
Funkcjonalność regresji drzewa decyzyjnego, warunki, implementacja [z przykładem]
Opublikowany: 2020-12-24Po pierwsze, model regresji to model, który daje jako wynik wartość liczbową po podaniu pewnych wartości wejściowych, które są również liczbowe. Różni się to od tego, co robi model klasyfikacji. Klasyfikuje dane testowe na różne klasy lub grupy zaangażowane w dany problem.
Wielkość grupy może wynosić od 2 do 1000 lub więcej. Istnieją modele regresji wielorakiej, takie jak regresja liniowa, regresja wielowymiarowa, regresja grzbietowa, regresja logistyczna i wiele innych. Modele regresji drzew decyzyjnych również należą do tej puli modeli regresji.
Model predykcyjny klasyfikuje lub przewiduje wartość liczbową, która wykorzystuje reguły binarne do określenia wartości wyjściowej lub docelowej. Model drzewa decyzyjnego, jak sama nazwa wskazuje, jest modelem podobnym do drzewa, który ma liście, gałęzie i węzły.
Ucz się online kursu uczenia maszynowego z najlepszych uniwersytetów na świecie. Zdobywaj programy Masters, Executive PGP lub Advanced Certificate Programy, aby przyspieszyć swoją karierę.
Przeczytaj: Pomysły na projekty uczenia maszynowego
Spis treści
Terminologie do zapamiętania
Zanim zagłębimy się w algorytm, oto kilka ważnych terminologii, o których wszyscy powinniście wiedzieć.

- Węzeł główny: jest to najwyższy węzeł, od którego zaczyna się podział.
- Podział: Proces dzielenia pojedynczego węzła na wiele podwęzłów.
- Węzeł końcowy lub węzeł liścia: węzły, które nie są dalej dzielone, nazywane są węzłami końcowymi.
- Przycinanie: Proces usuwania podwęzłów .
- Węzeł nadrzędny: węzeł, który dzieli się dalej na podwęzły.
- Węzeł potomny: podwęzły, które wyłoniły się z węzła nadrzędnego.
Jak to działa?
Drzewo decyzyjne dzieli zbiór danych na mniejsze podzbiory. Liść decyzyjny dzieli się na dwie lub więcej gałęzi, które reprezentują wartość badanego atrybutu. Najwyższy węzeł w drzewie decyzyjnym jest najlepszym predyktorem zwanym węzłem głównym. ID3 to algorytm budujący drzewo decyzyjne.
Stosuje podejście od góry do dołu, a podziały są dokonywane na podstawie odchylenia standardowego. Tylko dla szybkiej korekty, Odchylenie standardowe to stopień rozkładu lub rozproszenia zestawu punktów danych od jego średniej wartości. Określa ilościowo ogólną zmienność dystrybucji danych.
Wyższa wartość dyspersji lub zmienności oznacza, że większe jest odchylenie standardowe wskazujące na większy rozrzut punktów danych od wartości średniej. Do pomiaru jednorodności próbki używamy odchylenia standardowego. Jeśli próbka jest całkowicie jednorodna, jej odchylenie standardowe wynosi zero.
I podobnie, im wyższy stopień niejednorodności, tym większe będzie odchylenie standardowe. Średnia próbki i liczba próbek są wymagane do obliczenia odchylenia standardowego. Używamy funkcji matematycznej — Współczynnik odchylenia, który decyduje, kiedy podział powinien się zatrzymać. Oblicza się go dzieląc odchylenie standardowe przez średnią wszystkich próbek.
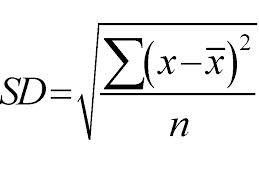
Źródło
Ostateczna wartość byłaby średnią węzłów liści. Powiedzmy na przykład, czy miesiąc listopad jest węzłem, który dzieli się dalej na różne pensje na przestrzeni lat w miesiącu listopadzie (do 2020 r.). Na rok 2021 wynagrodzenie za miesiąc listopad byłoby średnią wszystkich wynagrodzeń w węźle listopad.
Przechodząc do odchylenia standardowego dwóch klas lub atrybutów (jak w powyższym przykładzie, wynagrodzenie może być oparte na stawce godzinowej lub miesięcznej). Formuła wyglądałaby następująco:
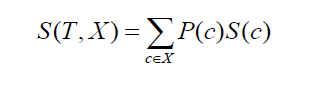
Źródło
gdzie P(c) jest prawdopodobieństwem wystąpienia atrybutu c, S(c) jest odpowiednim odchyleniem standardowym atrybutu c. Metoda redukcji odchylenia standardowego opiera się na zmniejszeniu odchylenia standardowego po podzieleniu zbioru danych.
Aby skonstruować dokładne drzewo decyzyjne, celem powinno być znalezienie atrybutów, które zwracają się po obliczeniach i zwracają najwyższą redukcję odchylenia standardowego. W prostych słowach najbardziej jednorodne gałęzie.

Proces tworzenia drzewa decyzyjnego dla regresji obejmuje cztery ważne kroki.
1. Najpierw obliczamy odchylenie standardowe zmiennej docelowej. Rozważ zmienną docelową jako wynagrodzenie, jak w poprzednich przykładach. Mając taki przykład, obliczymy odchylenie standardowe zbioru wartości wynagrodzeń.
2. W kroku 2 zestaw danych jest dalej dzielony na różne atrybuty. Mówiąc o atrybutach, ponieważ wartością docelową jest wynagrodzenie, możemy myśleć o możliwych atrybutach jako — miesiącach, godzinach, nastroju szefa, nominacji, roku w firmie i tak dalej. Następnie z powyższego wzoru obliczane jest odchylenie standardowe dla każdej gałęzi. otrzymane w ten sposób odchylenie standardowe jest odejmowane od odchylenia standardowego przed podziałem. Otrzymany wynik nazywa się redukcją odchylenia standardowego.
3. Po obliczeniu różnicy, jak wspomniano w poprzednim kroku, najlepszym atrybutem jest ten, dla którego wartość redukcji odchylenia standardowego jest największa. Oznacza to, że odchylenie standardowe przed podziałem powinno być większe niż odchylenie standardowe przed podziałem. Właściwie bierze się modyfikację różnicy, więc odwrotnie jest również możliwe.
4. Cały zbiór danych jest klasyfikowany na podstawie ważności wybranego atrybutu. Na gałęziach innych niż liściaste metoda ta jest kontynuowana rekurencyjnie do momentu przetworzenia wszystkich dostępnych danych. Rozważmy teraz, że jako najlepszy atrybut podziału wybrano miesiąc na podstawie wartości redukcji odchylenia standardowego. Czyli będziemy mieć 12 oddziałów na każdy miesiąc. Te gałęzie zostaną dalej podzielone, aby wybrać najlepszy atrybut z pozostałego zestawu atrybutów.
5. W rzeczywistości wymagamy pewnych kryteriów wykończenia. W tym celu wykorzystujemy współczynnik odchylenia lub CV dla gałęzi, która staje się mniejsza niż pewien próg, np. 10%. Kiedy osiągamy to kryterium, zatrzymujemy proces budowy drzewka. Ponieważ nie ma dalszego podziału, wartość należąca do tego atrybutu będzie średnią wszystkich wartości w tym węźle.
Realizacja
Regresję drzewa decyzyjnego można zaimplementować przy użyciu języka Python i biblioteki scikit-learn. Można go znaleźć pod adresem sklearn.tree.DecisionTreeRegressor.
Niektóre z ważnych parametrów to:
- kryterium: Mierzenie jakości podziału. Jego wartością może być „mse” lub średni błąd kwadratowy, „friedman_mse” i „mae” lub średni błąd bezwzględny. Wartość domyślna to mse.
- max_depth: reprezentuje maksymalną głębokość drzewa. Wartość domyślna to Brak.
- max_features: reprezentuje liczbę funkcji, których należy szukać przy podejmowaniu decyzji o najlepszym podziale. Wartość domyślna to Brak.
- splitter: Ten parametr służy do wyboru podziału w każdym węźle. Dostępne wartości to „najlepsza” i „losowa”. Najlepsza jest wartość domyślna.
Sprawdź: Pytania do rozmowy kwalifikacyjnej na temat uczenia maszynowego
Przykład z dokumentacji sklearn
>>> ze sklearn.datasets importuj load_diabetes
>>> ze sklearn.model_selection import cross_val_score
>>> ze sklearn.tree import DecisionTreeRegressor
>>> X, y = load_cukrzyca(return_X_y= True )
>>> regresor = DecisionTreeRegressor(losowy_stan=0)
>>> cross_val_score(regresor, X, y, cv=10)
… # doctest: +POMIŃ
…
tablica([-0,39…, -0,46…, 0,02…, 0,06…, -0,50…,
0,16…, 0,11…, -0,73…, -0,30…, -0,00…])
Co następne?
Ponadto, jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź program PG dla kadry kierowniczej IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań , status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.