
Funzionalità di regressione dell'albero decisionale, termini, implementazione [con esempio]
Pubblicato: 2020-12-24Per cominciare, un modello di regressione è un modello che fornisce come output un valore numerico quando vengono forniti alcuni valori di input che sono anche numerici. Questo è diverso da ciò che fa un modello di classificazione. Classifica i dati del test in varie classi o gruppi coinvolti in una determinata affermazione del problema.
La dimensione del gruppo può essere piccola come 2 e grande come 1000 o più. Esistono più modelli di regressione come regressione lineare, regressione multivariata, regressione di cresta, regressione logistica e molti altri. Anche i modelli di regressione dell'albero decisionale appartengono a questo pool di modelli di regressione.
Il modello predittivo classificherà o prevederà un valore numerico che utilizza regole binarie per determinare l'output o il valore target. Il modello dell'albero decisionale, come suggerisce il nome, è un modello simile ad un albero che ha foglie, rami e nodi.
Impara il corso online di Machine Learning dalle migliori università del mondo. Guadagna master, Executive PGP o programmi di certificazione avanzati per accelerare la tua carriera.
Leggi: Idee per progetti di apprendimento automatico
Sommario
Terminologie da ricordare
Prima di approfondire l'algoritmo, ecco alcune terminologie importanti di cui tutti dovreste essere a conoscenza.

- Nodo radice: è il nodo più in alto da dove inizia la divisione.
- Divisione: processo di suddivisione di un singolo nodo in più sottonodi.
- Nodo terminale o nodo foglia: i nodi che non si dividono ulteriormente sono chiamati nodi terminali.
- Potatura: il processo di rimozione dei nodi secondari.
- Nodo padre: il nodo che si divide ulteriormente in nodi secondari.
- Nodo figlio: i nodi secondari che sono emersi dal nodo padre.
Come funziona?
L'albero decisionale suddivide il set di dati in sottoinsiemi più piccoli. Una foglia decisionale si divide in due o più rami che rappresentano il valore dell'attributo in esame. Il nodo più in alto nell'albero decisionale è il miglior predittore chiamato nodo radice. ID3 è l'algoritmo che costruisce l'albero decisionale.
Impiega un approccio dall'alto verso il basso e le divisioni vengono effettuate in base alla deviazione standard. Solo per una rapida revisione, la deviazione standard è il grado di distribuzione o dispersione di un insieme di punti dati dal suo valore medio. Quantifica la variabilità complessiva della distribuzione dei dati.
Un valore maggiore di dispersione o variabilità significa maggiore è la deviazione standard che indica la maggiore diffusione dei punti dati dal valore medio. Usiamo la deviazione standard per misurare l'uniformità del campione. Se il campione è totalmente omogeneo, la sua deviazione standard è zero.
Allo stesso modo, maggiore è il grado di eterogeneità, maggiore sarà la deviazione standard. La media del campione e il numero di campioni sono necessari per calcolare la deviazione standard. Usiamo una funzione matematica — Coefficiente di deviazione che decide quando la divisione deve interrompersi Viene calcolata dividendo la deviazione standard per la media di tutti i campioni.
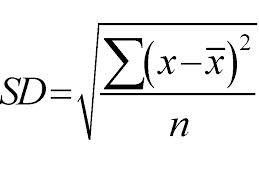
Fonte
Il valore finale sarebbe la media dei nodi foglia. Diciamo, ad esempio, se il mese di novembre è il nodo che si divide ulteriormente in vari stipendi nel corso degli anni nel mese di novembre (fino al 2020). Per l'anno 2021, lo stipendio per il mese di novembre sarebbe la media di tutti gli stipendi sotto il nodo novembre.
Passando alla deviazione standard di due classi o attributi (come per l'esempio sopra, lo stipendio può essere basato su base oraria o mensile). La formula sarebbe simile alla seguente:
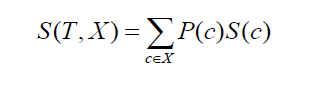
Fonte
dove P(c) è la probabilità di occorrenza dell'attributo c, S(c) è la corrispondente deviazione standard dell'attributo c. Il metodo di riduzione della deviazione standard si basa sulla diminuzione della deviazione standard dopo la divisione di un set di dati.
Per costruire un albero decisionale accurato, l'obiettivo dovrebbe essere trovare gli attributi che restituiscono al calcolo e restituire la riduzione della deviazione standard più alta. In parole semplici, i rami più omogenei.

Il processo di creazione di un albero decisionale per la regressione copre quattro passaggi importanti.
1. In primo luogo, calcoliamo la deviazione standard della variabile target. Considera la variabile target come stipendio come negli esempi precedenti. Con l'esempio in atto, calcoleremo la deviazione standard dell'insieme dei valori salariali.
2. Nella fase 2, il set di dati viene ulteriormente suddiviso in diversi attributi. parlando di attributi, poiché il valore target è lo stipendio, possiamo pensare ai possibili attributi come: mesi, ore, stato d'animo del capo, designazione, anno in azienda e così via. Quindi, la deviazione standard per ciascun ramo viene calcolata utilizzando la formula sopra. la deviazione standard così ottenuta viene sottratta dalla deviazione standard prima dello split. Il risultato a portata di mano è chiamato riduzione della deviazione standard.
3. Una volta calcolata la differenza come indicato nel passaggio precedente, l'attributo migliore è quello per cui il valore di riduzione della deviazione standard è maggiore. Ciò significa che la deviazione standard prima della divisione dovrebbe essere maggiore della deviazione standard prima della divisione. In realtà, viene presa la mod della differenza e quindi è anche possibile viceversa.
4. L'intero set di dati viene classificato in base all'importanza dell'attributo selezionato. Sui rami non fogliari, questo metodo viene continuato ricorsivamente fino all'elaborazione di tutti i dati disponibili. Ora considera che il mese sia selezionato come il miglior attributo di suddivisione in base al valore di riduzione della deviazione standard. Quindi avremo 12 filiali per ogni mese. Questi rami si divideranno ulteriormente per selezionare l'attributo migliore dalla serie rimanente di attributi.
5. In realtà, abbiamo bisogno di alcuni criteri di finitura. Per questo, utilizziamo il coefficiente di deviazione o CV per un ramo che diventa inferiore a una certa soglia come il 10%. Quando raggiungiamo questo criterio, fermiamo il processo di costruzione dell'albero. Poiché non si verificano ulteriori divisioni, il valore che rientra in questo attributo sarà la media di tutti i valori in quel nodo.
Implementazione
Decision Tree Regression può essere implementata utilizzando il linguaggio Python e la libreria scikit-learn. Può essere trovato sotto sklearn.tree.DecisionTreeRegressor.
Alcuni dei parametri importanti sono i seguenti:
- criterio: misurare la qualità di una scissione. Il suo valore può essere "mse" o l'errore medio al quadrato, "friedman_mse" e "mae" o l'errore medio assoluto. Il valore predefinito è mse.
- max_depth: Rappresenta la profondità massima dell'albero. Il valore predefinito è Nessuno.
- max_features: rappresenta il numero di funzioni da cercare quando si decide la suddivisione migliore. Il valore predefinito è Nessuno.
- splitter: questo parametro viene utilizzato per scegliere la divisione in ciascun nodo. I valori disponibili sono "migliore" e "casuale". Il valore predefinito è il migliore.
Dai un'occhiata a: Domande sull'intervista sull'apprendimento automatico
Esempio dalla documentazione sklearn
>>> da sklearn.datasets import load_diabetes
>>> da sklearn.model_selection import cross_val_score
>>> da sklearn.tree import DecisionTreeRegressor
>>> X, y = load_diabetes(return_X_y= True )
>>> regressore = DecisionTreeRegressor(random_state=0)
>>> cross_val_score(regressore, X, y, cv=10)
… # doctest: +SALTA
…
matrice([-0.39…, -0.46…, 0.02…, 0.06…, -0.50…,
0.16…, 0.11…, -0.73…, -0.30…, -0.00…])
Cosa succede dopo?
Inoltre, se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al programma Executive PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi , status di Alumni IIIT-B, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.