
Arborele de decizie Funcționalitate de regresie, termeni, implementare [cu exemplu]
Publicat: 2020-12-24Pentru început, un model de regresie este un model care dă ca ieșire o valoare numerică atunci când i se oferă niște valori de intrare care sunt, de asemenea, numerice. Acest lucru diferă de ceea ce face un model de clasificare. Clasifică datele testului în diferite clase sau grupuri implicate într-o enunțare a problemei dată.
Mărimea grupului poate fi de până la 2 și de 1000 sau mai mult. Există mai multe modele de regresie, cum ar fi regresia liniară, regresia multivariată, regresia Ridge, regresia logistică și multe altele. Modelele de regresie ale arborelui de decizie aparțin și ele acestui grup de modele de regresie.
Modelul predictiv va clasifica sau prezice o valoare numerică care utilizează reguli binare pentru a determina valoarea de ieșire sau țintă. Modelul arborelui de decizie, așa cum sugerează și numele, este un model asemănător unui arbore care are frunze, ramuri și noduri.
Învață curs online de învățare automată de la cele mai bune universități din lume. Câștigă programe de master, Executive PGP sau Advanced Certificate pentru a-ți accelera cariera.
Citiți: Idei de proiecte de învățare automată
Cuprins
Terminologii de reținut
Înainte de a ne aprofunda în algoritm, iată câteva terminologii importante pe care ar trebui să le cunoașteți cu toții.

- Nodul rădăcină: este cel mai de sus nod de unde începe divizarea.
- Divizarea: Proces de subdivizare a unui singur nod în mai multe sub-noduri.
- Nod terminal sau nod frunză: Nodurile care nu se împart mai departe sunt numite noduri terminale.
- Tunderea: procesul de eliminare a subnodurilor.
- Nod părinte: nodul care se împarte în sub-noduri.
- Nod copil: subnodurile care au apărut din nodul părinte.
Cum functioneazã?
Arborele de decizie descompune setul de date în subseturi mai mici. O foaie de decizie se împarte în două sau mai multe ramuri care reprezintă valoarea atributului examinat. Cel mai de sus nodul din arborele de decizie este cel mai bun predictor numit nodul rădăcină. ID3 este algoritmul care construiește arborele de decizie.
Utilizează o abordare de sus în jos, iar împărțirile se fac pe baza abaterii standard. Doar pentru o revizuire rapidă, Abaterea standard este gradul de distribuție sau dispersie a unui set de puncte de date față de valoarea sa medie. Cuantifică variabilitatea globală a distribuției datelor.
O valoare mai mare a dispersiei sau a variabilității înseamnă mai mare abaterea standard care indică răspândirea mai mare a punctelor de date față de valoarea medie. Folosim abaterea standard pentru a măsura uniformitatea probei. Dacă proba este complet omogenă, abaterea sa standard este zero.
Și, în mod similar, mai mare este gradul de eterogenitate, mai mare va fi abaterea standard. Media eșantionului și numărul de probe sunt necesare pentru a calcula abaterea standard. Folosim o funcție matematică — Coeficientul de abatere care decide când se va opri divizarea. Se calculează împărțind abaterea standard la media tuturor probelor.
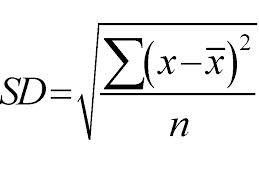
Sursă
Valoarea finală ar fi media nodurilor frunzelor. Să spunem, de exemplu, dacă luna noiembrie este nodul care se împarte în diferite salarii de-a lungul anilor în luna noiembrie (până în 2020). Pentru anul 2021, salariul pentru luna noiembrie ar fi media tuturor salariilor sub nodul noiembrie.
Trecerea la abaterea standard a două clase sau atribute (ca în exemplul de mai sus, salariul se poate baza fie pe oră, fie pe bază lunară). Formula ar arăta astfel:
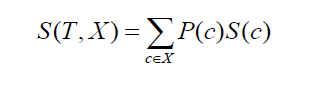
Sursă
unde P(c) este probabilitatea de apariție a atributului c, S(c) este abaterea standard corespunzătoare a atributului c. Metoda de reducere a abaterii standard se bazează pe scăderea abaterii standard după divizarea unui set de date.
Pentru a construi un arbore de decizie precis, scopul ar trebui să fie de a găsi atribute care revin la calcul și să returneze cea mai mare reducere a abaterii standard. Cu cuvinte simple, cele mai omogene ramuri.

Procesul de creare a unui arbore de decizie pentru regresie acoperă patru pași importanți.
1. În primul rând, calculăm abaterea standard a variabilei țintă. Considerați variabila țintă ca fiind salariul, ca în exemplele anterioare. Cu exemplul în vigoare, vom calcula abaterea standard a setului de valori salariale.
2. La pasul 2, setul de date este împărțit în continuare în diferite atribute. vorbind despre atribute, deoarece valoarea țintă este salariul, ne putem gândi la atributele posibile ca: luni, ore, starea de spirit a șefului, desemnarea, anul în companie și așa mai departe. Apoi, abaterea standard pentru fiecare ramură este calculată folosind formula de mai sus. abaterea standard astfel obținută este scăzută din abaterea standard înainte de împărțire. Rezultatul la îndemână se numește reducerea abaterii standard.
3. Odată ce diferența a fost calculată așa cum sa menționat în pasul anterior, cel mai bun atribut este cel pentru care valoarea reducerii abaterii standard este cea mai mare. Aceasta înseamnă că abaterea standard înainte de divizare ar trebui să fie mai mare decât abaterea standard înainte de divizare. De fapt, este luată modificarea diferenței și, deci, este posibil și invers.
4. Întregul set de date este clasificat în funcție de importanța atributului selectat. Pe ramurile non-frunze, această metodă este continuată recursiv până când toate datele disponibile sunt procesate. Acum luați în considerare luna este selectată ca cel mai bun atribut de împărțire pe baza valorii de reducere a abaterii standard. Deci vom avea 12 filiale pentru fiecare lună. Aceste ramuri se vor împărți în continuare pentru a selecta cel mai bun atribut din setul de atribute rămas.
5. În realitate, avem nevoie de anumite criterii de finisare. Pentru aceasta, folosim coeficientul de abatere sau CV pentru o ramură care devine mai mică decât un anumit prag, cum ar fi 10%. Când atingem acest criteriu, oprim procesul de construire a copacilor. Deoarece nu mai are loc nicio împărțire, valoarea care se încadrează sub acest atribut va fi media tuturor valorilor din acel nod.
Implementarea
Regresia arborelui de decizie poate fi implementată folosind limbajul Python și biblioteca scikit-learn. Acesta poate fi găsit sub sklearn.tree.DecisionTreeRegressor.
Unii dintre parametrii importanți sunt următorii:
- criteriu: Pentru a măsura calitatea unei scindări. Valoarea acesteia poate fi „mse” sau eroarea medie pătratică, „friedman_mse” și „mae” sau eroarea medie absolută. Valoarea implicită este mse.
- max_depth: Reprezintă adâncimea maximă a arborelui. Valoarea implicită este Niciuna.
- max_features: reprezintă numărul de caracteristici de căutat atunci când decideți cea mai bună împărțire. Valoarea implicită este Niciuna.
- splitter: Acest parametru este folosit pentru a alege diviziunea la fiecare nod. Valorile disponibile sunt „cele mai bune” și „aleatorie”. Valoarea implicită este cea mai bună.
Consultați: Întrebări de interviu pentru învățare automată
Exemplu din documentația sklearn
>>> din sklearn.datasets import load_diabetes
>>> din sklearn.model_selection import cross_val_score
>>> din sklearn.tree import DecisionTreeRegressor
>>> X, y = load_diabetes(return_X_y= True )
>>> regresor = DecisionTreeRegressor(random_state=0)
>>> cross_val_score(regressor, X, y, cv=10)
… # doctest: +SKIP
…
matrice([-0,39…, -0,46…, 0,02…, 0,06…, -0,50…,
0,16…, 0,11…, -0,73…, -0,30…, -0,00…])
Ce urmează?
De asemenea, dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Programul Executive PG de la IIIT-B și upGrad în Învățare automată și AI, care este conceput pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini. , statutul de absolvenți IIIT-B, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.