
決策樹回歸功能、術語、實現 [附示例]
已發表: 2020-12-24首先,回歸模型是一種在給定一些也是數字的輸入值時給出一個數字值作為輸出的模型。 這與分類模型的作用不同。 它將測試數據分類為給定問題陳述中涉及的各種類別或組。
組的大小可以小至 2 人,大至 1000 人或更多。 有多種回歸模型,如線性回歸、多元回歸、嶺回歸、邏輯回歸等等。 決策樹回歸模型也屬於這個回歸模型池。
預測模型將分類或預測利用二進制規則確定輸出或目標值的數值。 決策樹模型,顧名思義,是一種具有葉子、分支和節點的樹狀模型。
從世界頂尖大學學習機器學習在線課程。 獲得碩士、Executive PGP 或高級證書課程以加快您的職業生涯。
閱讀:機器學習項目理念
目錄
要記住的術語
在我們深入研究算法之前,這裡有一些重要的術語,你們都應該知道。

- 根節點:它是分裂開始的最頂層節點。
- 拆分:將單個節點細分為多個子節點的過程。
- 終端節點或葉節點:不進一步分裂的節點稱為終端節點。
- 剪枝:去除子節點的過程。
- 父節點:進一步拆分為子節點的節點。
- 子節點:從父節點出來的子節點。
它是如何工作的?
決策樹將數據集分解為更小的子集。 一個決策葉分為兩個或多個分支,代表被檢查屬性的值。 決策樹中最頂層的節點是最好的預測器,稱為根節點。 ID3 是構建決策樹的算法。
它採用自上而下的方法,並根據標準偏差進行拆分。 只是為了快速修訂,標準偏差是一組數據點與其平均值的分佈或分散程度。 它量化了數據分佈的整體可變性。
離散度或變異性的值越高,意味著標準偏差越大,表明數據點與平均值的距離越大。 我們使用標準偏差來衡量樣品的均勻性。 如果樣本是完全同質的,則其標準偏差為零。
同樣,異質性程度越高,標準差越大。 計算標準偏差需要樣本均值和样本數。 我們使用了一個數學函數——偏差係數,它決定何時停止分裂。它是通過將標準偏差除以所有樣本的平均值來計算的。
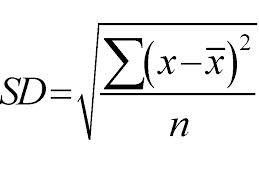
資源
最終值將是葉節點的平均值。 例如,假設 11 月是在 11 月(直到 2020 年)進一步劃分為多年來各種工資的節點。 對於 2021 年,11 月份的工資將是節點 11 月下所有工資的平均值。
繼續討論兩個類或屬性的標準差(就像上面的例子,工資可以基於每小時或每月)。 公式如下所示:
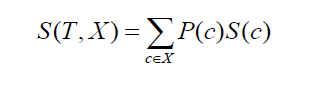
資源
其中P(c)是屬性c出現的概率,S(c)是屬性c對應的標準差。 降低標準差的方法是基於數據集拆分後標準差的降低。
為了構建一個準確的決策樹,目標應該是找到在計算時返回的屬性,並返回最大的標準差減少。 簡而言之,最同質的分支。

為回歸創建決策樹的過程包括四個重要步驟。
1.首先,我們計算目標變量的標準差。 像前面的例子一樣,考慮目標變量是薪水。 有了這個例子,我們將計算一組工資值的標準差。
2.在步驟2中,數據集被進一步拆分為不同的屬性。 談到屬性,由於目標值是薪水,我們可以認為可能的屬性是——月、小時、老闆的心情、職務、在公司的年份等等。 然後,使用上述公式計算每個分支的標準偏差。 從拆分前的標準偏差中減去如此獲得的標準偏差。 手頭的結果稱為標準偏差減少。
3. 一旦如上一步所述計算出差異,最佳屬性是標準差減少值最大的屬性。 也就是說,拆分前的標準差應該大於拆分前的標準差。 實際上,採用了差異的模式,因此反之亦然。
4.根據所選屬性的重要性對整個數據集進行分類。 在非葉分支上,遞歸地繼續該方法,直到處理完所有可用數據。 現在考慮根據標準差減少值選擇月份作為最佳拆分屬性。 因此,我們每個月將有 12 個分支機構。 這些分支將進一步拆分以從剩餘的屬性集中選擇最佳屬性。
5. 實際上,我們需要一些整理標準。 為此,我們對變得小於某個閾值(如 10%)的分支使用偏差係數或 CV。 當我們達到這個標準時,我們停止了樹的構建過程。 因為沒有發生進一步的分裂,所以屬於該屬性的值將是該節點下所有值的平均值。
執行
決策樹回歸可以使用 Python 語言和 scikit-learn 庫來實現。 它可以在 sklearn.tree.DecisionTreeRegressor 下找到。
一些重要的參數如下:
- 標準:衡量拆分的質量。 它的值可以是“mse”或均方誤差、“friedman_mse”和“mae”或平均絕對誤差。 默認值為 mse。
- max_depth:表示樹的最大深度。 默認值為無。
- max_features:它表示在決定最佳分割時要尋找的特徵數量。 默認值為無。
- splitter:此參數用於選擇每個節點的拆分。 可用值是“最佳”和“隨機”。 默認值是最好的。
查看:機器學習面試問題
sklearn 文檔中的示例
>>> 從sklearn.datasets導入load_diabetes
>>> 從sklearn.model_selection導入cross_val_score
>>> 從sklearn.tree導入DecisionTreeRegressor
>>> X, y = load_diabetes(return_X_y= True )
>>>回歸器 = DecisionTreeRegressor(random_state=0)
>>> cross_val_score(regressor, X, y, cv=10)
… # 文檔測試:+SKIP
…
數組([-0.39…, -0.46…, 0.02…, 0.06…, -0.50…,
0.16…, 0.11…, -0.73…, -0.30…, -0.00…])
接下來是什麼?
此外,如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和 AI 執行 PG 計劃,該計劃專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業,IIIT-B 校友身份,5 個以上實用的實踐頂點項目和頂級公司的工作協助。