitos processos. Kafka Streams são utilizados para indexação de conteúdos, detecção de spams, recomendações e para calcular orçamentos de anúncios em tempo real.
Conclusão
Neste Tutorial do Apache Kafka , discutimos os conceitos fundamentais do Apache Kafka, arquitetura e cluster no Kafka, fluxo de trabalho do Kafka, ferramentas do Kafka e algumas aplicações do Kafka. O Apache Kafka possui alguns dos melhores recursos, como durabilidade, escalabilidade, tolerância a falhas, confiabilidade, extensibilidade, replicação e alta taxa de transferência, que o tornam acessível em alguns dos melhores aplicativos industriais, conforme exemplificado neste Tutorial do Apache Kafka .
Se você estiver interessado em saber mais sobre Big Data, confira nosso programa PG Diploma in Software Development Specialization in Big Data, projetado para profissionais que trabalham e fornece mais de 7 estudos de caso e projetos, abrange 14 linguagens e ferramentas de programação, práticas práticas workshops, mais de 400 horas de aprendizado rigoroso e assistência para colocação de emprego com as principais empresas.
Aprenda cursos de desenvolvimento de software online das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.