
ฟังก์ชั่น Decision Tree Regression, เงื่อนไข, การนำไปใช้ [พร้อมตัวอย่าง]
เผยแพร่แล้ว: 2020-12-24ในการเริ่มต้น ตัวแบบการถดถอยคือโมเดลที่ให้ผลลัพธ์เป็นค่าตัวเลขเมื่อได้รับค่าอินพุตที่เป็นตัวเลขเช่นกัน สิ่งนี้แตกต่างจากสิ่งที่โมเดลการจำแนกประเภททำ มันจัดประเภทข้อมูลการทดสอบออกเป็นคลาสหรือกลุ่มต่าง ๆ ที่เกี่ยวข้องกับคำสั่งปัญหาที่กำหนด
ขนาดของกลุ่มอาจมีขนาดเล็กถึง 2 และใหญ่ถึง 1,000 หรือมากกว่า มีตัวแบบการถดถอยหลายแบบ เช่น การถดถอยเชิงเส้น การถดถอยหลายตัวแปร การถดถอยริดจ์ การถดถอยโลจิสติก และอื่นๆ อีกมากมาย ตัวแบบการถดถอยแบบทรีการตัดสินใจยังอยู่ในกลุ่มของตัวแบบการถดถอยนี้ด้วย
แบบจำลองการคาดการณ์จะจัดประเภทหรือทำนายค่าตัวเลขที่ใช้กฎไบนารีเพื่อกำหนดผลลัพธ์หรือค่าเป้าหมาย โมเดลต้นไม้ตัดสินใจ ตามชื่อคือแบบจำลองที่มีใบไม้ กิ่งก้าน และโหนด
เรียน รู้หลักสูตรการเรียนรู้ด้วยเครื่องออนไลน์ จากมหาวิทยาลัยชั้นนำของโลก รับ Masters, Executive PGP หรือ Advanced Certificate Programs เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
อ่าน: แนวคิดโครงการการเรียนรู้ของเครื่อง
สารบัญ
คำศัพท์ที่ต้องจำ
ก่อนที่เราจะเจาะลึกลงไปในอัลกอริทึม ต่อไปนี้คือคำศัพท์สำคัญบางคำที่ทุกคนควรทราบ

- โหนดรูท: เป็นโหนดบนสุดจากจุดเริ่มต้นของการแยก
- การแยกย่อย: กระบวนการแบ่งย่อยโหนดเดียวออกเป็นโหนดย่อยหลายโหนด
- โหนดปลายทางหรือโหนดปลายสุด: โหนดที่ไม่แยกเพิ่มเติมเรียกว่าโหนดปลายทาง
- การตัดแต่งกิ่ง: กระบวนการลบโหนดย่อย
- โหนดหลัก: โหนดที่แยกออกเป็นโหนดย่อยเพิ่มเติม
- โหนดย่อย: โหนดย่อยที่โผล่ออกมาจากโหนดหลัก
มันทำงานอย่างไร?
โครงสร้างการตัดสินใจจะแบ่งชุดข้อมูลออกเป็นชุดย่อยที่เล็กกว่า ใบตัดสินใจแบ่งออกเป็นสองสาขาขึ้นไปซึ่งแสดงถึงค่าของแอตทริบิวต์ที่อยู่ระหว่างการตรวจสอบ โหนดบนสุดในแผนผังการตัดสินใจเป็นตัวทำนายที่ดีที่สุดที่เรียกว่าโหนดรูท ID3 คืออัลกอริธึมที่สร้างโครงสร้างการตัดสินใจ
มันใช้วิธีจากบนลงล่างและแยกตามค่าเบี่ยงเบนมาตรฐาน สำหรับการแก้ไขอย่างรวดเร็ว ค่าเบี่ยงเบนมาตรฐานคือระดับการกระจายหรือการกระจายชุดของจุดข้อมูลจากค่าเฉลี่ย มันวัดความแปรปรวนโดยรวมของการกระจายข้อมูล
ค่าการกระจายหรือความแปรปรวนที่สูงกว่าหมายถึงค่าเบี่ยงเบนมาตรฐานที่มากกว่าซึ่งบ่งชี้ถึงการแพร่กระจายที่มากขึ้นของจุดข้อมูลจากค่าเฉลี่ย เราใช้ค่าเบี่ยงเบนมาตรฐานในการวัดความสม่ำเสมอของตัวอย่าง ถ้าตัวอย่างเป็นเนื้อเดียวกันทั้งหมด ส่วนเบี่ยงเบนมาตรฐานจะเป็นศูนย์
และในทำนองเดียวกัน ระดับของความแตกต่างจะสูงกว่า ส่วนเบี่ยงเบนมาตรฐานก็จะมากขึ้น ต้องใช้ค่าเฉลี่ยของกลุ่มตัวอย่างและจำนวนตัวอย่างในการคำนวณค่าเบี่ยงเบนมาตรฐาน เราใช้ฟังก์ชันทางคณิตศาสตร์ — ค่าสัมประสิทธิ์ความเบี่ยงเบนที่กำหนดว่าเมื่อใดควรหยุดการแยก คำนวณโดยการหารค่าเบี่ยงเบนมาตรฐานด้วยค่าเฉลี่ยของกลุ่มตัวอย่างทั้งหมด
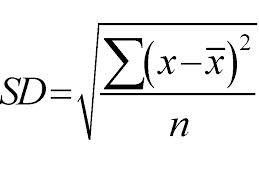
แหล่งที่มา
ค่าสุดท้ายจะเป็นค่าเฉลี่ยของโหนดปลายสุด สมมติว่าเดือนพฤศจิกายนเป็นโหนดที่แยกเงินเดือนออกไปในช่วงหลายปีที่ผ่านมาในเดือนพฤศจิกายน (จนถึงปี 2020) สำหรับปี 2564 เงินเดือนในเดือนพฤศจิกายนจะเป็นค่าเฉลี่ยของเงินเดือนทั้งหมดภายใต้โหนดพฤศจิกายน
ย้ายไปยังค่าเบี่ยงเบนมาตรฐานของสองคลาสหรือแอตทริบิวต์ (เช่นในตัวอย่างข้างต้น เงินเดือนอาจเป็นแบบรายชั่วโมงหรือรายเดือน) สูตรจะมีลักษณะดังนี้:
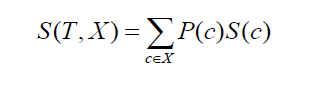
แหล่งที่มา
โดยที่ P(c) คือความน่าจะเป็นของการเกิดแอตทริบิวต์ c, S(c) คือค่าเบี่ยงเบนมาตรฐานที่สอดคล้องกันของแอตทริบิวต์ c วิธีการลดค่าเบี่ยงเบนมาตรฐานขึ้นอยู่กับค่าเบี่ยงเบนมาตรฐานที่ลดลงหลังจากชุดข้อมูลแยกออก
ในการสร้างโครงสร้างการตัดสินใจที่แม่นยำ เป้าหมายควรเป็นการค้นหาคุณลักษณะที่ส่งคืนเมื่อคำนวณ และส่งกลับค่าเบี่ยงเบนมาตรฐานสูงสุดที่ลดลง พูดง่ายๆ คือ กิ่งก้านที่เป็นเนื้อเดียวกันมากที่สุด

กระบวนการสร้างแผนผังการตัดสินใจสำหรับการถดถอยครอบคลุมสี่ขั้นตอนที่สำคัญ
1. ประการแรก เราคำนวณค่าเบี่ยงเบนมาตรฐานของตัวแปรเป้าหมาย พิจารณาตัวแปรเป้าหมายเป็นเงินเดือนตามตัวอย่างที่แล้ว จากตัวอย่าง เราจะคำนวณค่าเบี่ยงเบนมาตรฐานของชุดค่าเงินเดือน
2. ในขั้นตอนที่ 2 ชุดข้อมูลจะถูกแยกออกเป็นแอตทริบิวต์ต่างๆ พูดถึงคุณลักษณะ เนื่องจากค่าเป้าหมายคือเงินเดือน เราสามารถนึกถึงคุณลักษณะที่เป็นไปได้ เช่น เดือน ชั่วโมง อารมณ์ของเจ้านาย การแต่งตั้ง ปีในบริษัท และอื่นๆ จากนั้น ค่าเบี่ยงเบนมาตรฐานสำหรับแต่ละสาขาจะคำนวณโดยใช้สูตรข้างต้น ส่วนเบี่ยงเบนมาตรฐานที่ได้นั้นจะถูกลบออกจากค่าเบี่ยงเบนมาตรฐานก่อนการแยก ผลลัพธ์ที่ได้เรียกว่าการลดค่าเบี่ยงเบนมาตรฐาน
3. เมื่อคำนวณส่วนต่างตามที่กล่าวไว้ในขั้นตอนก่อนหน้านี้ คุณลักษณะที่ดีที่สุดคือแอตทริบิวต์ที่ค่าการลดค่าเบี่ยงเบนมาตรฐานมีค่ามากที่สุด นั่นหมายความว่า ค่าเบี่ยงเบนมาตรฐานก่อนการแยกควรมากกว่าค่าเบี่ยงเบนมาตรฐานก่อนการแยก อันที่จริงแล้ว mod ของความแตกต่างนั้นถูกนำมาใช้และในทางกลับกันก็เป็นไปได้เช่นกัน
4. ชุดข้อมูลทั้งหมดจัดประเภทตามความสำคัญของแอตทริบิวต์ที่เลือก สำหรับกิ่งที่ไม่ใช่ใบ วิธีการนี้จะดำเนินการแบบวนซ้ำจนกว่าข้อมูลที่มีอยู่ทั้งหมดจะได้รับการประมวลผล ตอนนี้ให้พิจารณาว่าเดือนถูกเลือกเป็นแอตทริบิวต์การแยกที่ดีที่สุดตามค่าการลดส่วนเบี่ยงเบนมาตรฐาน ดังนั้นเราจะมี 12 สาขาในแต่ละเดือน สาขาเหล่านี้จะแยกออกเพื่อเลือกแอตทริบิวต์ที่ดีที่สุดจากชุดแอตทริบิวต์ที่เหลืออยู่
5. ในความเป็นจริง เราต้องการเกณฑ์การตกแต่งบางอย่าง สำหรับสิ่งนี้ เราใช้สัมประสิทธิ์การเบี่ยงเบนหรือ CV สำหรับสาขาที่เล็กกว่าเกณฑ์บางอย่างเช่น 10% เมื่อเราบรรลุเกณฑ์นี้ เราจะหยุดกระบวนการสร้างต้นไม้ เนื่องจากไม่มีการแบ่งแยกเพิ่มเติม ค่าที่อยู่ภายใต้แอตทริบิวต์นี้จะเป็นค่าเฉลี่ยของค่าทั้งหมดภายใต้โหนดนั้น
การดำเนินการ
Decision Tree Regression สามารถทำได้โดยใช้ภาษา Python และไลบรารี scikit-learn สามารถพบได้ภายใต้ sklearn.tree.DecisionTreeRegressor
พารามิเตอร์ที่สำคัญบางประการมีดังนี้:
- เกณฑ์: เพื่อวัดคุณภาพของการแยก ค่าอาจเป็น "mse" หรือค่าคลาดเคลื่อนกำลังสองเฉลี่ย "friedman_mse" และ "mae" หรือค่าคลาดเคลื่อนสัมบูรณ์เฉลี่ย ค่าเริ่มต้นคือ mse
- max_depth: แสดงถึงความลึกสูงสุดของต้นไม้ ค่าเริ่มต้นคือไม่มี
- max_features: แสดงถึงจำนวนคุณสมบัติที่จะมองหาเมื่อตัดสินใจแยกส่วนที่ดีที่สุด ค่าเริ่มต้นคือไม่มี
- splitter: พารามิเตอร์นี้ใช้เพื่อเลือกการแยกที่แต่ละโหนด ค่าที่ใช้ได้คือ "ดีที่สุด" และ "สุ่ม" ค่าเริ่มต้นจะดีที่สุด
เช็คเอาท์: คำถามสัมภาษณ์เกี่ยวกับการเรียนรู้ของเครื่อง
ตัวอย่างจากเอกสาร sklearn
>>> จาก sklearn.datasets นำเข้า load_diabetes
>>> จาก sklearn.model_selection นำเข้า cross_val_score
>>> จาก sklearn.tree นำเข้า DecisionTreeRegressor
>>> X, y = load_diabetes(return_X_y= True )
>>> regressor = DecisionTreeRegressor (สุ่มสถานะ = 0)
>>> cross_val_score(ถอยหลัง, X, y, cv=10)
… # doctest: +SKIP
…
อาร์เรย์([-0.39…, -0.46…, 0.02…, 0.06…, -0.50…,
0.16…, 0.11…, -0.73…, -0.30…, -0.00…])
อะไรต่อไป?
นอกจากนี้ หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's Executive PG Program ใน Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมอย่างเข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ , สถานะศิษย์เก่า IIIT-B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ