
Entscheidungsbaum-Regressionsfunktion, Begriffe, Implementierung [mit Beispiel]
Veröffentlicht: 2020-12-24Zunächst einmal ist ein Regressionsmodell ein Modell, das als Ausgabe einen numerischen Wert liefert, wenn einige Eingabewerte gegeben sind, die ebenfalls numerisch sind. Dies unterscheidet sich von dem, was ein Klassifizierungsmodell tut. Es klassifiziert die Testdaten in verschiedene Klassen oder Gruppen, die an einer gegebenen Problemstellung beteiligt sind.
Die Größe der Gruppe kann so klein wie 2 und so groß wie 1000 oder mehr sein. Es gibt mehrere Regressionsmodelle wie lineare Regression, multivariate Regression, Ridge-Regression, logistische Regression und viele mehr. Auch Entscheidungsbaum-Regressionsmodelle gehören zu diesem Pool von Regressionsmodellen.
Das Vorhersagemodell wird entweder einen numerischen Wert klassifizieren oder vorhersagen, der binäre Regeln verwendet, um den Ausgabe- oder Zielwert zu bestimmen. Das Entscheidungsbaummodell ist, wie der Name schon sagt, ein baumähnliches Modell mit Blättern, Zweigen und Knoten.
Lernen Sie den Online-Kurs für maschinelles Lernen von den besten Universitäten der Welt. Erwerben Sie Master-, Executive PGP- oder Advanced Certificate-Programme, um Ihre Karriere zu beschleunigen.
Lesen Sie: Projektideen für maschinelles Lernen
Inhaltsverzeichnis
Terminologien zum Erinnern
Bevor wir uns mit dem Algorithmus befassen, hier einige wichtige Terminologien, die Sie alle kennen sollten.

- Wurzelknoten: Dies ist der oberste Knoten, von dem aus die Aufteilung beginnt.
- Splitting: Prozess der Unterteilung eines einzelnen Knotens in mehrere Unterknoten.
- Endknoten oder Blattknoten: Knoten, die sich nicht weiter teilen, werden als Endknoten bezeichnet.
- Pruning: Der Vorgang des Entfernens von Unterknoten .
- Übergeordneter Knoten: Der Knoten, der sich weiter in Unterknoten aufteilt.
- Kindknoten: Die Unterknoten, die aus dem Elternknoten hervorgegangen sind.
Wie funktioniert es?
Der Entscheidungsbaum zerlegt den Datensatz in kleinere Teilmengen. Ein Entscheidungsblatt teilt sich in zwei oder mehr Zweige auf, die den Wert des untersuchten Attributs darstellen. Der oberste Knoten im Entscheidungsbaum ist der beste Prädiktor, der Wurzelknoten genannt wird. ID3 ist der Algorithmus, der den Entscheidungsbaum aufbaut.
Es verwendet einen Top-to-Down-Ansatz und Aufteilungen werden basierend auf der Standardabweichung vorgenommen. Nur für eine schnelle Überarbeitung, die Standardabweichung ist der Grad der Verteilung oder Streuung eines Satzes von Datenpunkten von seinem Mittelwert. Es quantifiziert die Gesamtvariabilität der Datenverteilung.
Ein höherer Streuungs- oder Variabilitätswert bedeutet eine größere Standardabweichung, die die größere Streuung der Datenpunkte vom Mittelwert angibt. Wir verwenden die Standardabweichung, um die Einheitlichkeit der Probe zu messen. Wenn die Probe vollständig homogen ist, ist ihre Standardabweichung Null.
Und je höher der Grad der Heterogenität ist, desto größer wird die Standardabweichung sein. Der Mittelwert der Stichprobe und die Anzahl der Stichproben sind erforderlich, um die Standardabweichung zu berechnen. Wir verwenden eine mathematische Funktion – den Abweichungskoeffizienten, der entscheidet, wann die Teilung aufhören soll. Er wird berechnet, indem die Standardabweichung durch den Mittelwert aller Stichproben dividiert wird.
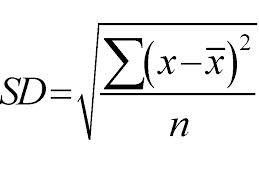
Quelle
Der Endwert wäre der Durchschnitt der Blattknoten. Angenommen, der Monat November ist der Knoten, der sich im Laufe der Jahre im Monat November (bis 2020) weiter in verschiedene Gehälter aufteilt. Für das Jahr 2021 wäre das Gehalt für den Monat November der Durchschnitt aller Gehälter unter dem Knoten November.
Fahren Sie mit der Standardabweichung von zwei Klassen oder Attributen fort (wie im obigen Beispiel kann das Gehalt entweder auf Stundenbasis oder auf Monatsbasis basieren). Die Formel würde wie folgt aussehen:
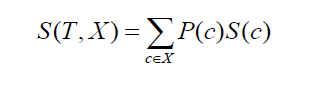
Quelle
wobei P(c) die Auftrittswahrscheinlichkeit des Attributs c ist, S(c) die entsprechende Standardabweichung des Attributs c ist. Die Methode zur Verringerung der Standardabweichung basiert auf der Verringerung der Standardabweichung nach der Aufteilung eines Datensatzes.

Um einen genauen Entscheidungsbaum zu erstellen, sollte das Ziel darin bestehen, Attribute zu finden, die bei der Berechnung zurückgegeben werden, und die höchste Reduzierung der Standardabweichung zurückgeben. Mit einfachen Worten, die homogensten Branchen.
Der Prozess der Erstellung eines Entscheidungsbaums für die Regression umfasst vier wichtige Schritte.
1. Zunächst berechnen wir die Standardabweichung der Zielgröße. Betrachten Sie die Zielvariable als Gehalt wie in den vorherigen Beispielen. Anhand des Beispiels berechnen wir die Standardabweichung des Satzes von Gehaltswerten.
2. In Schritt 2 wird der Datensatz weiter in verschiedene Attribute aufgeteilt. Wenn wir über Attribute sprechen, da der Zielwert das Gehalt ist, können wir uns die möglichen Attribute wie folgt vorstellen: Monate, Stunden, Stimmung des Chefs, Bezeichnung, Jahr im Unternehmen und so weiter. Dann wird die Standardabweichung für jeden Zweig unter Verwendung der obigen Formel berechnet. die so erhaltene Standardabweichung wird von der Standardabweichung vor der Teilung subtrahiert. Das vorliegende Ergebnis wird als Reduktion der Standardabweichung bezeichnet.
3. Nachdem die Differenz wie im vorherigen Schritt erwähnt berechnet wurde, ist das beste Attribut dasjenige, für das der Reduktionswert der Standardabweichung am größten ist. Das heißt, die Standardabweichung vor dem Split sollte größer sein als die Standardabweichung vor dem Split. Eigentlich wird mod der Unterschied genommen und so ist auch umgekehrt möglich.
4. Der gesamte Datensatz wird basierend auf der Wichtigkeit des ausgewählten Attributs klassifiziert. Auf den Nicht-Blatt-Zweigen wird dieses Verfahren rekursiv fortgesetzt, bis alle verfügbaren Daten verarbeitet sind. Betrachten Sie nun den Monat als das beste Aufteilungsattribut basierend auf dem Standardabweichungs-Reduktionswert. Wir werden also 12 Filialen für jeden Monat haben. Diese Zweige werden weiter aufgeteilt, um das beste Attribut aus dem verbleibenden Satz von Attributen auszuwählen.
5. In Wirklichkeit benötigen wir einige Veredelungskriterien. Dazu verwenden wir den Abweichungskoeffizienten oder CV für einen Zweig, der kleiner als eine bestimmte Schwelle wie 10 % wird. Wenn wir dieses Kriterium erreichen, stoppen wir den Baumbildungsprozess. Da keine weitere Aufteilung erfolgt, ist der Wert, der unter dieses Attribut fällt, der Durchschnitt aller Werte unter diesem Knoten.
Implementierung
Die Entscheidungsbaumregression kann mithilfe der Python-Sprache und der scikit-learn-Bibliothek implementiert werden. Es kann unter dem sklearn.tree.DecisionTreeRegressor gefunden werden.
Einige der wichtigen Parameter sind wie folgt:
- Kriterium: Um die Qualität einer Teilung zu messen. Sein Wert kann „mse“ oder der mittlere quadratische Fehler, „friedman_mse“ und „mae“ oder der mittlere absolute Fehler sein. Der Standardwert ist mse.
- max_depth: Repräsentiert die maximale Tiefe des Baums. Der Standardwert ist „Keine“.
- max_features: Stellt die Anzahl der Merkmale dar, nach denen bei der Entscheidung über die beste Aufteilung gesucht werden muss. Der Standardwert ist „Keine“.
- Splitter: Dieser Parameter wird verwendet, um die Aufteilung an jedem Knoten auszuwählen. Verfügbare Werte sind „best“ und „random“. Der Standardwert ist am besten.
Schauen Sie sich an: Interviewfragen für maschinelles Lernen
Beispiel aus der sklearn-Dokumentation
>>> aus sklearn.datasets import load_diabetes
>>> aus sklearn.model_selection import cross_val_score
>>> aus sklearn.tree import DecisionTreeRegressor
>>> X, y = load_diabetes(return_X_y= True )
>>> Regressor = DecisionTreeRegressor(random_state=0)
>>> cross_val_score(regressor, X, y, cv=10)
… # doctest: +ÜBERSPRINGEN
…
array([-0,39…, -0,46…, 0,02…, 0,06…, -0,50…,
0,16…, 0,11…, -0,73…, -0,30…, -0,00…])
Was als nächstes?
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich auch das Executive PG-Programm in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet , IIIT-B-Alumni-Status, mehr als 5 praktische Schlusssteinprojekte und Arbeitsunterstützung bei Top-Unternehmen.