
Funcionalidade de regressão da árvore de decisão, termos, implementação [com exemplo]
Publicados: 2020-12-24Para começar, um modelo de regressão é um modelo que fornece como saída um valor numérico quando recebe alguns valores de entrada que também são numéricos. Isso difere do que um modelo de classificação faz. Ele classifica os dados de teste em várias classes ou grupos envolvidos em uma determinada declaração de problema.
O tamanho do grupo pode ser tão pequeno quanto 2 e tão grande quanto 1000 ou mais. Existem vários modelos de regressão, como regressão linear, regressão multivariada, regressão Ridge, regressão logística e muito mais. Os modelos de regressão de árvore de decisão também pertencem a esse conjunto de modelos de regressão.
O modelo preditivo classificará ou preverá um valor numérico que faz uso de regras binárias para determinar o valor de saída ou de destino. O modelo de árvore de decisão, como o nome sugere, é um modelo semelhante a uma árvore que possui folhas, galhos e nós.
Aprenda o curso on-line de aprendizado de máquina das melhores universidades do mundo. Ganhe Masters, Executive PGP ou Advanced Certificate Programs para acelerar sua carreira.
Leia: Ideias de projetos de aprendizado de máquina
Índice
Terminologias para lembrar
Antes de nos aprofundarmos no algoritmo, aqui estão algumas terminologias importantes que todos vocês devem conhecer.

- Nó raiz: É o nó mais alto de onde a divisão começa.
- Divisão: Processo de subdividir um único nó em vários subnós.
- Nó terminal ou nó folha: os nós que não se dividem mais são chamados de nós terminais.
- Poda: O processo de remoção de subnós.
- Nó pai: O nó que se divide ainda mais em subnós.
- Nó filho: os subnós que surgiram do nó pai.
Como funciona?
A árvore de decisão divide o conjunto de dados em subconjuntos menores. Uma folha de decisão se divide em duas ou mais ramificações que representam o valor do atributo em exame. O nó mais alto na árvore de decisão é o melhor preditor chamado nó raiz. ID3 é o algoritmo que constrói a árvore de decisão.
Ele emprega uma abordagem de cima para baixo e as divisões são feitas com base no desvio padrão. Apenas para uma rápida revisão, o desvio padrão é o grau de distribuição ou dispersão de um conjunto de pontos de dados de seu valor médio. Ele quantifica a variabilidade geral da distribuição de dados.
Um valor mais alto de dispersão ou variabilidade significa que maior é o desvio padrão, indicando a maior dispersão dos pontos de dados do valor médio. Usamos o desvio padrão para medir a uniformidade da amostra. Se a amostra for totalmente homogênea, seu desvio padrão é zero.
E da mesma forma, quanto maior o grau de heterogeneidade, maior será o desvio padrão. A média da amostra e o número de amostras são necessários para calcular o desvio padrão. Usamos uma função matemática — Coeficiente de Desvio que decide quando a divisão deve parar. Ele é calculado dividindo o desvio padrão pela média de todas as amostras.
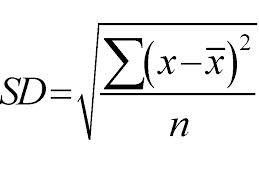
Fonte
O valor final seria a média dos nós folha. Digamos, por exemplo, se o mês de novembro é o nó que se divide ainda mais em vários salários ao longo dos anos no mês de novembro (até 2020). Para o ano de 2021, o salário do mês de novembro seria a média de todos os salários sob o nó novembro.
Passando para o desvio padrão de duas classes ou atributos (como no exemplo acima, o salário pode ser baseado em uma base horária ou mensal). A fórmula ficaria assim:
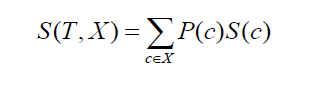
Fonte
onde P(c) é a probabilidade de ocorrência do atributo c, S(c) é o desvio padrão correspondente do atributo c. O método de redução do desvio padrão é baseado na diminuição do desvio padrão após a divisão de um conjunto de dados.
Para construir uma árvore de decisão precisa, o objetivo deve ser encontrar atributos que retornem após o cálculo e retornem a maior redução de desvio padrão. Em palavras simples, os ramos mais homogêneos.

O processo de criação de uma árvore de decisão para regressão abrange quatro etapas importantes.
1. Em primeiro lugar, calculamos o desvio padrão da variável alvo. Considere a variável de destino como salário, como nos exemplos anteriores. Com o exemplo em vigor, calcularemos o desvio padrão do conjunto de valores salariais.
2. Na etapa 2, o conjunto de dados é dividido em diferentes atributos. falando em atributos, como o valor alvo é o salário, podemos pensar nos atributos possíveis como – meses, horas, humor do chefe, designação, ano na empresa e assim por diante. Então, o desvio padrão para cada ramo é calculado usando a fórmula acima. o desvio padrão assim obtido é subtraído do desvio padrão antes da divisão. O resultado em mãos é chamado de redução do desvio padrão.
3. Uma vez calculada a diferença conforme mencionado na etapa anterior, o melhor atributo é aquele para o qual o valor de redução do desvio padrão é maior. Isso significa que o desvio padrão antes da divisão deve ser maior que o desvio padrão antes da divisão. Na verdade, o mod da diferença é tomado e vice-versa também é possível.
4. Todo o conjunto de dados é classificado com base na importância do atributo selecionado. Nos ramos não-folha, este método é continuado recursivamente até que todos os dados disponíveis sejam processados. Agora, considere o mês selecionado como o melhor atributo de divisão com base no valor de redução do desvio padrão. Então teremos 12 filiais para cada mês. Essas ramificações serão divididas ainda mais para selecionar o melhor atributo do conjunto restante de atributos.
5. Na realidade, exigimos alguns critérios de acabamento. Para isso, usamos o coeficiente de desvio ou CV para um ramo que se torna menor que um determinado limite como 10%. Quando atingimos esse critério, interrompemos o processo de construção da árvore. Como nenhuma divisão adicional acontece, o valor que se enquadra nesse atributo será a média de todos os valores nesse nó.
Implementação
A regressão da árvore de decisão pode ser implementada usando a linguagem Python e a biblioteca scikit-learn. Ele pode ser encontrado em sklearn.tree.DecisionTreeRegressor.
Alguns dos parâmetros importantes são os seguintes:
- critério: Para medir a qualidade de uma divisão. Seu valor pode ser “mse” ou o erro quadrático médio, “friedman_mse”, e “mae” ou o erro médio absoluto. O valor padrão é mse.
- max_depth: representa a profundidade máxima da árvore. O valor padrão é Nenhum.
- max_features: representa o número de recursos a serem procurados ao decidir a melhor divisão. O valor padrão é Nenhum.
- divisor: Este parâmetro é usado para escolher a divisão em cada nó. Os valores disponíveis são “melhor” e “aleatório”. O valor padrão é o melhor.
Confira: Perguntas da entrevista sobre aprendizado de máquina
Exemplo da documentação do sklearn
>>> de sklearn.datasets importação load_diabetes
>>> de sklearn.model_selection importação cross_val_score
>>> de sklearn.tree importação DecisionTreeRegressor
>>> X, y = load_diabetes(return_X_y= True )
>>> regressor = DecisionTreeRegressor(random_state=0)
>>> cross_val_score(regressor, X, y, cv=10)
… # doctest: +SKIP
…
array([-0,39…, -0,46…, 0,02…, 0,06…, -0,50…,
0,16…, 0,11…, -0,73…, -0,30…, -0,00…])
Qual o proximo?
Além disso, se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o Programa PG Executivo do IIIT-B e do upGrad em aprendizado de máquina e IA, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições , IIIT-B Alumni status, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.