
Fungsi, Syarat, Implementasi Regresi Pohon Keputusan [Dengan Contoh]
Diterbitkan: 2020-12-24Untuk memulainya, model regresi adalah model yang memberikan nilai numerik sebagai keluaran ketika diberikan beberapa nilai masukan yang juga numerik. Ini berbeda dari apa yang dilakukan model klasifikasi. Ini mengklasifikasikan data uji ke dalam berbagai kelas atau kelompok yang terlibat dalam pernyataan masalah yang diberikan.
Ukuran grup bisa sekecil 2 dan sebesar 1000 atau lebih. Ada beberapa model regresi seperti regresi linier, regresi multivariat, regresi Ridge, regresi logistik, dan banyak lagi. Model regresi pohon keputusan juga termasuk dalam kumpulan model regresi ini.
Model prediktif akan mengklasifikasikan atau memprediksi nilai numerik yang menggunakan aturan biner untuk menentukan output atau nilai target. Model pohon keputusan, seperti namanya, adalah model seperti pohon yang memiliki daun, cabang, dan simpul.
Pelajari Kursus Online Machine Learning dari Universitas top dunia. Dapatkan Master, PGP Eksekutif, atau Program Sertifikat Tingkat Lanjut untuk mempercepat karier Anda.
Baca: Ide Proyek Pembelajaran Mesin
Daftar isi
Terminologi untuk Diingat
Sebelum kita mempelajari algoritme, berikut adalah beberapa terminologi penting yang harus Anda ketahui.

- Root node: Ini adalah node paling atas dari mana pemisahan dimulai.
- Splitting: Proses membagi satu node menjadi beberapa sub-node.
- Node terminal atau node daun: Node yang tidak membelah lebih jauh disebut node terminal.
- Pemangkasan: Proses penghapusan sub node .
- Parent node: Node yang membagi lebih jauh menjadi sub node.
- Node anak: Sub node yang muncul dari node induk.
Bagaimana cara kerjanya?
Pohon keputusan memecah kumpulan data menjadi himpunan bagian yang lebih kecil. Daun keputusan terbagi menjadi dua atau lebih cabang yang mewakili nilai atribut yang diperiksa. Node paling atas dalam pohon keputusan adalah prediktor terbaik yang disebut root node. ID3 adalah algoritma yang membangun pohon keputusan.
Ini menggunakan pendekatan dari atas ke bawah dan pemisahan dibuat berdasarkan standar deviasi. Hanya untuk revisi cepat, Standar deviasi adalah tingkat distribusi atau dispersi dari sekumpulan titik data dari nilai rata-ratanya. Ini mengukur variabilitas keseluruhan dari distribusi data.
Nilai dispersi atau variabilitas yang lebih tinggi berarti semakin besar standar deviasi yang menunjukkan semakin besar penyebaran titik-titik data dari nilai rata-rata. Kami menggunakan standar deviasi untuk mengukur keseragaman sampel. Jika sampel benar-benar homogen, simpangan bakunya adalah nol.
Demikian pula, semakin tinggi derajat heterogenitas, semakin besar standar deviasinya. Rata-rata sampel dan jumlah sampel diperlukan untuk menghitung simpangan baku. Kami menggunakan fungsi matematika — Koefisien Deviasi yang memutuskan kapan pemisahan harus berhenti. Ini dihitung dengan membagi standar deviasi dengan rata-rata semua sampel.
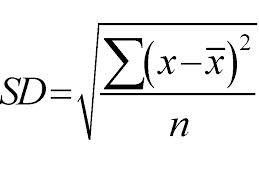
Sumber
Nilai akhir akan menjadi rata-rata dari simpul daun. Katakanlah, misalnya, jika bulan November adalah simpul yang terbagi lagi menjadi berbagai gaji selama bertahun-tahun di bulan November (hingga 2020). Untuk tahun 2021, gaji untuk bulan November akan menjadi rata-rata dari semua gaji di bawah node November.
Pindah ke standar deviasi dua kelas atau atribut (seperti contoh di atas, gaji dapat didasarkan pada basis per jam atau bulanan). Rumusnya akan terlihat seperti berikut:
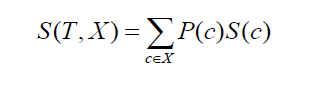
Sumber
di mana P(c) adalah probabilitas kemunculan atribut c, S(c) adalah standar deviasi yang sesuai dari atribut c. Metode pengurangan standar deviasi didasarkan pada penurunan standar deviasi setelah dataset terpecah.
Untuk membangun pohon keputusan yang akurat, tujuannya adalah untuk menemukan atribut yang kembali pada perhitungan, dan mengembalikan pengurangan standar deviasi tertinggi. Dengan kata sederhana, cabang yang paling homogen.

Proses pembuatan pohon keputusan untuk regresi mencakup empat langkah penting.
1. Pertama, kita menghitung standar deviasi dari variabel target. Pertimbangkan variabel target menjadi gaji seperti pada contoh sebelumnya. Dengan contoh di tempat, kami akan menghitung standar deviasi dari himpunan nilai gaji.
2. Pada langkah 2, kumpulan data selanjutnya dipecah menjadi atribut yang berbeda. berbicara tentang atribut, karena nilai targetnya adalah gaji, kita dapat memikirkan atribut yang mungkin seperti — bulan, jam, suasana hati bos, penunjukan, tahun di perusahaan, dan sebagainya. Kemudian, standar deviasi untuk setiap cabang dihitung menggunakan rumus di atas. simpangan baku yang diperoleh dikurangi dari simpangan baku sebelum dipecah. Hasil di tangan disebut pengurangan standar deviasi.
3. Setelah selisih dihitung seperti yang disebutkan pada langkah sebelumnya, atribut terbaik adalah atribut yang nilai reduksi standar deviasinya terbesar. Artinya, standar deviasi sebelum split harus lebih besar dari standar deviasi sebelum split. Sebenarnya, mod perbedaan diambil dan sebaliknya juga dimungkinkan.
4. Seluruh dataset diklasifikasikan berdasarkan kepentingan atribut yang dipilih. Pada cabang non-daun, metode ini dilanjutkan secara rekursif sampai semua data yang tersedia diproses. Sekarang pertimbangkan bulan dipilih sebagai atribut pemisahan terbaik berdasarkan nilai pengurangan standar deviasi. Jadi kami akan memiliki 12 cabang untuk setiap bulan. Cabang-cabang ini selanjutnya akan dipecah untuk memilih atribut terbaik dari kumpulan atribut yang tersisa.
5. Pada kenyataannya, kita membutuhkan beberapa kriteria finishing. Untuk ini, kami menggunakan koefisien deviasi atau CV untuk cabang yang menjadi lebih kecil dari ambang batas tertentu seperti 10%. Ketika kami mencapai kriteria ini, kami menghentikan proses pembuatan pohon. Karena tidak terjadi pemisahan lebih lanjut, nilai yang berada di bawah atribut ini akan menjadi rata-rata dari semua nilai di bawah simpul itu.
Penerapan
Regresi Pohon Keputusan dapat diimplementasikan menggunakan bahasa Python dan pustaka scikit-learn. Itu dapat ditemukan di bawah sklearn.tree.DecisionTreeRegressor.
Beberapa parameter penting adalah sebagai berikut:
- kriteria: Untuk mengukur kualitas split. Nilainya bisa berupa “mse” atau mean squared error, “friedman_mse”, dan “mae” atau mean absolute error. Nilai defaultnya adalah mse.
- max_depth: Ini mewakili kedalaman maksimum pohon. Nilai default adalah Tidak Ada.
- max_features: Ini mewakili jumlah fitur yang harus dicari saat memutuskan pemisahan terbaik. Nilai default adalah Tidak Ada.
- splitter: Parameter ini digunakan untuk memilih split pada setiap node. Nilai yang tersedia adalah "terbaik" dan "acak". Nilai default adalah yang terbaik.
Lihat: Pertanyaan Wawancara Pembelajaran Mesin
Contoh dari dokumentasi sklearn
>>> dari sklearn.datasets impor load_diabetes
>>> dari sklearn.model_selection impor cross_val_score
>>> dari sklearn.tree impor DecisionTreeRegressor
>>> X, y = load_diabetes(return_X_y= Benar )
>>> regressor = DecisionTreeRegressor(random_state=0)
>>> cross_val_score(regressor, X, y, cv=10)
… # doctest: +SKIP
…
array([-0,39…, -0,46…, 0,02…, 0,06…, -0,50…,
0,16…, 0,11…, -0,73…, -0,30…, -0,00…])
Apa selanjutnya?
Juga, Jika Anda tertarik untuk mempelajari lebih lanjut tentang Pembelajaran mesin, lihat Program PG Eksekutif IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas , Status Alumni IIIT-B, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.