
デシジョンツリー回帰の機能、用語、実装[例を使用]
公開: 2020-12-24そもそも、回帰モデルは、数値でもある入力値が与えられたときに出力として数値を与えるモデルです。 これは、分類モデルが行うこととは異なります。 テストデータを、特定の問題ステートメントに関係するさまざまなクラスまたはグループに分類します。
グループのサイズは、最小で2、最大で1000以上にすることができます。 線形回帰、多変量回帰、リッジ回帰、ロジスティック回帰など、複数の回帰モデルがあります。 デシジョンツリー回帰モデルも、この回帰モデルのプールに属します。
予測モデルは、バイナリルールを使用して出力値またはターゲット値を決定する数値を分類または予測します。 デシジョンツリーモデルは、その名前が示すように、リーフ、ブランチ、およびノードを持つツリーのようなモデルです。
世界のトップ大学から機械学習オンラインコースを学びましょう。 マスター、エグゼクティブPGP、または高度な証明書プログラムを取得して、キャリアを迅速に追跡します。
読む:機械学習プロジェクトのアイデア
目次
覚えておくべき用語
アルゴリズムを掘り下げる前に、皆さんが知っておくべきいくつかの重要な用語を以下に示します。

- ルートノード:分割が開始される最上位のノードです。
- 分割:単一のノードを複数のサブノードに分割するプロセス。
- ターミナルノードまたはリーフノード:それ以上分割されないノードは、ターミナルノードと呼ばれます。
- 剪定:サブノードを削除するプロセス。
- 親ノード:さらにサブノードに分割されるノード。
- 子ノード:親ノードから出現したサブノード。
それはどのように機能しますか?
デシジョンツリーは、データセットをより小さなサブセットに分割します。 決定リーフは、調査中の属性の値を表す2つ以上のブランチに分割されます。 デシジョンツリーの最上位ノードは、ルートノードと呼ばれる最良の予測子です。 ID3は、決定木を構築するアルゴリズムです。
上から下へのアプローチを採用し、標準偏差に基づいて分割が行われます。 簡単に修正するために、標準偏差は、データポイントのセットの平均値からの分布または分散の程度です。 これは、データ分布の全体的な変動性を定量化します。
分散または変動性の値が高いほど、標準偏差が大きいことを意味し、平均値からのデータポイントの広がりが大きいことを示します。 標準偏差を使用して、サンプルの均一性を測定します。 サンプルが完全に均質である場合、その標準偏差はゼロです。
同様に、不均一性の程度が高いほど、標準偏差も大きくなります。 標準偏差を計算するには、サンプルの平均とサンプルの数が必要です。 数学関数—分割をいつ停止するかを決定する変動係数を使用します。これは、標準偏差をすべてのサンプルの平均で割ることによって計算されます。
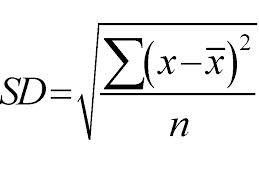
ソース
最終的な値は、リーフノードの平均になります。 たとえば、11月が、11月の年(2020年まで)のさまざまな給与にさらに分割されるノードであるとします。 2021年の場合、11月の給与は、ノード11月のすべての給与の平均になります。
2つのクラスまたは属性の標準偏差に移ります(上記の例のように、給与は時間ベースまたは月ベースのいずれかに基づくことができます)。 式は次のようになります。
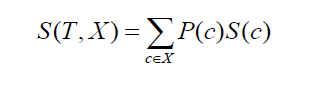
ソース
ここで、P(c)は属性cの発生確率であり、S(c)は属性cの対応する標準偏差です。 標準偏差を減らす方法は、データセットが分割された後の標準偏差の減少に基づいています。
正確な決定木を構築するための目標は、計算時に返される属性を見つけ、最高の標準偏差の減少を返すことです。 簡単に言えば、最も均質なブランチです。

回帰用の決定木を作成するプロセスは、4つの重要なステップをカバーしています。
1.まず、対象変数の標準偏差を計算します。 前の例のように、ターゲット変数を給与と見なします。 例を使用して、給与値のセットの標準偏差を計算します。
2.ステップ2で、データセットはさらに異なる属性に分割されます。 属性について言えば、目標値は給与であるため、可能な属性は、月、時間、上司の気分、指定、会社での年などと考えることができます。 次に、上記の式を使用して、各ブランチの標準偏差を計算します。 そのようにして得られた標準偏差は、分割前の標準偏差から差し引かれます。 手元の結果は、標準偏差の減少と呼ばれます。
3.前の手順で説明したように差が計算されたら、標準偏差の減少値が最大の属性が最適です。 つまり、分割前の標準偏差は、分割前の標準偏差よりも大きくなければなりません。 実際には、差のmodが取られるので、その逆も可能です。
4.データセット全体は、選択した属性の重要性に基づいて分類されます。 非リーフブランチでは、このメソッドは、使用可能なすべてのデータが処理されるまで再帰的に続行されます。 ここで、標準偏差の削減値に基づいて、月が最適な分割属性として選択されていると考えてください。 したがって、毎月12のブランチがあります。 これらのブランチはさらに分割され、残りの属性セットから最適な属性が選択されます。
5.実際には、いくつかの仕上げ基準が必要です。 このために、10%などの特定のしきい値よりも小さくなるブランチの変動係数またはCVを使用します。 この基準を達成すると、ツリー構築プロセスを停止します。 これ以上分割が行われないため、この属性に該当する値は、そのノードにあるすべての値の平均になります。
実装
ディシジョンツリー回帰は、Python言語とscikit-learnライブラリを使用して実装できます。 sklearn.tree.DecisionTreeRegressorの下にあります。
重要なパラメータのいくつかは次のとおりです。
- 基準:分割の品質を測定すること。 その値は、「mse」または平均二乗誤差、「friedman_mse」、および「mae」または平均絶対誤差にすることができます。 デフォルト値はmseです。
- max_depth:ツリーの最大深度を表します。 デフォルト値はNoneです。
- max_features:最適な分割を決定するときに探す機能の数を表します。 デフォルト値はNoneです。
- スプリッター:このパラメーターは、各ノードでの分割を選択するために使用されます。 使用可能な値は「最良」と「ランダム」です。 デフォルト値が最適です。
チェックアウト:機械学習のインタビューの質問
sklearnドキュメントの例
>>>sklearn.datasetsからload_diabetesをインポートします
>>> sklearn.model_selectionimportcross_val_scoreから_
>>> sklearn.treeからimportDecisionTreeRegressor
>>> X、y = load_diabetes(return_X_y = True )
>>> regressor = DecisionTreeRegressor(random_state = 0)
>>> cross_val_score(regressor、X、y、cv = 10)
… #doctest:+ SKIP
…
array([-0.39…、-0.46…、0.02…、0.06…、-0.50…、
0.16…、0.11…、-0.73…、-0.30…、-0.00…])
次は何?
また、機械学習について詳しく知りたい場合は、機械学習とAIのIIIT-BとupGradのエグゼクティブPGプログラムをご覧ください。このプログラムは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題を提供しています。 、IIIT-B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との雇用支援。